







CV每日文献浅读
- 1003.具有周期一致性的Siamese网络的自监督对象跟踪-香港科技大学
- 1004.深度互学习DML-大连理工大学
- 1005.一种改进的深度学习结构的人物再识别-2015
- 1006.MOAT:交替移动卷积核注意力带来强大的视觉模型-2022.10
- 1007.计算机视觉物理对抗性攻击研究综述
- 1008.基于改进RepVGG网络的车道线检测算法-武汉理工硕士
- 1009.重新审视ResNets:改进的训练和扩展策略
- 1010.基于位置感知的自监督步态编码三维骨骼行人重识别方法-22年中科院
- 1011.基于一致样本挖掘的双聚类协同教学的无监督行人重识别-西安交大
- 1012.Omni-Scale Feature Learning for Person Re-Identification
- 1014.自监督学习视频理解-2021牛津大学博士论文
- 1017.目标检测究竟发展到了什么程度-CVHub
- 1018.生成模型中的合成数据是否已准备好用于图像识别?-HK,Oxford,ByteDance
- 1020.Fsat-ParC:Position Aware Global Kernel for ConvNets and ViTs
- 1025.使用完全交叉Transformer的小样本目标检测-CVPR2022
- 总结
一把子盲读,个人理解浅显,可能存在错误,偏向行人重识别领域
计算机视觉四大基本任务(分类、定位、检测、分割)
1003.具有周期一致性的Siamese网络的自监督对象跟踪-香港科技大学
摘要
自我监督学习不需要人工注释和在线训练.
在这项工作中,我们利用一个周期一致的自我监督框架中的端到端Siamese网络进行对象跟踪.
我们建议在跟踪框架中集成Siamese区域建议(region proposal)和掩码回归网络(mask regression network).
INTRODUCTION
视觉目标跟踪是许多应用程序的基本任务,such as 自动驾驶、机器人操作和视频监控.
目前方法仍受到视觉变化的影响.
基于深度网络的视觉目标跟踪方法需要地面真实的目标轨迹进行训练,费力和耗时,限制发展.
视觉跟踪任务是通过样本补丁的特征嵌入与搜索图像之间的相互关联来进行学习相似响应映射;
在相互关联之后区域建议或者掩码回归网络都有助于目标的准确预测.
在本文中利用前向跟踪和后向跟踪之间的一致性(其中的差异可以作为自我监督来训练),以周期一致的方式探索用于视觉目标跟踪的自监督学习.
交叉相关后的RPN可以估计出更准确的盒建议(box proposals).提升框架性能【视觉对象跟踪任务】Visual Object Tracking
给定视频序列的第一帧对象的分割掩码来预测所有剩余帧的分割.实际应用【视频分割传播任务】Video Object Segmentation Propagation
CONTRIBUTIONS
在循环一致框架中引入了Siamese区域建议网络和掩码回归网络模块,来实现更好的end-to-end自监督学习.
1004.深度互学习DML-大连理工大学
摘要
模型蒸馏是一种将知识从老师转移到学生网络的有效且广泛使用的技术,典型应用就是从功能强大的大型网络转移或者集成到小型网络,以满足低内存或快速执行的需求.
不同于模型蒸馏中静态预定义的教师和学生之间的单项转移,DML是学生在整个训练过程中协作学习和相互教授的集合.
我们的实验表明,简单的学生网络集合的相互学习是有效的,而且比从一个更强大但静态的教师中蒸馏出来的效果更好.
INTRODUCTION
深度神经网络在很多问题上都有非常先进的性能,但是其深度/宽度非常大,大量的参数限制他们在低内存或快速执行需求的使用.
将模型实现得紧凑而准确的方法有很多:明确的节俭架构设计(explicit frugal architecture)、模型压缩(model compression)、修剪(pruning)、二值化(binarisation)、模型蒸馏(model distillation).
基于蒸馏的模型重点在于训练(学习正确参数的难度)而不是网络size.
mutual learning是未经训练的学生直接经过两种损失函数的训练(传统的监督学习损失和模仿损失)效果明显优于alone.
简单来说就是,学生之间的相互学习达到的学习效果甚至不需要更强大教师的教授,但这些学生的学习进度或者叫方向是有差异的,这样进行相互学习才会不断累加增量学习.
根据同类发现并匹配每个训练实例的其他最可能的类,增加了每个学生的后验熵,有助于收敛到更健壮的最小值.(generalization)
小节点协同学习取得更好性能,
Futhermore:
适用于各种网络架构;
效率随队列中的网络数量增加而增加;
也有利于半监督学习;
高效的集成模型.
1005.一种改进的深度学习结构的人物再识别-2015
摘要
我们提出了一种同时学习特征的方法和相应的相似度度量的ReID
提出了一种深度卷积体系结构,其中包含专门设计用于解决再识别问题的层
包括一个计算交叉输入邻域差异的层,该层基于每个输入图像的中层特征捕获两个输入图像之间的局部关系,
该层输出的高级由补丁摘要特征层(patch summary feature)计算,然后在空间上集成到后续层.
