




随便找个图片网页https://esports.zol.com.cn/slide/688/6885385_1.html 来练手抓取和下载图片。首先要分析html代码,看下载目标的链接命名是否有规律,有规律就用regex抓取地址,再用wininet中的函数下载;然后再找出下一图集的链接,反复循环就能遍历网站的图片(如要下载其它文件类型也可以)。原理如下图所示:

源代码如下:
#include <iostream>
#include <iomanip>
#include <windows.h>
#include <wininet.h>
#include <string>
#include <regex>
#include <vector>
#include <sstream>
#include <fstream>
using namespace std;
string HttpRequest(string strUrl, string strMethod="GET", string strPostData="")
{
BOOL bRet;
short sPort=80;
char *lpHostName, *lpUrl, *lpMethod, *lpPostData;
int pos, nPostDataLen=strPostData.size();
string tmpUrl, strResponse = "";
while ((pos = strUrl.find(" ")) != strUrl.npos) strUrl.erase(pos, 1); //删除网址中的空格
if (strUrl.substr(0,7) == "http://") strUrl=strUrl.substr(7, strUrl.size()-1); //删除网址中的协议名
if (strUrl.substr(0,8) == "https://") strUrl=strUrl.substr(8, strUrl.size()-1);
if (strUrl.empty()) return strResponse;
if ((pos=strUrl.find("/")) != strUrl.npos){
tmpUrl = strUrl.substr(pos+1, strUrl.size()-1);
strUrl = strUrl.substr(0, pos);
} else tmpUrl = "/";
lpUrl = (char*)tmpUrl.data();
lpMethod = (char*)strMethod.data();
lpHostName = (char*)strUrl.data();
lpPostData = (char*)strPostData.data();
if ((pos=strUrl.find(":")) != strUrl.npos){
tmpUrl = strUrl.substr(pos+1,strUrl.size()-1);
strUrl = strUrl.substr(0,pos);
sPort = (short)atoi(tmpUrl.c_str());
}
HINTERNET hInternet, hConnect, hRequest;
hInternet = hConnect = hRequest = NULL;
hInternet = (HINSTANCE)InternetOpen("User-Agent", INTERNET_OPEN_TYPE_PRECONFIG, NULL, NULL, 0);
if (!hInternet) return strResponse;
hConnect = (HINSTANCE)InternetConnect(hInternet, lpHostName, sPort, NULL, "HTTP/1.1", INTERNET_SERVICE_HTTP, 0, 0);
if (!hConnect){
if (hInternet) InternetCloseHandle(hInternet);
return strResponse;
}
hRequest = (HINSTANCE)HttpOpenRequest(hConnect, lpMethod, lpUrl, "HTTP/1.1", NULL, NULL, INTERNET_FLAG_RELOAD, 0);
if (!hRequest){
if (hInternet) InternetCloseHandle(hInternet);
if (hConnect) InternetCloseHandle(hConnect);
return strResponse;
}
bRet = HttpSendRequest(hRequest, NULL, 0, lpPostData, nPostDataLen);
while (true){
char cReadBuffer[4096];
unsigned long lNumberOfBytesRead;
bRet = InternetReadFile(hRequest, cReadBuffer, sizeof(cReadBuffer)-1, &lNumberOfBytesRead);
if (!bRet || !lNumberOfBytesRead) break;
cReadBuffer[lNumberOfBytesRead] = 0;
