






一、什么是多线程
多任务可以由多进程完成,也可以由一个进程内的多线程完成。我们说进程是由若干线程组成的,一个进程至少有一个线程。由于线程是操作系统直接支持的执行单元,因此,高级语言通常都内置多线程的支持,Python也不例外,并且,Python的线程是真正的Posix Thread,而不是模拟出来的线程。
Python的标准库提供了两个模块: _thread 和 threading , _thread 是低级模块,threading是高级模块,对 _thread 进行了封装。绝大多数情况下,我们只需要使用 threading这个高级模块。
启动一个线程就是把一个函数传入并创建Thread实例,然后调用start() 开始执行。
二、自我认知的多线程
回想一下,我们在你看这篇文章之前是否运行代码都为下面这样,定义两个函数,并且调用他们;
(这里调用time模块只是为了模拟大型程序运行过程的等待时间,可有可无)
import time
import _thread
def song(name):
for i in range(5):
time.sleep(1)
print("正在听歌...")
def code(name):
for i in range(5):
time.sleep(0.5)
print("正在编码...")
# 这两个工作肯定是一个执行结束, 另外一个任务才开始执行;
song(1)
code(1)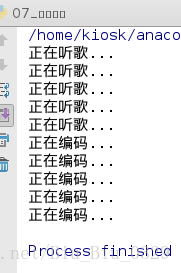
我们看到上面的运行结果,先把song函数调用结束后才运行code的代码,但是这对于高速时代发展的我们来说实在是太慢了,为什么不可以让电脑在同一时间内去充分利用他的cpu;这里需要强调的是电脑运行速度最快的是cpu>内存>硬盘,但是cpu大部分时间是在等待下一个指令,而并非在不停的做着运算,所以为达到这一目的,我们需要用到多线程,让我们的cpu时刻保持高速的运算;
下面我们据一个例子来说明这一点:
_thread模块
import time
import _thread
def song(name):
for i in range(5):
time.sleep(1)
print("正在听歌...")
def code(name):
for i in range(5):
time.sleep(0.5)
print("正在编码...")
# # 这两个工作肯定是一个执行结束, 另外一个任务才开始执行;
# song(1)
# code(1)
_thread.start_new_thread(song, ('song',))
_thread.start_new_thread(code, ('code',))
while 1:
pass
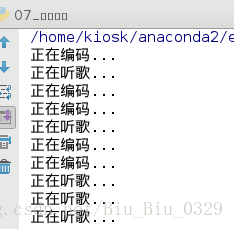
我们能看到运行结果,代码在交替运行,也就是说我们上面的两个函数在cpu运行,而并没有让cpu“休息”,如果你不太愿意相信它是多线程那么可以从运行速度上来进行比较;
threading模块
import time
import threading
# 实现多线程的第一种方式:
def song(name):
for i in range(5):
time.sleep(0.1)
print("正在听歌:%s" %(name))
def code(name):
for i in range(5):
time.sleep(0.3)
print("正在编码:%s" %(name))
# song('hello') # 15s
# code('hello') # 10s
t1 = threading.Thread(target=song, args=("sunshine",))
t2 = threading.Thread(target=code, args=("python",))
t1.start()
t2.start()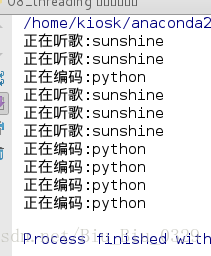
三、实现多线程的两种方式
1、方式一
import time
import threading
# 实现多线程的第一种方式:
def song(name):
for i in range(5):
time.sleep(0.1)
print("正在听歌:%s" %(name))
def code(name):
for i in range(5):
time.sleep(0.3)
print("正在编码:%s" %(name))
# song('hello') # 15s
# code('hello') # 10s
t1 = threading.Thread(target=song, args=("sunshine",))
t2 = threading.Thread(target=code, args=("python",))
t1.start()
t2.start()每次每个函数都要实例化,启动;特别的麻烦,这里只是我们再做测试而只有少量的函数被调用;但是在实际中我们不可能对海量的信息都进行实例化的操作,所以我们需要一个更为方便的方法来进行多线程操作;
2、方式二
class MyThread(threading.Thread):
def __init__(self, name):
super(MyThread, self).__init__()
self.name = name
def run(self):
for i in range(5):
time.sleep(0.3)
print("正在", self.name )
# 声明线程为守护线程;
# 不设定守护线程时, 主线程执行结束, 不会结束子线程;
# 设定守护线程时, 主线程执行结束, 子线程也结束;
#
t1 = MyThread("code")
t2 = MyThread("song")
t1.setDaemon(True)
t2.setDaemon(True)
t1.start()
t2.start()
t1.join()
t2.join()
print('end').join为守护进程,若没有守护进程,则有可能在子进程还没结束时,主进程就已经运行结束;因为python已经封装好了threading模块,当我们需要继承父类使用时,我们只需要在构造函数后重新写run函数就可以实现了;其他的方法你继承的threading父类里已经帮你写好封装了;

由于任何进程默认就会启动一个线程,我们把该线程称为主线程,主线程又可以启动新的线程,Python的threading模块有个 current_thread()函数,它永远返回当前线程的实例。主线程实例的名字叫MainThread,子线程的名字在创建时指定,我们用 LoopThread 命名子线程。名字仅仅在打印时用来显示,完全没有其他意义,如果不起名字Python就自动给线程命名为Thread-1 , Thread-2 ......