在大中数据集测试效果都不错,还不容易在小数据集overfitting
INTRODUCTION
再识别是监视系统以及人机交互系统的一项重要能力
不同角度的视角和光线,会导致同一个人的两张照片看起来非常不同,也会导致不同人的照片看起来非常相似
我们的网络体系包括两个新层,① Cross-Input Neighborhood Differences② Patch Summary Features
计算邻域局部特征差异,随后的层负责总结差异
ARCHITECTURE
从两层带有最大池化的绑定卷积开始(学习一组用于比较两个输入图像的特征),再邻域差异层+特征总结层,最后接具有最大池化的卷积层+softmax输出的FCL
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jwvUUV6P-1664934844030)(vx_images/409373509221046.png =600x)]](https://i-blog.csdnimg.cn/blog_migrate/ad1d010a3238167f33e87826aae35f88.png)
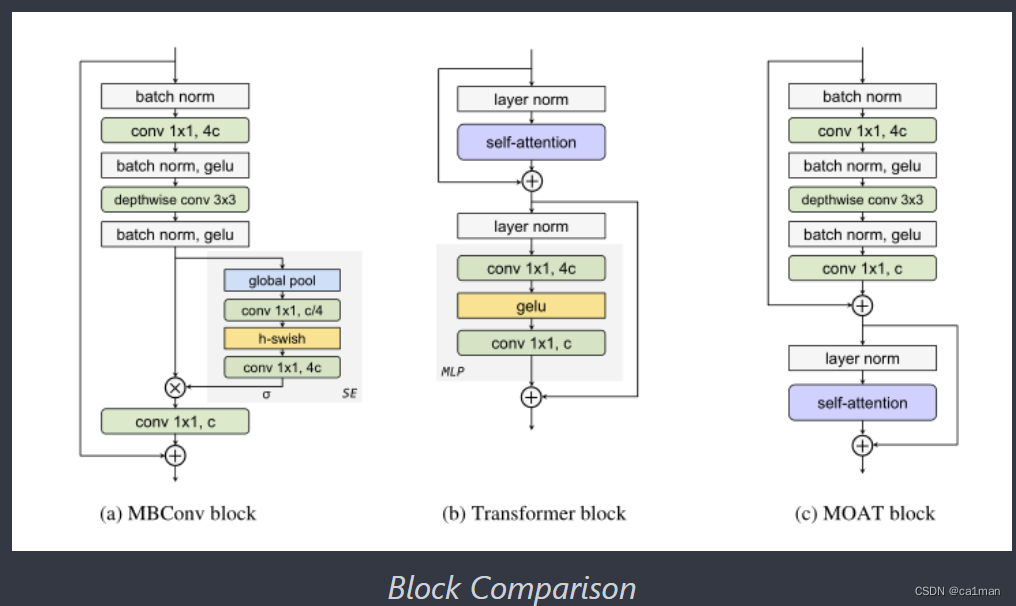
1006.MOAT:交替移动卷积核注意力带来强大的视觉模型-2022.10
MOAT: Alternating Mobile Convolution and Attention Brings Strong Vision Models
Official code in TensorFlow
摘要
本文介绍一个建立在移动卷积(即倒立残块)和注意力之上的神经网络家族.
不同于目前工作的堆叠独立的移动卷积和变压器块,
而是将他们合并到一个MOAT块中.
从一个标准的Transformer块开始,用一个移动卷积块(mobile convolution)替换了多层感知机(multi-layer perceptron),
在自注意(self-attention)操作之前对其进行重新排序(MBConv comes before self-attention).
精度在ImageNet-1k,ImageNet-22k达到了 89.1% top-1.
并且,将全局注意(global attention)转换为窗口注意(window attention),MOAT就可以应用于需要大分辨率输入的downstream tasks;
由于移动卷积的特点,MOAT还不用额外的窗口移动机制.
通过减小通道大小获得的tinyMOAT在ImageNet上优于几个基于移动设备的变压器模型.
1007.计算机视觉物理对抗性攻击研究综述
A Survey on Physical Adversarial Attack in Computer Vision
摘要
深度神经网络容易受到对抗性样本的攻击(小噪声制作的恶意样本),会误导DNNs做出错误的决定.
-
数字对抗性攻击
一般在实验室环境下,对抗攻击算法的性能. -
物理对抗性攻击
侧重攻击DNN系统,由于复杂的物理环境(如亮度、遮挡等)这是一项更具挑战性的任务,
物理对抗实例有特定的设计来克服复杂物理环境的影响
在本文中我们回顾了基于深度神经网络的计算机视觉任务中的物理对抗攻击,包括
图像识别任务、目标检测任务、语义分割
INTRODUCTION
(今天还看了一篇中南大学教授指出的第一篇科研论文常犯错误,其中提到这部分就是,“讲故事要有逻辑”,不是文献罗列,也不能过于简短)
深度神经网络广泛应用于计算机视觉、自然语言处理、语音识别等领域,比如人脸支付、自动驾驶等.
技术发展伴随着安全风险的增长:
攻击者可以通过编造恶意实例对基于深度神经网络的系统进行攻击,从而误导系统.
比如,精心设计的镜框可以绕过面部识别系统,任何戴这种眼睛的人都可以被识别为预先分配的人(哇哦还有这种攻击)
对抗实例(adversarial example),
不被人类察觉的情况下,以较小的设计噪声改变DNN-based系统的预测结果
但是最开始的研究基本都是基于数字环境下
近年来,图像识别任务、目标检测任务、语义分割等物理对抗性攻击得到不错发展,
通过对抗训练提高DNN系统的鲁棒性(robustness)
CONTRIBUTIONS
分类方案:
沿着不同的轴对物理对抗性攻击进行分类
对比:
近年来的物理对抗性攻击
可研究方向:
-
增加对抗性能
- 构建代理模型
- 对目标物体大小具有鲁棒性的对抗性扰动生成算法
-
提高可移植性(transferability)
可移植性是对抗性扰动的重要特征之一,对抗性扰动是指对已有模型产生的对抗性扰动也可以欺骗未知模型;
也有必要阐明,为什么某些对抗性扰动的可移植性差,
以及不同目标模型间可移植性的差异. -
对各种物理环境和对抗防御的鲁棒性
(复杂的物理环境带来意想不到的各种噪声信息和缺少,向来是计算机视觉任务的一大难点,自适应的泛化能力非常重要也非常具有挑战性.)
-
深度学习
一般被任务是数据驱动(data-driven)技术,
帮助机器理解大量数据中的模式,并使用学习到的潜在表示,对给定的任务进行推理. -
对抗性样本(adversarial examples)
概念最早是Szegedy等人Intriguing properties of neural networks提出的.
分类方案
静态对抗性攻击 | 动态物理攻击测试环境
targeted attacks:误导目标受害者模型输出一个预先特定的类.(比如上面提到的那个镜框吧)
non-targeted attacks:误导目标受害者模型输出原始类以外的任何类.