strResponse = strResponse + cReadBuffer;
}
if (hRequest) InternetCloseHandle(hRequest);
if (hConnect) InternetCloseHandle(hConnect);
if (hInternet) InternetCloseHandle(hInternet);
return strResponse;
}
bool DownloadFile(string strUrl, string strFullFileName, unsigned int BUF_SIZE_KB = 1)
{
size_t pos=0;
short sPort=80;
BOOL bRet;
char *lpHostName, *lpUrl;
string tmpUrl, strResponse = "";
while ((pos = strUrl.find(" ")) != strUrl.npos) strUrl.erase(pos, 1); //删除网址中的空格
if (strUrl.substr(0,7) == "http://") strUrl=strUrl.substr(7, strUrl.size()-1); //删除网址中的协议名
if (strUrl.substr(0,8) == "https://") strUrl=strUrl.substr(8, strUrl.size()-1);
if (strUrl.empty()) return false;
if ((pos=strUrl.find("/")) != strUrl.npos){
tmpUrl = strUrl.substr(pos+1, strUrl.size()-1);
strUrl = strUrl.substr(0, pos);
} else tmpUrl = "/";
lpUrl = (char*)tmpUrl.data();
lpHostName = (char*)strUrl.data();
if ((pos=strUrl.find(":")) != strUrl.npos){
tmpUrl = strUrl.substr(pos+1,strUrl.size()-1);
strUrl = strUrl.substr(0,pos);
sPort = (short)atoi(tmpUrl.c_str());
}
HINTERNET hInternet, hConnect, hRequest;
hInternet = hConnect = hRequest = NULL;
hInternet = (HINSTANCE)InternetOpen("User-Agent", INTERNET_OPEN_TYPE_PRECONFIG, NULL, NULL, 0);
if (!hInternet) return false;
hConnect = (HINSTANCE)InternetConnect(hInternet, lpHostName, sPort, NULL, "HTTP/1.1", INTERNET_SERVICE_HTTP, 0, 0);
if (!hConnect){
if (hInternet) InternetCloseHandle(hInternet);
return false;
}
hRequest = (HINSTANCE)HttpOpenRequest(hConnect, "GET", lpUrl, "HTTP/1.1", NULL, NULL, INTERNET_FLAG_RELOAD, 0);
if (!hRequest){
if (hInternet) InternetCloseHandle(hInternet);
if (hConnect) InternetCloseHandle(hConnect);
return false;
}
bRet = HttpSendRequest(hRequest, NULL, 0, NULL, 0);
BUF_SIZE_KB = BUF_SIZE_KB==0 ? 1024 : BUF_SIZE_KB*1024;
char buf[BUF_SIZE_KB];
DWORD buf_len, buf_read;
buf_len = buf_read = BUF_SIZE_KB;
FILE *fp = fopen(strFullFileName.c_str(), "wb");
while (true) {
InternetReadFile(hRequest, buf, buf_len, &buf_read);
if(buf_read == 0) break;
fwrite(buf, 1, buf_read, fp);
}
free(buf);
fclose(fp);
if (hRequest) InternetCloseHandle(hRequest);
if (hConnect) InternetCloseHandle(hConnect);
if (hInternet) InternetCloseHandle(hInternet);
return true;
}
int regexSplit(string &str,const string str_reg,vector<string>&vect,int pos=0)
{
