




 本文详细介绍了CPU缓存的基本结构及其工作原理,包括L1、L2、L3缓存的区别,缓存数据的加载与查找策略,以及缓存一致性问题的解决方案。通过解析缓存行(cacheline)的概念和N-way关联机制,阐述了如何提高缓存命中率,减少数据冲突。
本文详细介绍了CPU缓存的基本结构及其工作原理,包括L1、L2、L3缓存的区别,缓存数据的加载与查找策略,以及缓存一致性问题的解决方案。通过解析缓存行(cacheline)的概念和N-way关联机制,阐述了如何提高缓存命中率,减少数据冲突。
Linux 的 cache 结构
这里我犯了一个常识的错误,这里说的缓存并不是 Linux 的缓存,这里是在硬件角度来说的缓存的结构。
先来看看缓存的结构:
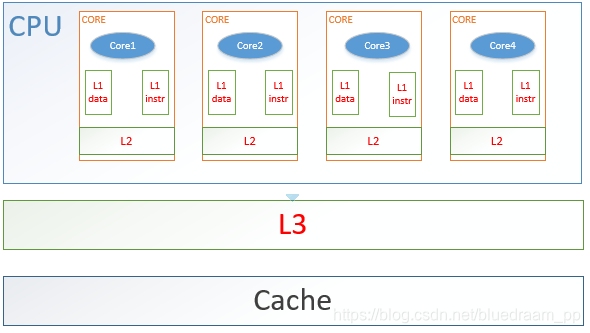
从图中,我总结了下面几点。
- cpu 想要访问 memory 中数据,必须将数据先加载到 cache 中。
- cache 一共有三种:L1、L2、L3
- L1、L2 都是每个 core 私有的
- L1:是距离 core 最近的 cache ,它可以分成两种,一种是 data 类型的,使用来存储数据的的;一种是 instrument 类型的,它是用来存储指令数据的。
- L2: 是介于 L1 和 L3 之间的 Cache
- L3:是 core 共有的cache 。
- 在三级cache 外面就是主存了。
如何运作的
有了结构后,我们再来探讨一下,数据是如何在主存、cache 之间进行数据的同步的。
还有如何从 cache 中查找数据?
如何保证正 L1、L2 私有 cache 数据是一致的?
cache 数据的加载和查找
将 memory 里面的数据同步到 cache 里面,我们可以随意的将数据放到 cache 没有数据的地方,就像我们可以把常用的物品放到家里的任何地方,这经常叫做猪窝。这样放东西的时候是爽了,但是在找东西的时候,就会让我们抓瞎了,我们会经常化几个小时找手机、眼镜、充电器放到哪里。所以我们把常用的东西放到固定的位置,这样我们只要记住几个地方,我们就能快速的找到了。同样的道理,我们可以将内存的数据放到 cache 固定的位置。这样查找起来就比较方便了。