物理对抗实例的实现方式:
1、入侵攻击
通过hold the adversarial patch或者plane board修改目标对象,或者在目标对象上绘制对抗性伪装来修改目标对象
2、非入侵攻击
不需要攻击方修改目标对象,而是通过在目标上投射阴影或向目标发射激光来实现非侵入性物理对抗攻击
提高物理对抗攻击的技术:
1、转换异常(EOT)
约束对抗输入和干净输入之间的例外有效距离
2、NPS(Non Printability Score)(非印刷适性得分)
测量优化的对抗性扰动与普通打印(common printer)之间的颜色距离的度量
应用此约束强制对抗性样本接近预定义的可打印颜色
3、总变差范数(TV loss)
T
V
(
r
)
=
∑
i
,
j
(
(
r
i
,
j
−
r
i
+
1
,
j
)
2
+
(
r
i
,
j
−
r
i
,
j
+
1
)
2
)
1
2
TV(r)=\sum_{i,j}((r_{i,j}-r_{i+1,j})^2+(r_{i,j}-r_{i,j+1})^2)^{\frac{1}{2}}
TV(r)=i,j∑((ri,j−ri+1,j)2+(ri,j−ri,j+1)2)21
通过最小化TV®,提高摄动图像的平滑度,提高了物理可实现性
物理测试环境
没接触过相关研究,我不知道是不是翻译问题,好别扭的文字
一般过程:
首先,准备对抗性对象,例如使用彩色打印机打印对抗性贴片挂在对抗性对象上,
其次,部署传感器装置(比如RGB相机),调整相机朝向对抗性摄动对象.
根据对抗对象和传感器设备之间的差异,物理测试环境可以分为静态和动态:
- Stationary physical test
对抗对象和传感器设备同时保持静态的
比如:为了攻击自动结账系统,对手将对抗性贴片贴在商品表面进行欺骗,结账系统输出错误的价格,给商家造成损失
- Dynamic physical test
- 对抗物体固定而传感器装置运动
e.g.,无人机监视 - 对抗物体运动而传感器装置固定
e.g.,视频监视 - 对抗物体和传感器装置同时运动
e.g.,自动驾驶
- 对抗物体固定而传感器装置运动
物理对抗性攻击最重要的原则就是:全像素智慧摄动是无效的
对抗性扰动需要嵌入环境中的特定对象,如目标对象本身或情景的附属物
图像识别任务
将输入的图像分类到特定的类别中
模拟攻击(变成特定别人)
有目标攻击
躲避攻击(反正不是自己)
无目标攻击
- 镜片的攻击
- 贴纸
- 化妆(没有研究在现实世界的效果?)
- 光投影
校准投影仪与数字图像之间的对抗区域和颜色
目标检测任务
在图像中定位目标,同时给出被定位对象的类
-
Patch-based physical adversarial attack
细分好多种,看图能明白个大概:

-
可穿戴对抗性扰动
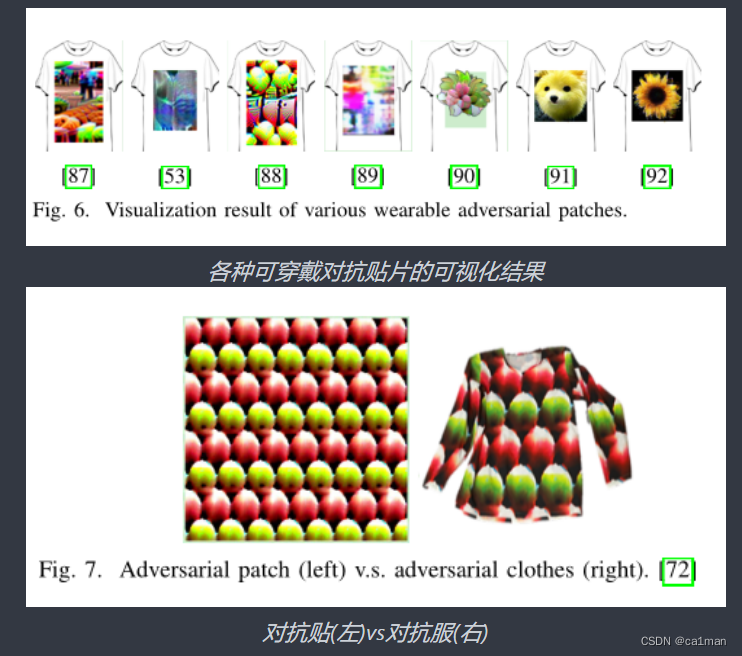
这衣服好像见哪个阿婆穿过,这是能说的吗
- 投影仪的投影
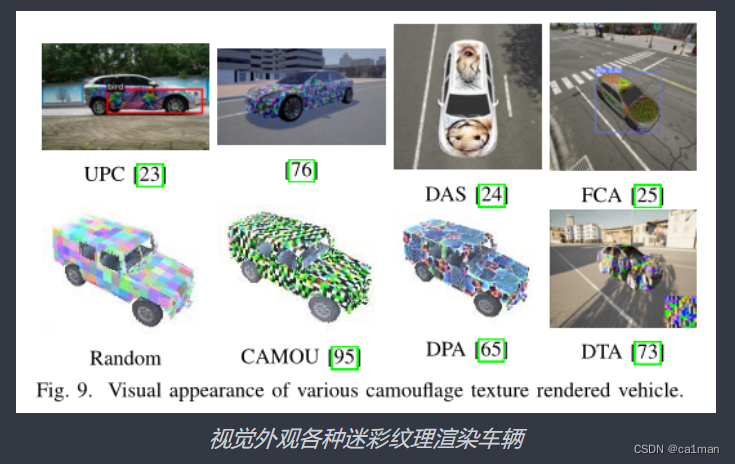
- 基于伪装的对抗纹理
模拟物理转换(如阴影和亮度)- Camou
- UPC
- DAS
- FCA
- DPA
- DTA
- 对抗红外探测器

(左)灯泡板,(右)气凝胶
-
针对天线检测
主要针对(无人机监视)航空图像数据集上的目标检测器,还有针对遥感图像识别和检测. -
Sparse adversarial attack
语义分割任务
将每个像素划分为固定的分类集合的任务

an open problem for future research
分割任务是计算机视觉任务最进阶的
语义分割:将整张图像输入网络,使输出的空间大小和输入一致,通道数等于类别数,分别代表了各空间位置属于各类别的概率,即可以逐像素地进行分类.
