









 本文详细介绍如何使用Elasticsearch实现高效全文检索,包括需求分析、搜索引擎原理、Elasticsearch介绍及配置、haystack对接步骤、索引类创建、序列化器及视图设置,并提供测试方法。
本文详细介绍如何使用Elasticsearch实现高效全文检索,包括需求分析、搜索引擎原理、Elasticsearch介绍及配置、haystack对接步骤、索引类创建、序列化器及视图设置,并提供测试方法。
1. 需求分析
当用户在搜索框输入关键字后,我们要为用户提供相关的搜索结果。
这种需求依赖数据库的模糊查询like关键字可以实现,但是like关键字的效率极低,而且查询需要在多个字段中进行,使用like关键字也不方便。
我们引入搜索引擎来实现全文检索。全文检索即在指定的任意字段中进行检索查询。
2. 搜索引擎原理
通过搜索引擎进行数据查询时,搜索引擎并不是直接在数据库中进行查询,而是搜索引擎会对数据库中的数据进行一遍预处理,单独建立起一份索引结构数据。
我们在通过搜索引擎搜索时,搜索引擎将关键字在索引数据中进行快速对比查找,进而找到数据的真实存储位置。
3. Elasticsearch
开源的 Elasticsearch 是目前全文搜索引擎的首选。
它可以快速地储存、搜索和分析海量数据。维基百科、Stack Overflow、Github 都采用它。
4. 使用Elasticsearch
获取镜像:
docker image pull delron/elasticsearch-ik:2.4.6-1.0运行容器:
docker run -d -p 9200:9200 --name search delron/elasticsearch-ik:2.4.6-1.0
至此Elasticsearch服务已经准备好
5. 使用haystack对接Elasticsearch
1、安装
pip install drf-haystack
pip install elasticsearch==5.5.3 #7以上的版本会报错(TypeError: search() got an unexpected keyword argument 'doc_type' )
2、注册应用
INSTALLED_APPS = [
...
'haystack',
...
]3、配置
Haystack为Django提供了模块化的搜索。可以让你在不修改代码的情况下使用不同的搜索后端(比如 Solr, Elasticsearch, Whoosh, Xapian 等等)。
此处我们配置为Elasticsearch搜索引擎后端。
# Haystack
HAYSTACK_CONNECTIONS = {
'default': {
'ENGINE': 'haystack.backends.elasticsearch_backend.ElasticsearchSearchEngine',
'URL': 'http://10.211.55.5:9200/', # 此处为elasticsearch运行的服务器ip地址
'INDEX_NAME': 'es_test', # 指定elasticsearch建立的索引库的名称
},
}
# 当添加、修改、删除数据时,自动生成索引
HAYSTACK_SIGNAL_PROCESSOR = 'haystack.signals.RealtimeSignalProcessor'4、创建索引类
通过创建索引类,来指明让搜索引擎对哪些字段建立索引,也就是可以通过哪些字段作为关键字来检索数据。
在goods应用中新建search_indexes.py(名字固定):
from haystack import indexes
from .models import SKU
class SKUIndex(indexes.SearchIndex, indexes.Indexable):
"""
SKU索引数据模型类
指明让搜索引擎对哪些字段建立索引,也就是可以通过哪些字段作为关键字来检索数据
"""
text = indexes.CharField(document=True, use_template=True)
name = indexes.CharField(model_attr='name')
comments = indexes.IntegerField(model_attr='comments')
def get_model(self):
"""返回建立索引的模型类"""
return SKU
def index_queryset(self, using=None):
"""返回要建立索引的数据查询集"""
return self.get_model().objects.all()其中text字段我们声明为document=True,表名该字段是主要进行关键字查询的字段, 该字段的索引值可以由多个字段组成,具体由哪些模型类字段组成,我们用use_template=True表示后续通过模板来指明。其他字段都是通过model_attr选项指明引用数据库模型类的特定字段。
