



 本文详细介绍了决策树和随机森林的基本概念、模型构建、学习过程以及应用领域,着重讨论了两者之间的关系,包括随机森林如何通过集成多个决策树来提高鲁棒性和预测精度,以及各自的优缺点。
本文详细介绍了决策树和随机森林的基本概念、模型构建、学习过程以及应用领域,着重讨论了两者之间的关系,包括随机森林如何通过集成多个决策树来提高鲁棒性和预测精度,以及各自的优缺点。
目录
本文部分图片来自《老饼讲解-机器学习》
一、决策树是什么
决策树(Decision Tree)又称判定树,是一个流程图形式的树结构,其中每个中间结点代表某个属性或某组属性上的测试,每个分支则对应了该测试的不同结果,每个叶结点代表某个类别或预测结果。从训练数据中产生决策树的算法,通常被称为决策树学习算法或决策树算法。
1.1 决策树模型
决策树是一种树形结构,其中每个内部节点表示一个属性上的测试,每个分支代表一个测试输出,每个叶节点代表一种类别。如下所示,是一个决策树的模型,它由节点开始,逐个判断样本变量的条件,最后判决样本的所属类别

1.2 决策树的学习
决策树是一种监督学习,所谓监督学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,那么通过学习得到一个分类器,这个分类器能够对新出现的对象给出正确的分类。这样的机器学习就被称之为监督学习。决策树的学习过程使用信息增益或者GINI基尼系数来评估系统的凌乱程度,其中信息增益来自熵Entropy的概念。
信息增益公式如下:

GINI基尼系数公式如下:

1.3 决策树的应用
在实际应用中,决策树可用于许多不同的问题和领域,例如分类、回归、特征选择、异常检测等。此外,决策树还可以与其他算法结合使用,以构建更复杂的机器学习模型。
决策树的应用非常广泛,包括但不限于:
1.分类问题:
在决策树算法中,通过训练数据集,可以对每个样本进行分类。决策树在处理分类问题时,能够提供清晰的决策边界,同时能够解释模型决策的依据。
2.回归问题:
除了分类问题之外,决策树也可以用于回归问题。在回归问题中,决策树的每个节点代表一个特征或属性,每个分支代表一个可能的决策结果,最终的叶节点代表预测结果。
3.特征选择:
决策树在特征选择方面也很有用。通过观察决策树的分支,可以确定哪些特征对模型的贡献最大。
4.异常检测:
由于决策树可以清楚地显示决策边界,因此它们也可以用于异常检测。通过比较新的数据点与训练数据集中的数据点,可以确定新的数据点是否属于训练数据集中的正常模式。
5.人脸识别:
随着数据的不断增加和计算能力的不断提高,决策树在人脸识别等领域也将得到更广泛的应用。
6.金融风控:
在金融领域中,决策树可以用于信用评估、投资决策等方面。
7.市场营销:
在市场营销领域中,决策树可以用于客户分类、产品定价等方面。
二、随机森林是什么
随机森林是一种利用多棵树对样本进行训练并预测的一种分类器。它属于集成学习中的Bagging(并行式集成学习方法)类。随机森林的基学习器是决策树,多棵树组成了森林。在训练基学习器时,随机森林采用有放回采样的方式添加样本扰动,同时引入属性扰动。在基决策树的训练过程中,在选择划分属性时,Random Forest先从候选属性集中随机挑选出一个包含K个属性的子集,再从这个子集中选择最优划分属性。
2.1 随机森林的模型
随机森林是一种利用多棵树对样本进行训练并预测的分类器,基学习器为决策树,多棵树组成了森林。下面是一个随机森林模型,可以看到,它就是由多棵决策树构成,并且是以Bagging的方式构成
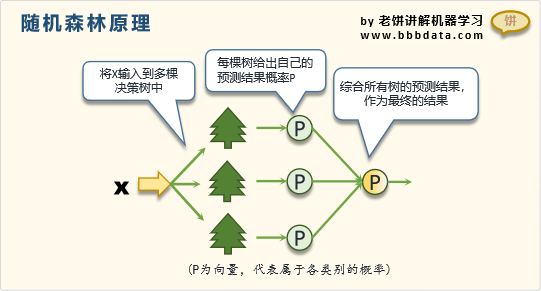
2.2 随机森林的训练
在训练基学习器时,随机森林采用有放回采样的方式添加样本扰动,同时引入了一种属性扰动,即在基决策树的训练过程中,在选择划分属性时,先从候选属性集中随机挑选出一个包含K个属性的子集,再从这个子集中选择最优划分属性。随机森林是Bagging的一个拓展体,是并行式的集成学习方法。
随机森林的训练流程如下:
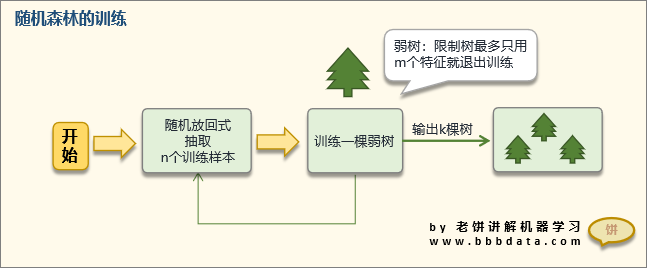
1.生成多棵决策树。在训练每棵树时,随机森林采用有放回的方式进行样本采样,即在采样得到的样本集合中,可能有重复的样本。假设输入样本为N个,那么采样的样本也为N个。这样使得在训练的时候,每一棵树的输入样本都不是全部的样本,使得相对不容易出现over-fitting。然后进行列采样,从M个feature中,选择m个(m << M)。推荐m的值为M的平方根。之后对采样之后的数据使用的方式建立出决策树,这样决策树的某一个叶子节点要么是无法继续分裂的,要么里面的所有样本的都是指向的同一个分类。
2.将多棵决策树组合起来形成随机森林。
随机森林的训练过程主要涉及到两个关键步骤:随机采样和完全分裂。
需要特别说明的是,决策树是需要预留样本进行测试的,而随机森林不需要,随机森林使用的是袋外错误率来评估模型的预测能力。
关于袋外错误率可参考:《老饼讲解|【指标】随机森林的袋外错误率》
2.3 随机森林的应用
随机森林的应用非常广泛,包括但不限于:
1.分类问题:
随机森林可以用于各种分类问题,如图像分类、文本分类和情感分析等。通过构建多棵决策树,随机森林可以对复杂的数据集进行准确的分类。
2.回归问题:
除了分类问题,随机森林也可以用于回归问题,如房价预测、股票价格预测等。通过训练多棵决策树并对结果进行平均或投票,随机森林可以提供更稳定和准确的预测。
3.特征选择:
随机森林可以用于特征选择,即从众多特征中选择最重要的特征。通过观察每棵树在分裂过程中使用的特征,可以确定哪些特征对模型的贡献最大。
4.异常检测:
随机森林可以用于异常检测,如网络入侵检测、信用卡欺诈检测等。通过比较新的数据点与训练数据集中的数据点,可以确定新的数据点是否属于训练数据集中的正常模式。
5.医学诊断:
在医学领域,随机森林可以应用于医学诊断、预测和治疗等领域。例如,通过对患者的基因、组织等信息进行分类,随机森林可以准确地识别肿瘤类型并帮助医生选择最佳的治疗方法。此外,随机森林还可以用于分析脑电图(EEG)数据,帮助医生识别各种脑电波形并诊断脑电异常。
6.金融风控:
在金融领域,随机森林可以用于信用评估、投资决策等方面。通过对历史数据进行训练,随机森林可以预测借款人的违约风险或股票的价格走势,从而为金融机构提供决策支持。
7.市场营销:
在市场营销领域,随机森林可以用于客户分类、产品定价等方面。通过对客户的购买历史、偏好等信息进行分析,随机森林可以帮助企业更好地了解客户的需求并制定更有针对性的营销策略。
总的来说,随机森林是一种强大的机器学习算法,可以应用于许多不同的问题和领域。它的优点包括能够处理大规模数据集、准确度高、能够识别无关变量等。此外,随机森林还可以与其他算法结合使用以提高性能。
三、随机林林与决策树的关系
3.1 随机林林与决策树的关系关系概述
随机森林是一种集成学习算法,它由多棵决策树组成,每棵树都从原始数据集中随机选取样本并构建而成。每棵决策树都独立地做出分类或回归预测,然后随机森林通过投票或平均值来组合每棵树的预测结果,从而产生最终的分类或回归结果。
决策树是一种树形结构的分类或回归模型,它通过递归地将数据集划分成若干个子集来构建模型。决策树的每个内部节点表示一个特征或属性,每个分支代表一个决策规则,每个叶节点表示一个类别或回归值。决策树具有直观的优点,易于理解和解释,但容易受到噪声数据和过拟合的影响。
随机森林和决策树之间的关系在于,随机森林采用了决策树作为基本模型,但通过随机选取样本和特征的方式,提高了模型的鲁棒性和泛化能力。此外,随机森林中的多棵决策树可以互相协作,使得模型能够更好地处理复杂的数据集和任务。相比单一的决策树,随机森林在分类和回归问题上通常能够获得更好的性能。
总的来说,决策树是一棵一棵的树,但随机森林是许多棵树的集合。随机森林是一个较复杂的模型,而决策树是一个较简单的模型,但从过拟合角度来说,随机森林比决策树更不易于过拟合,因为随机森林是由多棵弱决策树组成,可以更好地抵抗过拟合。
3.2随机森林与决策树的优缺点
随机森林的优点包括:
高准确性:
随机森林通常能够提供较高的预测准确性,尤其在处理复杂数据和高维数据时表现出色。
鲁棒性:由于随机森林平均了多个决策树的结果,因此对于噪声和异常值的鲁棒性较强,有助于减小过拟合的风险。
不容易过拟合:通过引入随机性,每个决策树都在不同的子集上训练,减少了过拟合的可能性。这使得随机森林在不需要额外的调参的情况下通常表现良好。
变量重要性评估:随机森林可以提供每个特征的重要性评估,这有助于理解哪些特征对于模型的贡献最大。
不需要特征缩放:由于随机森林使用的是基于树的模型,不需要进行特征缩放。这使得它在处理不同尺度的特征时更为方便。
随机森林的缺点包括:
速度较慢:
随机森林训练过程相比决策树来说需要更多的计算资源和时间,因为需要构建多棵决策树并对结果进行平均或投票。
不易解释:相比决策树来说,随机森林模型更复杂且难以解释,因为它们是由多棵决策树组成的,很难可视化或理解每棵树对最终预测的贡献。
决策树的优点包括:
简单直观:
决策树是一种直观的机器学习算法,易于理解和解释,能够清晰地展示出决策过程和规则。
对数据预处理要求较低:决策树算法不需要太多的数据预处理,例如标准化、归一化等,可以直接使用原始数据进行训练和预测。
能够处理非线性关系:决策树可以很好地处理非线性关系的数据特征,能够自动地进行特征选择和组合,从而发掘出数据中的复杂关系。
能够处理分类和数值数据:决策树可以同时处理分类和数值数据,不需要进行特征转换或离散化。
决策树的缺点包括:
容易过拟合:
决策树容易过拟合训练数据,特别是当数据集比较小或者特征数量比较多的时候。这会导致模型在测试集上的表现不佳。
对噪声敏感:如果数据集中存在噪声或者异常值,决策树的性能可能会受到影响,因为它们通常是根据少数几个样本的特性进行归纳的。
不稳定:数据集的微小变化可能导致生成完全不同的树,这使得决策树不太稳定。
写文不易,点赞收藏吧~!

















 6618
6618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