实例分割:(目标检测+语义分割)先用目标检测方法将图像中的不同实例框出,再用语义分割方法在不同包围盒内进行逐像素标记.
1008.基于改进RepVGG网络的车道线检测算法-武汉理工硕士
摘要
基于可解耦训练状态与推理状态的车道线检测算法,来提高自动驾驶系统中车道线检测的速度和精度
在结构化重参数VGG(RepVGG)主干网络中引入注意力机制压缩-激励(SE)模块,增强对重要车道信息的特征提取.
并行可分离的
辅助分割分支,对局部特征进行建模以提高检测精度;
逐行检测分支,减小计算量的同时实现对遮挡或缺损车道线的检测;
偏移补偿分支,恢复细节;
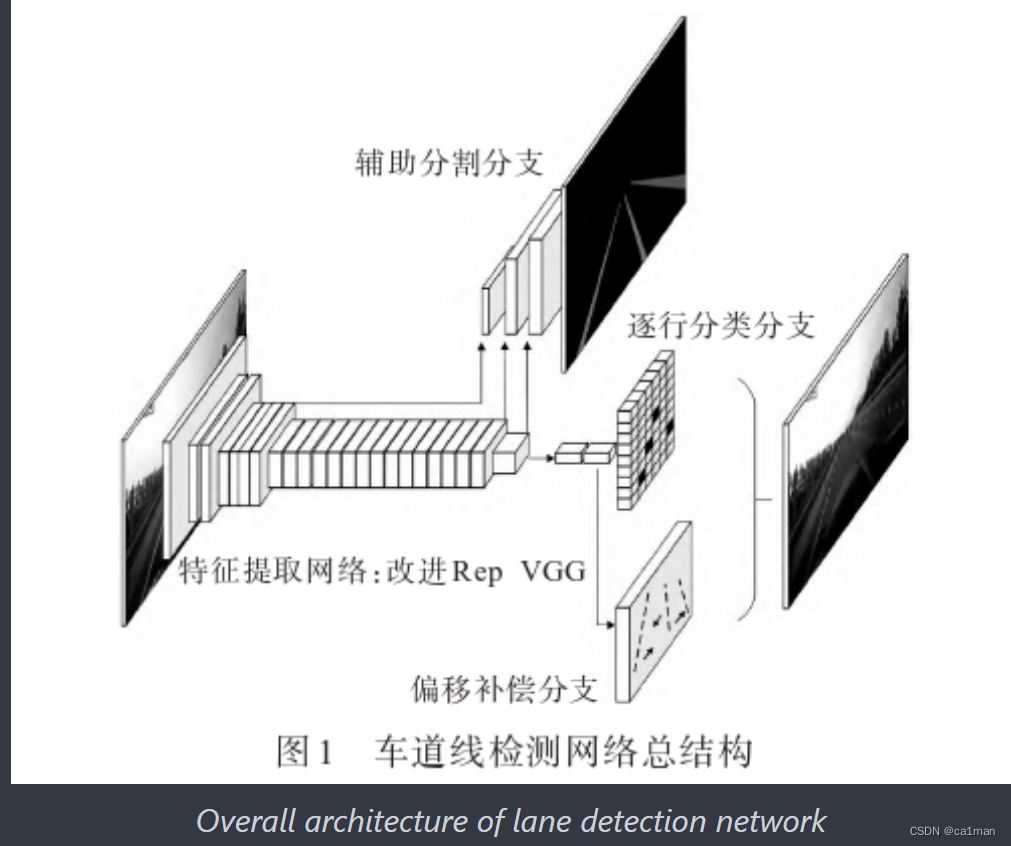
多分支模型等价转换为单路模型,提速.
1009.重新审视ResNets:改进的训练和扩展策略
Revisiting ResNets: Improved Training and Scaling Strategies
代码已开源(TensorFlow)
摘要
我们发现训练和缩放策略可能比架构变化更加重要
并且证明了最佳的缩放策略q依赖于训练机制,
提出了两种新的缩放策略:
- 在可能发生过拟合(overfitting)的机制中缩放模型深度(否则拓展宽度):
对于较长的 epoch 机制,深度扩展优于宽度扩展. - 以比之前更慢的速度扩展图像分辨率:
较大的图像分辨率会导致性能衰减,我们建议相比以往的工作,应该逐渐增加图像分辨率.
ResNet-RS 模型在训练中使用了更少的内存,但在 TPU 上的速度是 EfficientNets 的 1.7-2.7 倍,GPU 上的速度是 EfficientNets 的 2.1-3.3 倍.
在大规模半监督学习设置下,使用 ImageNet 和额外 1.3 亿伪标注图像进行联合训练时,ResNet-RS 在 TPU 上的训练速度是 EfficienrtNet-B5 的 4.7 倍,GPU 上的速度是 EfficientNet-B5 的 5.5 倍.
1010.基于位置感知的自监督步态编码三维骨骼行人重识别方法-22年中科院
A Self-Supervised Gait Encoding Approach With Locality-Awareness for 3D Skeleton Based Person Re-Identification
摘要
本文提出自监督的步态编码方法,可以利用未标记的骨骼数据学习ReID的步态表示.
首先,通过反向重构未标记的骨骼序列来创建自我监督,这涉及到更丰富的高级语义,以获得更好的步态表示.
其次,基于运动的连续性使得同一骨架序列中相邻的骨架序列具有较高的相关性(在三维骨架数据中称为局部性),为了在自我监督学习过程中分别保持序列内和序列间的位置感知,
提出了一种位置感知注意机制和位置感知对比学习方案.