这就引出两种数据加载的两个常用的策略:
- 随机加载。当数据要从主存加载到 cache 的时候,只要随便在 cache 里面找到一个空地,把数据放到里面就行了,但是这样找起来就比较耗时了,假如,cache 的大小为 n,随着 cache 的大小增大,查找数据的时间复杂度也在增大。所以这种策略的时间负责度为O(n)
- 另外一种是根据某种规则,将 memory 上的内存保存到 cache 的固定位置。最简单的方式就是取模操作,公式为:
缓 存 中 的 地 址 = ( 主 存 地 址 ) m o d ( c a c h e l i n e 的 数 量 ) × ( 一 个 c a c h e l i n e 的 大 小 ) 缓存中的地址 = (主存地址) mod\bigl(cache line 的数量)\times(一个cache line的大小) 缓存中的地址=(主存地址)mod(cacheline的数量)×(一个cacheline的大小)
上面的公式中提到 cache line ,在了解上面的公式之前,我们先看看什么是 cache line。
大家知道,操作系统对内存是分页管理的,这样管理起来更加简单。这样可以使用有限的地址来管理更多的内存地址。在 cache 里面也继承了这样的策略。但是 cache 的大小比内存小的多。举个例,Intel 大多数处理器的 Cache Line 是 64 Bytes。俗话说的好一图胜千言,
所以我画了图。
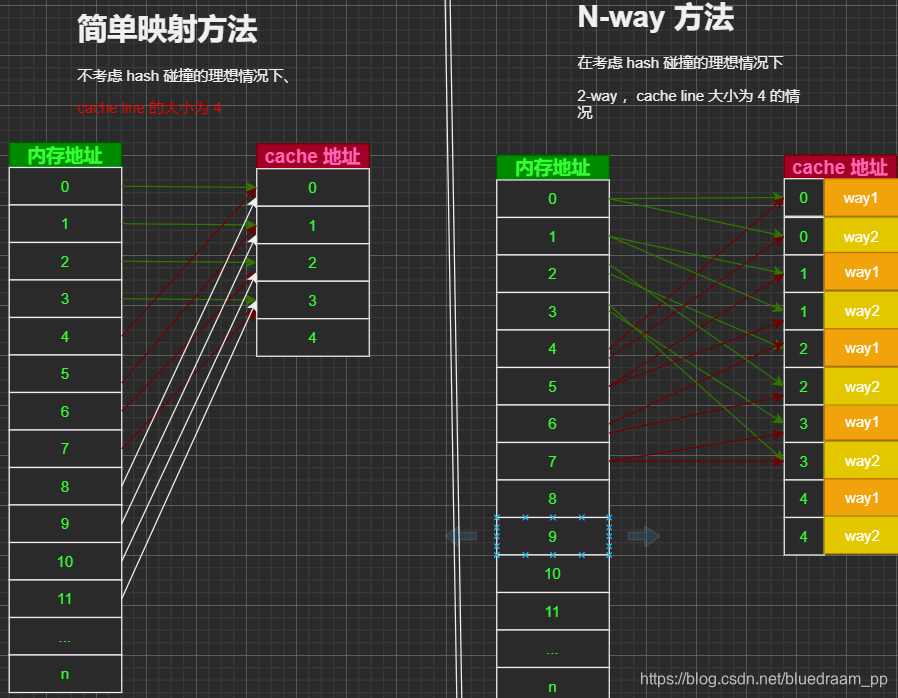
在图中我把问题简化, 其中, 1~n 代表了一个 cache line ,我们是使用 内存地址mod(cache 数量) 的方式来做映射的。
在简单的映射方法中,我们可以看到很多内存地址会映射到相同的 cache line ,这就是所谓的 hash 碰撞。这种 hash 碰撞会降低指令中地址在 cache 中命中率。