在REST framework中,索引类的字段会作为查询结果返回数据的来源。
5、在templates目录中创建text字段使用的模板文件
具体在templates/search/indexes/goods/sku_text.txt文件中定义(文件名和路径注意格式)
{{ object.id}}
{{ object.category}}
此模板指明当将关键词通过text参数名传递时(即127.0.0.1:8080/goods/search/?text=2或127.0.0.1:8080/goods/search/?text=手机),可以通过sku的id、category来进行关键字索引查询。
6、创建序列化器
在goods/serializers.py中创建haystack序列化器
from drf_haystack.serializers import HaystackSerializer
from goods.search_indexes import SKUIndex
from rest_framework import serializers
class SKUSerializer(serializers.ModelSerializer):
"""
SKU序列化器
"""
class Meta:
model = SKU
fields = ['id', 'name', 'price', 'comments', 'default_image_url']
class SKUIndexSerializer(HaystackSerializer):
"""
SKU索引结果数据序列化器
"""
object = SKUSerializer(read_only=True) #关联对象的序列化器写法
class Meta:
# 索引类名称,可以是多个
index_classes = [SKUIndex]
# 第一个参数必须为text,除了object,其他字段必须与SKUIndex中字段对应
fields = ('text', 'name', 'comments', object)
7、创建视图类
在goods/views.py中创建视图
from drf_haystack.viewsets import HaystackViewSet
from .serializers import SKUIndexSerializer
from goods.models import SKU
class SKUSearchViewSet(HaystackViewSet):
"""
SKU搜索
"""
index_models = [SKU]
serializer_class = SKUIndexSerializer- 该视图会返回搜索结果的列表数据,所以可以为视图增加REST framework的分页功能。
8、添加路由
from django.conf.urls import url
from django.contrib import admin
from rest_framework.routers import DefaultRouter
from . import views
urlpatterns = [
# 商品列表
url(r'^categories/(?P<category_id>\d+)/skus/', views.SKUListView.as_view()),
# 面包屑
url(r'^categories/(?P<pk>\d+)/$', views.CategoryView.as_view()),
]
router = DefaultRouter()
router.register('skus/search', views.SKUSearchViewSet, base_name='skus_search')
urlpatterns += router.urls9、手动生成初始索引
python manage.py rebuild_index
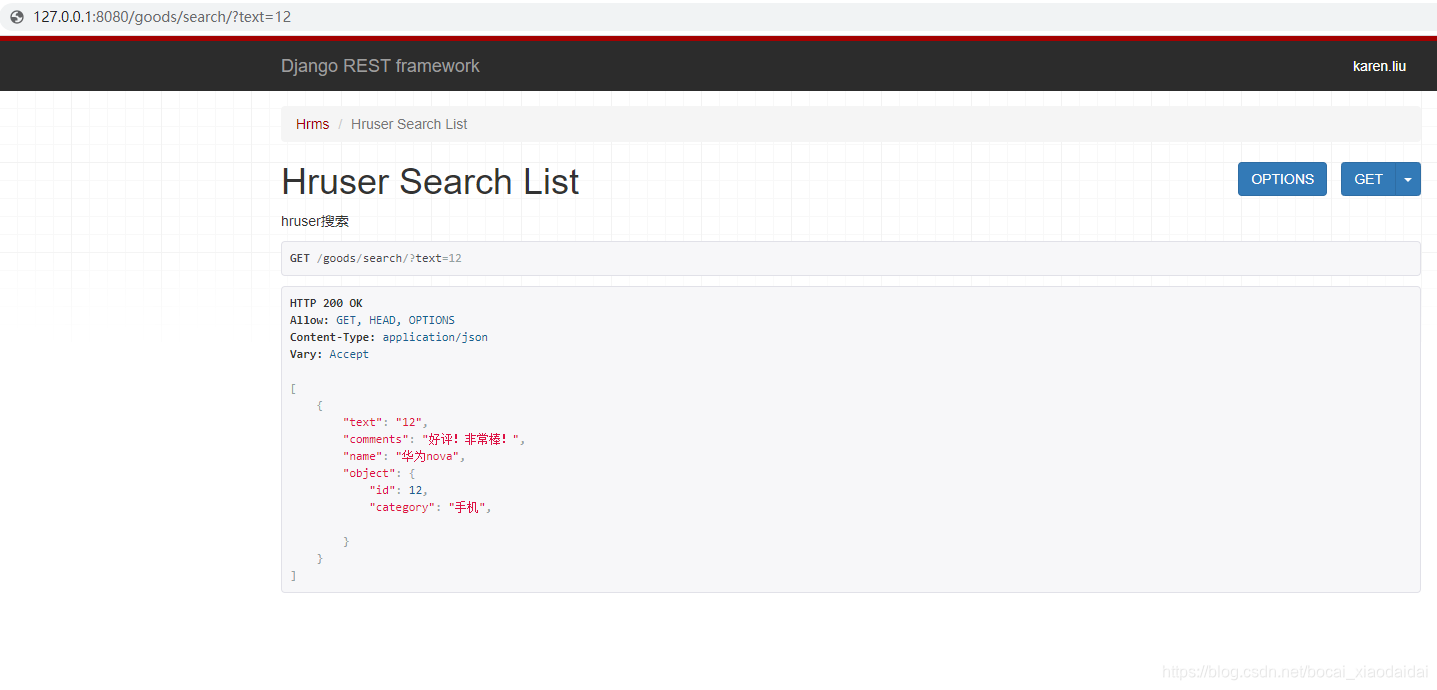
10、测试
http://127.0.0.1:8080/?text=12 #查询出id和comments中包含 12 的数据
http://127.0.0.1:8080/?name=华为荣耀H30 #查询出name包含 华为荣耀H30 的数据
http://127.0.0.1:8080/?comments=好评 #查询出comments包含 好评 的数据
11、注意
以上代码实例仅可以通过/?text=xxx、/?name=xxx、\?comments=xxx来查询。
当通过以上三个字段之外的关键词查询时,默认会返回模型中所有条数数据。可以通过前端js或者后端路由等控制关键词。

















 1122
1122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