最后,利用位置感知注意(locality-aware attention)机制和对比学习(contrastive learning)方案学习到的上下文向量(context vectors).
https://github.com/Kali-Hac/Locality-Awareness-SGE
INTRODUCTION
步态常用两种方法描述:
- 基于外观的方法,利用对齐图像序列中的人体轮廓来描述步态(体型变化和外观变化影响大)
- 基于模型的方法,通过人体结构和人体关节的运动来模拟步态(不受尺度和视角等因素的影响)
三维骨骼模型(3D skeleton model)通过人体众多关键关节的是三维坐标来描述人体
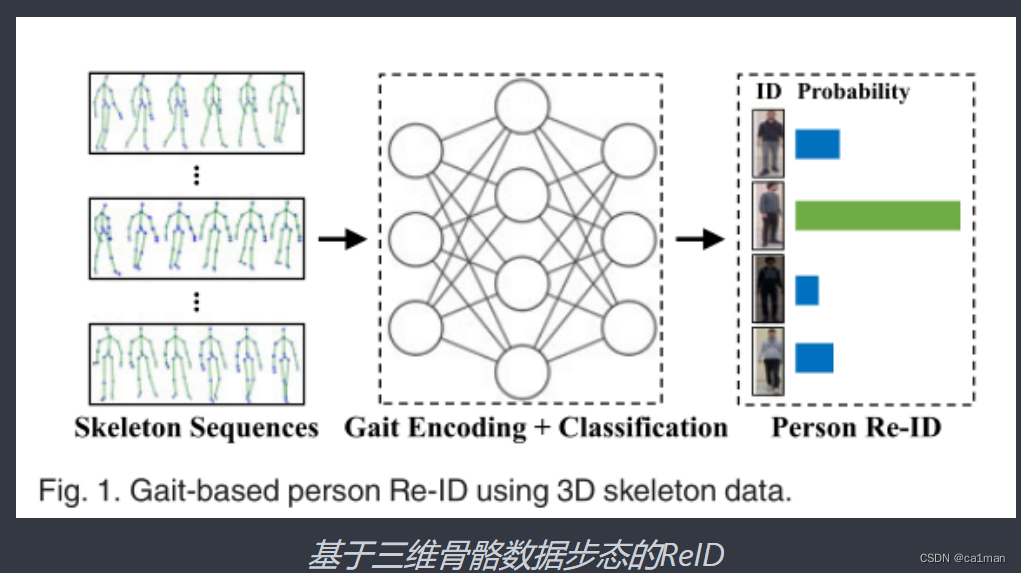
手工标注的骨骼描述器需要很多其他学科知识的支撑,而基于深度神经网络一般都要基于监督学习.
那么本文通过首先创建用于步态编码的自我监督信号,从未标记的骨骼数据中学习步态表示,并促进学习更丰富的高级语义(比如,序列顺序、身体部位运动)和更具有鉴别性的步态特征,也就是利用骨架序列的反向重建作为一个主要的自我监督学习目标.
并且,定义了序列内局部性和序列间局部性(内与间相关性都比较高),由此在自监督学习中引入位置感知,以实现更好的三维骨骼重建和步态编码.(基于对比注意的步态编码,CAGEs)
2020年的初版H. Rao, S. Wang, X. Hu, M. Tan, H. Da, J. Cheng, and B. Hu, “Self-supervised gait encoding with locality-aware attention for person re-identification,” in Proc. 29th Int. Joint Conf. Artif. Intell., 2020,pp. 898–905.
1011.基于一致样本挖掘的双聚类协同教学的无监督行人重识别-西安交大
Dual Clustering Co-teaching with Consistent Sample Mining for Unsupervised Person Re-Identification
摘要
在无监督行人重识别中,利用两个网络促进训练的对等教学策略是一种有效的处理伪标签噪声的方法.
但是,用一组有噪声的伪标签训练两个网络,会降低两个网络的互补性,导致标签噪声积累,
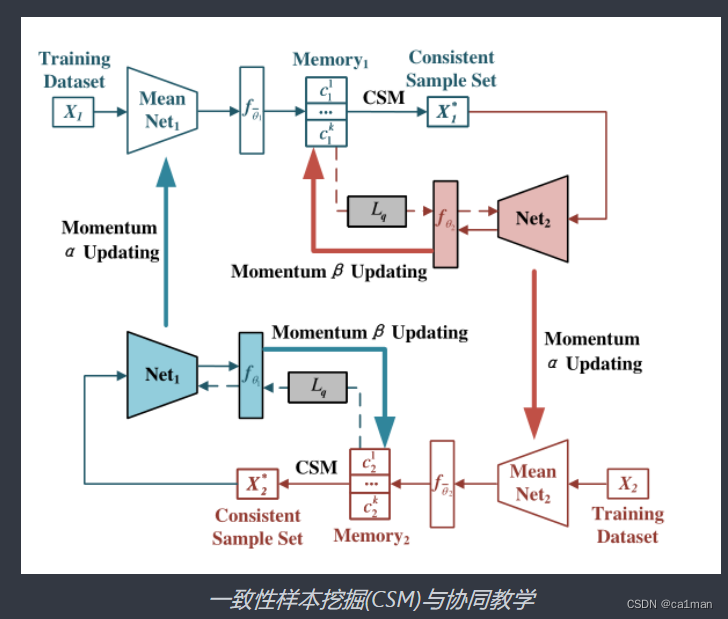
针对该问题,本文提出双聚类协同教学(DCCT)方法.
具体来说:
利用两个网络提取的特征,通过不同参数的聚类->分别生成两组伪标签->训练网络.
Furthermore,动态参数双聚类(DCDP),使网络对动态变化的聚类参数具有自适应和鲁棒性.
Moreover,一致样本挖掘(CSM)方法:在训练过程中发现伪标签不变的样本,来去除潜在的噪声样本.
INTRODUCTION
主流的无监督方法主要分两个阶段:通过聚类生成伪标签->再用这些伪标签进行训练
但是这些生成的伪标签无可避免会出现噪声(可能由于外观的差别细微到错误聚类,也有可能由于遮挡、模糊而导致被错误分到不同类)
通过两个网络协同训练解决这个问题,比如ACT和MMT(用了时间平均模型,temporally average models)
受这两个网络的启发,本文提出DCCT,
用两组伪标签训练两个网络,来增加网络间的差异性和互补性.