为提高 cache 的命中率,大多数的处理器中会使用 N-way 关联,把 cache line 先分组处理,如果有内存地址先映射到 cache line 组里面,然后再讲有碰撞得 cache line 放到分组里面得一个 cache line 单元,这样会再很程度上缓解 hash 碰撞,减少了 hash 碰撞,自然就减少了从内存加载数据到 cache line,最终会提高程序得执行效率。
我们再来理解一下数字,Intel 大多数处理器的 L1 Cache 都是32KB,8-Way 组相联,Cache Line 是64 Bytes,我们可以得到下面节里。
- L1 中会有 32kb/64Bytes=512 个 cache line 组
- 1 个 cache 组中会有 512/8 = 64 个 cache line
- 一个 cache line 有64Byte 存储空间大小,也就是 16 个32位整型数值,一个 Byte 是 8 个 bit ,32 位就是 4 个 Byte。
下面再来说说 cache line 的结构:

其中,
- 从左往右,cache line 的前 24 位是就是内存地址的前 24 位
- 从左往右,7~11 这 6 位是对 cache line 分组得所以,一共有 2 的 6 次方正好是 cache line 组的数量。
- 从左往右,0~6 是 offset ,也就是在 offset 里面的偏移量。
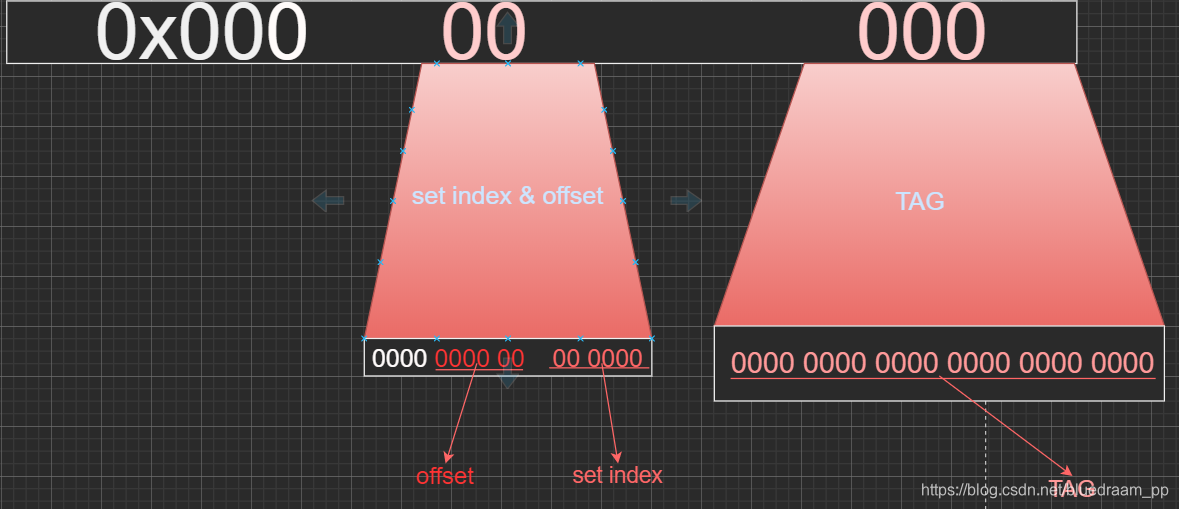
- 内存地址的前 24 位映射到 cache line 的 tag 中
- 中间的 6 位地址映射到 set index 中
- 在做查找的过程中,先使用内存地址中的中间的 6 位定位到在那个组里面,在使用 24 位来定位是在那一路里面。
- 每隔 2 的 12 次方地址就会产生冲突,这也是要在变成中可以优化的地方。
cache 中的一致性问题
先来看看,缓存和主存之间是如何做到数据一致的,大家都知道,只读的情况下,不会有数据一致性的问题,但是写的情况下就的有了数据一致性的问题。