if (pos!=-1) pos=0; //pos=0 匹配到的位置,pos=-1匹配位置的前一字串
regex myPattern(str_reg);
sregex_token_iterator it(str.begin(),str.end(),myPattern,pos);
sregex_token_iterator end;
for(;it!=end;++it) vect.push_back(*it);
return vect.size(); //if 0 没有匹配到,else 匹配到的个数
}
string replaceAll(string &s, const string sub1, const string sub2)
{ //字符串中指定字符串sub2替换s所有的子串sub1
size_t len,pos=0;
if (s.empty()||sub1.empty()||sub2.empty()) return s;
if (s.find(sub1)==s.npos) return s; //sub1不是s的子串就退出
len=sub1.size();
while((pos=s.find(sub1,pos))!=s.npos)
s.replace(pos++,len,sub2);
return s;
}
string int2str(int i)
{
string s;
stringstream ss;
ss<<setw(5)<<setfill('0')<<i;
s=ss.str();
ss.clear();
return s;
}
int main()
{
int i=0;
bool bRet;
size_t pos;
string Html, url, reg;
vector <string> vect, vimg;
url = "https://esports.zol.com.cn/slide/688/6885385_1.html";
Html = HttpRequest(url);
cout<<"1-"<<endl;
while ((pos=Html.find("tutie"))!=string::npos){
reg="t_s1280x720(.*?).jpg"; //查找下载目标的网址装入vector
regexSplit(Html,reg,vect);
for (auto&v:vect){ //抓取在vector里的图片地址,逐个下载
replaceAll(v,"\\/","/"); //网站把图片地址每个/前都插入\字符,全部替换掉
url = "http://article-fd.zol-img.com.cn/";
bRet=DownloadFile(url+v,"D:\\Pictures\\zol"+int2str(++i)+".jpg");
//注意:D:\Pictures 文件目录是否存在,代码没作判断
if (bRet){
cout<<".";
if (i%20==0) cout<<endl;
if (i%100==0){
system("cls");
cout<<i+1<<"-"<<endl;
}
vimg.push_back(url+v); //记录下载成功的链接
if (i>=10000) return 0; //抓取满10000张退出,或者循环到网站没有下一图集标记为止
}
}
reg="<a href=\"/slide/(.*?)tutie"; //找出下一图集的地址
vect.clear();
regexSplit(Html,reg,vect);
url = vect.at(0); //格式:<a href="/slide/688/6886276_1.html" class="tutie
url = "https://esports.zol.com.cn" + url.substr(9,url.size()-23);
vect.clear();
Html = HttpRequest(url);
}
ofstream out_file("DownList.txt"); //下载成功的链接保存到文件
if (out_file){
for(auto v:vimg)
out_file << v <<endl; //输出到文件
out_file.close();
}
return 0;
}下载成果:
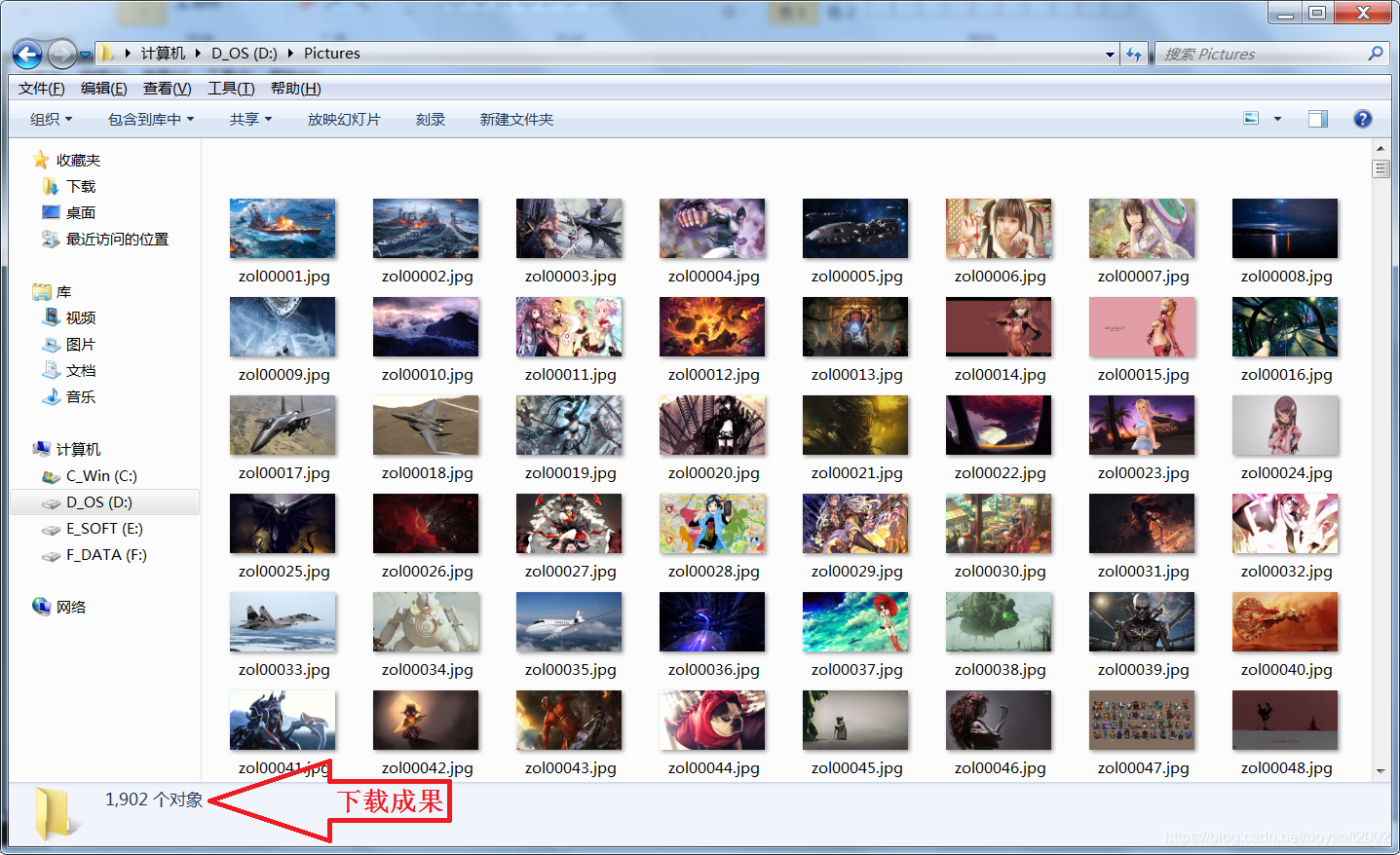
本代码在Dev-C++ 5.11上通过无错编译,20分钟左右下载到1902张图片,下载速度要看个人的电脑硬件和网络带宽的,完成后图片链接都保存到源码同文件夹里的下载清单DownList.txt中(实际上是与编译好的可执行文件同路径,没有采用边下载边记录所以中途退出是没有下载清单的)。如果用多线程技术,同时间开启多个线程下载速度会成倍加快,感兴趣的话自己去试试吧。关于多线程请看我的另一篇博文《C++ Beep()演奏简谱的改进以及实现背景音乐》。
注:本代码需要用到wininet.lib 请在工具菜单-"编译器选项"里添加如下命令:-std=c++11 -lwininet。如使用vs系列编译器或在using namespace std;之前插入:#pragma comment(lib,"WinInet.lib")


















 5035
5035

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