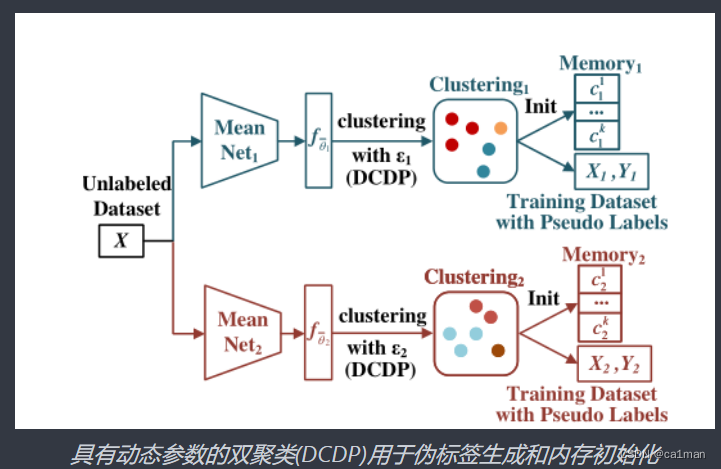
用时间平均模型从未标记的数据集中提取特征,
根据DCDP计算不同的聚类参数
用这个参数聚类,生成两组伪标签
1012.Omni-Scale Feature Learning for Person Re-Identification
面向行人重识别的全尺度特征学习-萨里大学
OSNet特别的:
- 全尺度特征学习
- 轻量级
摘要
作为实例级识别问题,行人重识别依赖于识别特征,
不仅捕获不同的空间尺度,而且封装了多个尺度的任意组合.
OSNet,
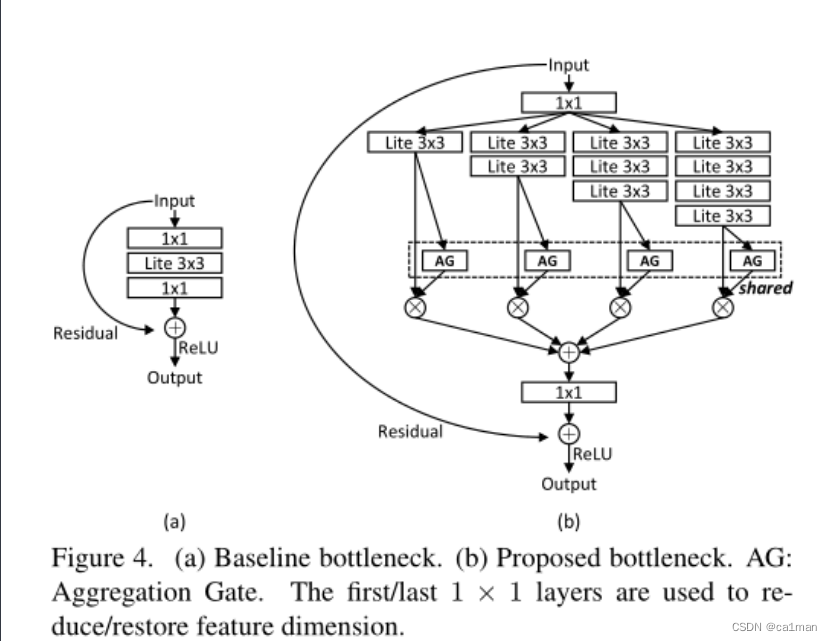
通过设计一个由多个卷积特征流组成的残差块来实现的,每个卷积流在一定的尺度上检测特征.
统一聚合门(unified aggregation gate),
动态融合多尺度特征与输入相关的信道权值;
构建块同时使用点卷积(pointwise convolution)和深度卷积(depth convolution),
学习通道空间相关性并避免过拟合,
层层堆叠这些块,OSNet十分轻量级
代码开源
INTRODUCTION
行人重识别关键问题就是解决
类内距离过大,类间距离过小这两个问题
关键就是学习鉴别特征(discriminative features)
我们认为这些特征需要是全尺度的(omni-scales),
同质和异质尺度
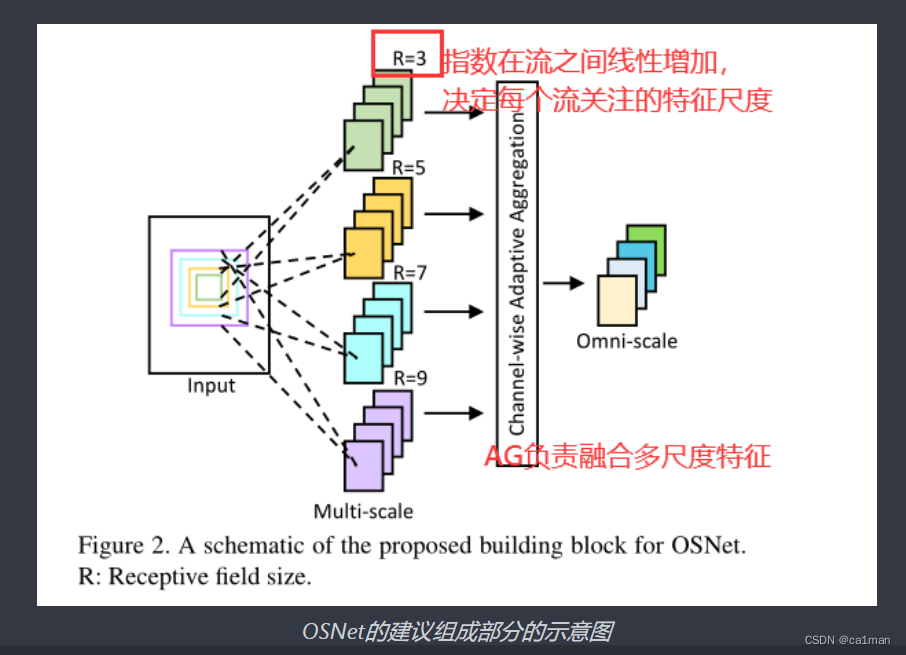
在轻量化的设计上,类似于MobileNet,采用分解卷积.