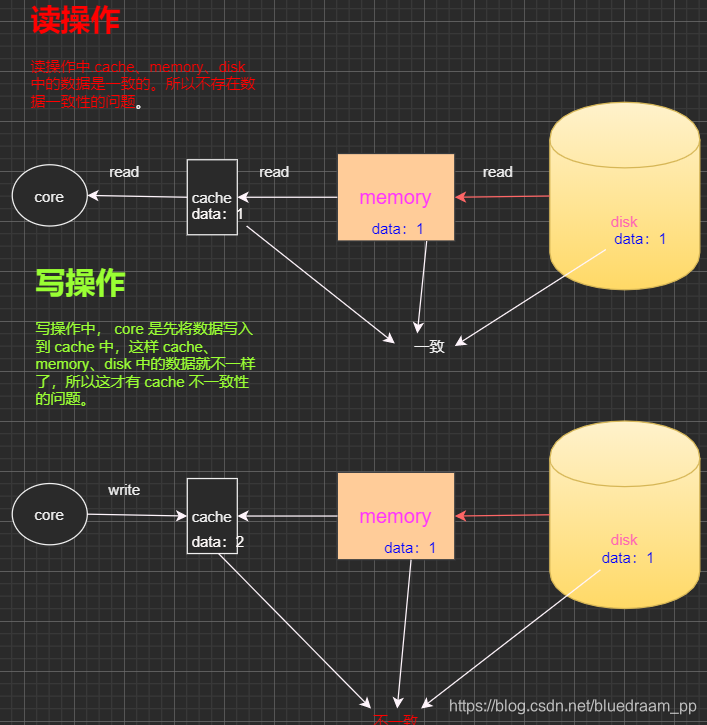
cache 和 memory 之间有两种数据同步的机制:
- write through: 写操作同时写到cache和内存上。
- write back:写操作只要在cache上,然后再flush到内存上。
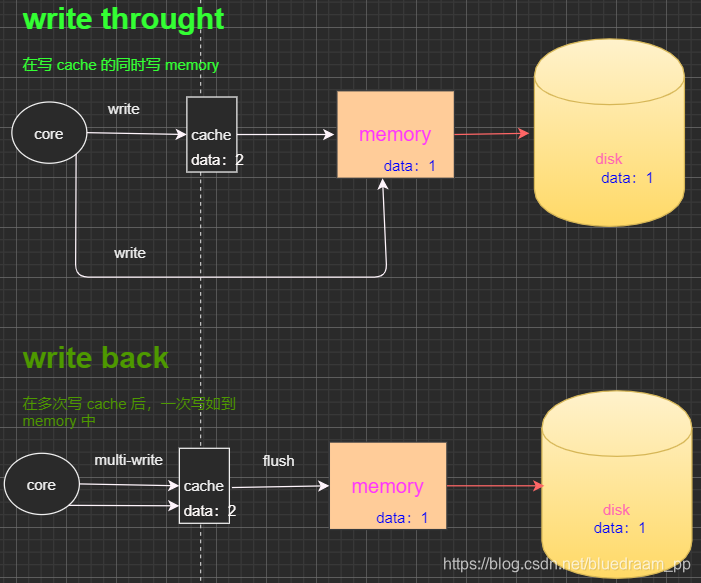 在图中,我们清楚的看到,还是 write back 这种方式的效率高一点。
在图中,我们清楚的看到,还是 write back 这种方式的效率高一点。
在上面 cache 的架构图里面,我们知道 L1、L2 是线程私有的,如果在不同 core 里面运行的进程同时使用了相同地址上的数据,那么如何保证数据是一致的呢?这种问题在分布式系统中是非常常见的,为了解决这个问题,雅虎还开发了 zookeeper 来解决分布式系统数据的一致性问题。
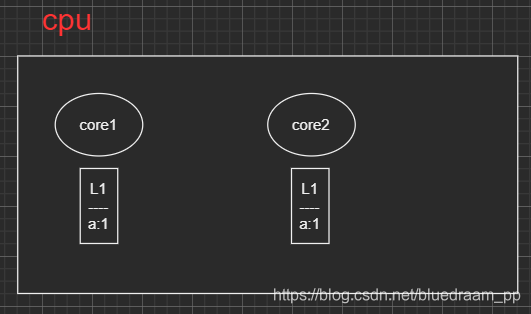
一般的情况下,有两种方式:
- directory协议。这种方式是在主存控制器中,实现一种集中式的控制器。在这个控制器中,有这么一个目录,这个目录存储在主存中,这里面保存着本地缓存的各种状态信息。一旦,某个本地缓存的数据发生了改变,就通过集中控制器,把这种状态同步到缓存、主存中。
- snoopy 协议,数据通知的总线型,CPU cache 通过总线可以发布私有 cache 的数据是否改变,也可以通过总线发现其他私有cache的数据已经改变了。snoopy 的一种实现方式是 MESI 协议,它里面有四种状态:Modified(已修改), Exclusive(独占的),Shared(共享的),Invalid(无效的),可以看看:动图

















 1581
1581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