-
深度可分离卷积(depth separable convolutions)
用kernel划分卷积层为两个独立的层ReLU
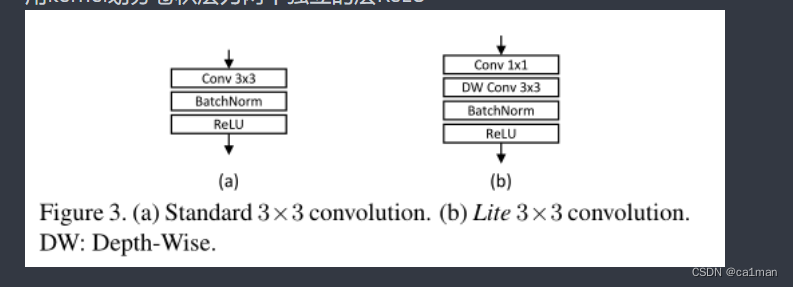
-
全尺度残差块(omni-scale residual block)
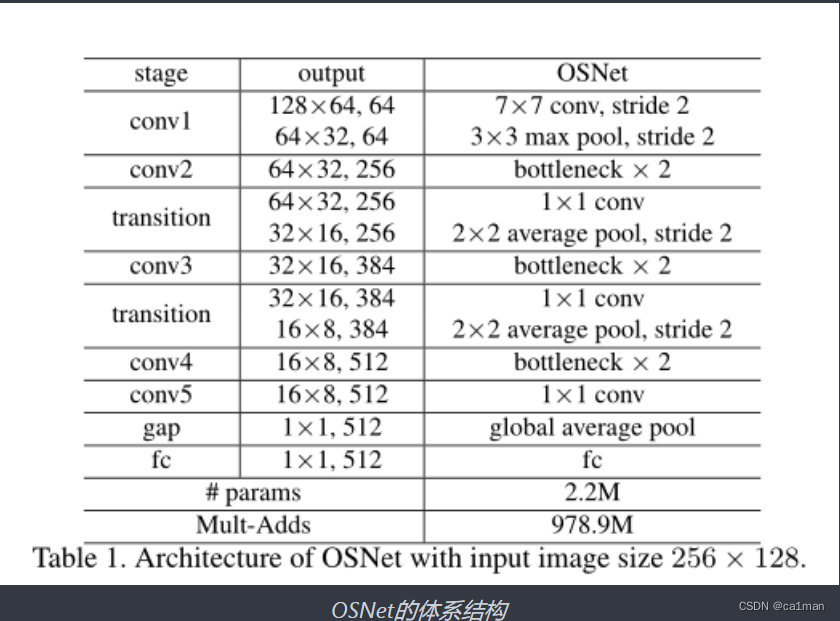
ARCHITECTURE
1014.自监督学习视频理解-2021牛津大学博士论文
Self-Supervised Video Understanding-Erika Lu
本科毕设刚刚去重开,甚至比原来的方向还要顺利😄
最近两天花时间整理了一下之前几周的学习下周组会分享
了解视频中哪些场景元素彼此相关是我们在本论文探索的一项基本推理任务.
设计可以理解视频中的对象如何影响他们的环境的计算机视觉算法.
第一,为了自动地将对象与其相关的视觉效果进行分组,我们采用分层方法(将视频分解为具有相关效果的对象层):
利用CNN将视频分解为特定于对象的层,其中包含随对象移动的所有元素.
应用:以新方式组合来生成原始视频的高度逼真的修改版本(比如删除或复制物体或改变运动的时间)【通用性,其他研究一般都是专门的系统】
第二,视频对象分割:
为视频中的对象生成按像素划分的标签
采用数据驱动的方法,
以self-supervised对大量视频进行训练.
- 半监督对象分割(semi-supervised object segmentation)
为单个帧提供初始对象掩码,将该掩码传播到其余frames - 移动对象发现(moving object discovery)
没有给出掩码,必须分割显著的移动对象
将对象及其相关效果分组(grouping objects with their correlated effects)
自监督视频对象分割(self-supervused video object segmentation)
自监督的移动对象发现(self-supervised moving object discovery):
我们的方法仅通过操作预计算光流来利用运动线索,
采用了transformer的简单变体,将输入流分解为前台对象层和后台层,
通过重新组合层来重建原始流.
类别无关计数(class-agnostic counting)
我们的方法输出一个heatmap(定位对象的所有出现)
heatmap支持检测计数和密度估计计数.
暂时看不懂…结束
1017.目标检测究竟发展到了什么程度-CVHub
https://zhuanlan.zhihu.com/p/382702930?utm_source=wechat_session&utm_medium=social&utm_oi=929469627257257984
1018.生成模型中的合成数据是否已准备好用于图像识别?-HK,Oxford,ByteDance
IS SYNTHETIC DATA FROM GENERATIVE MODELS READY FOR IMAGE RECOGNITION?
Code: https://github.com/CVMI-Lab/SyntheticData
INTRODUCTION
我们首次研究了用于图像识别的最新文本到图像生成模型:
GLIDE
探究两个问题:
1)生成模型中的合成数据准备好改进分类模型了吗
(因为合成数据的积极影响随着更多shot而削弱,所以只研究了zero-shot和few-shot设置)
2)合成数据是否可以作为可行的迁移学习(transfer learning)
发现:
In the zero-shot setting(没有可用的真实数据)合成数据可以显著改善17个不同datasets的分类结果;
In the few-shot setting(少量真实图像可用)也蛮好;
在用于迁移学习的大规模模型预训练中,goodgood,特别在无监督下效果特别好.
RELATED WORKS
Synthetic Data for Image Recognition
Text-to-Image Diffusion Models
扩散模型通过学习反转噪声过程来匹配底层数据分布,因此可以通过学习反转路径从先前的高斯分布中采样新图像.
1020.Fsat-ParC:Position Aware Global Kernel for ConvNets and ViTs
即插即用运算符,
位置感知卷积(ParC)及其加速版本Fast-ParC,
ParC通过使用全局核和循环卷积来捕获全局特征,同时通过位置嵌入来保持位置敏感性,
Fast-ParC使用快速傅里叶变换将ParC的时间复杂度降为O(nlogn).
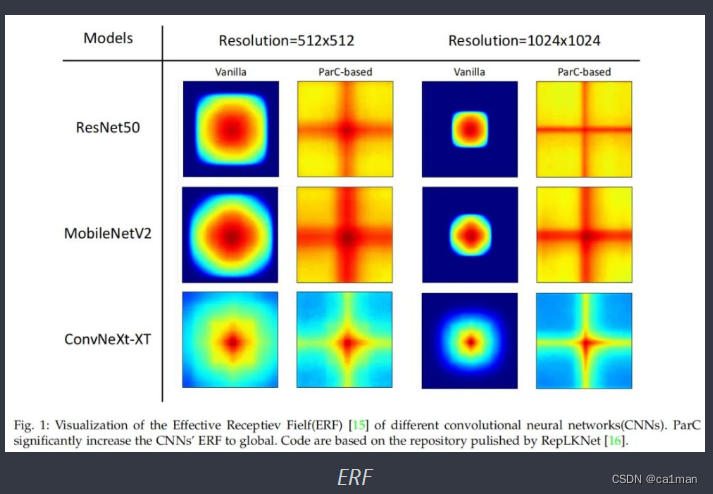
如图1,卷积网络应用ParC算子,改善了它们对全局的有效感受野.
CONTRIBUTIONS
- 结合ViT和ConvNets的优点提出了一种有效的新算子ParC
- 简化复杂度提出Fast-ParC,当给定较大的分辨率时,效率更高
- 对Parc和标准卷积网络作比较
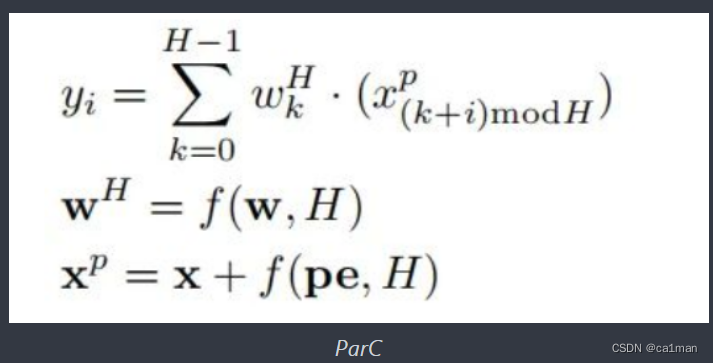
其中 i=0,1,…,H-1是固定大小的可学习kernel (由超参数指定), 而w_h是调整后的可学习kernel, 其大小与相应的输入特征映射大小匹配.
pe表示位置嵌入.
这里采用插值函数f(·,N)(例如 bi-linear, bi-cubic ) 来适应kernel的大小和位置嵌入(从K_h到H).
与普通卷积相比, ParC算子有 4 个主要区别:
- 全局核(在整个输入映射中提取全局关系)
- 循环卷积(使kernel权重总是与有效像素对齐)
- 位置嵌入(引入了可学习的位置编码)
- 1维分解(为了确保模型尺寸和计算的可接受成本)
1025.使用完全交叉Transformer的小样本目标检测-CVPR2022
Few-Shot Object Detection with Fully Cross-Transformer
FSOD的目标是利用数据丰富的基类来协助检测少样本的新类.
基于双分支的孪生网络,两个分支之间的交互仅限于检测头(detection head),而剩下的数百层用于单独的特征提取,
本文提出一种新颖的基于完全交叉转换器的FSOD模型FCT(Fully Cross-Transformer).
以往小样本检测方法大致分为两类:
-
single-branch方法
通常基于FasterRCNN进行整合,需要构建multi-class classifier,
但是针对shot较少例如1-shot时,较为容易出现overfitting. -
two-branch方法
通常构建Siamese网络,分别同时提取query特征和support特征,
基于metric learning方法(比如feature fusion,feature alignment,GCN)或者non-local attention来计算两分支的相似性,
不需要构建multi-class classifier,generalization更好.
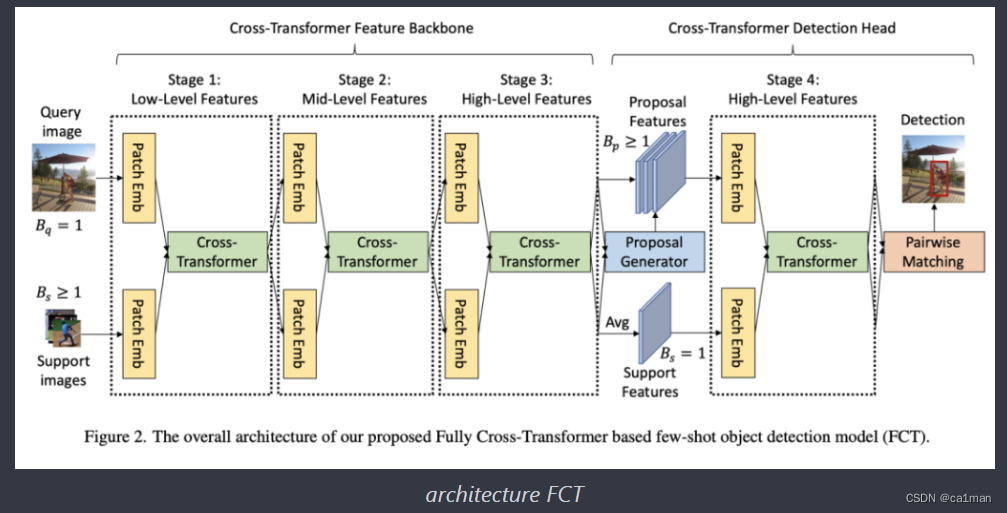
而且,在cross-transformer中计算Q-K-V attention时为了减少计算量,研究者采用了PVTv2的方式…
总结
本月好像看了蛮多,但是收获不多,电脑拿去返厂维修了,但是效果很不错捏,
下个月开始好好琢磨琢磨代码🐱



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