四、线程锁(Lock)
1、为什么要线程锁
多线程和多进程最大的不同在于,多进程中,同一个变量,各自有一份拷贝存在于每个进程中,互不影响,而多线程中,所有变量都由所有线程共享,所以,任何一个变量都可以被任何一个线程修改,因此,线程之间共享数据最大的危险在于多个线程同时改一个变量,把内容给改乱了。
下面我们就看一个例字,以此来证明线程锁的重要性;
说明:模拟一个银行存取款的过程,我们存n元,再取出n元。其结果应该是我们的银行存款数目不变,在我们不加线程锁时,当运行次数达到一定大时就会出现差错,但是这在银行系统中是绝对不允许发生的;
import threading
balance =0
def change_it(n):
# 先存后取,结果应该为0:
global balance
balance=balance+n
balance=balance-n
def run_thread(n):
for i in range(100000):
change_it(n)
t1 =threading.Thread(target=run_thread,args=(5,))
t2 =threading.Thread(target=run_thread,args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
print(balance)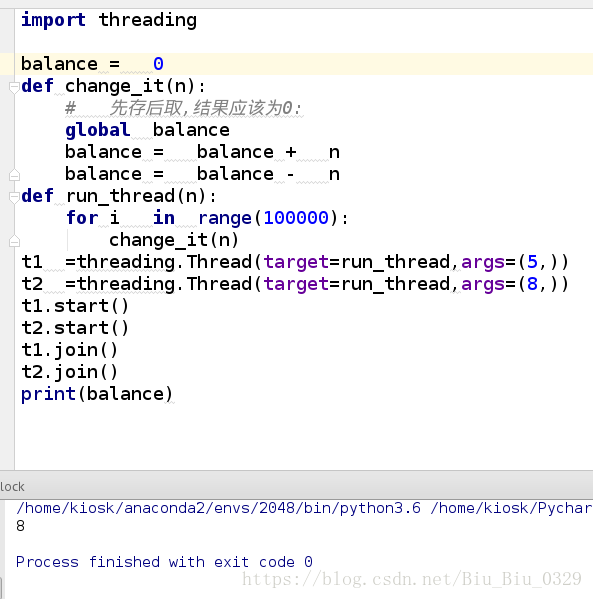
上面的运行结果已经说明了问题,
我们定义了一个共享变量balance,初始值为0,并且启动两个线程,先存后取,理论上结果应该为0,但是,由于线程的调度是由操作系统决定的,当t1、t2交替执行时,只要循环次数足够多,balance的结果就不一定是0了。
原因是因为高级语言的一条语句在CPU执行时是若干条语句,即使一个简单的计算:
balance =balance+n也要分两步:
1. 计算 balance + n ,存入临时变量中;
2. 将临时变量的值赋给 balance
也可以看成:
x = balance + n
balance = x分析原因:
是因为修改balance需要多条语句,而执行这几条语句时,线程可能中断,从而导致多个线程把同一个对象的内容改乱了。
两个线程同时一存一取,就可能导致余额不对,你肯定不希望你的银行存款莫名其妙地变成了负数,所以,我们必须确保一个线程在修改 balance的时候,别的线程一定不能改。
2、线程锁的实现
import threading
balance = 0
lock = threading.Lock()
def change_it(n):
# 先存后取,结果应该为0:
global balance
balance = balance + n
balance = balance - n
def run_thread(n):
for i in range(100000):
lock.acquire() #获取创建的线程锁;
try:
change_it(n)
finally:
lock.release() # 释放线程锁;
t1 =threading.Thread(target=run_thread,args=(5,))
t2 =threading.Thread(target=run_thread,args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
print("当前金额:",balance)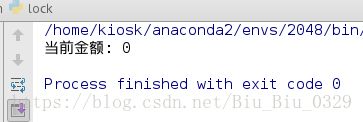
在我实验过无数次之后确认是没问题的(当然这个模块本生就是没有问题,我们只是去测试而已);
上面我们先用threading模块创建一个线程锁,并且把它放在一个变量中,并且在run函数中去创建,和释放线程锁;
但是在这里要着重讲一下try 和 finally 的必要性:获得锁的线程用完后一定要释放锁,否则那些苦苦等待锁的线程将永远等待下去,
成为死线程。所以我们用 try...finally 来确保锁一定会被释放。锁的好处就是确保了某段关键代码只能由一个线程从头到尾完整
地执行,坏处当然也很多,首先是阻止了多线程并发执行,包含锁的某段代码实际上只能以单线程模式执行,效率就大大地下降了。其次,
由于可以存在多个锁,不同的线程持有不同的锁,并试图获取对方持有的锁时,可能会造成死锁,导致多个线程全部挂起,既不能执行,也无
法结束,只能靠操作系统强制终止。
五、多核CPU(GIL锁)
如果你不幸拥有一个多核CPU,你肯定在想,多核应该可以同时执行多个线程。如果写一个死循环的话,会出现什么情况呢?
打开Mac OS X的Activity Monitor,或者Windows的Task Manager,都可以监控某个进程的CPU使用率。
我们可以监控到一个死循环线程会100%占用一个CPU。如果有两个死循环线程,在多核CPU中,可以监控到会占用200%的CPU,也就是
占用两个CPU核心。要想把N核CPU的核心全部跑满,就必须启动N个死循环线程。
试试用Python写个死循环:
import threading, multiprocessing
def loop():
x = 0
while True:
x = x ^ 1
for i in range(multiprocessing.cpu_count()):
t = threading.Thread(target=loop)
t.start()
启动与CPU核心数量相同的N个线程,在4核CPU上可以监控到CPU占用率仅有102%,也就是仅使用了一核。
但是用C、C++或Java来改写相同的死循环,直接可以把全部核心跑满,4核就跑到400%,8核就跑到800%,为什么Python不行呢?
1、GIL进程锁
因为Python的线程虽然是真正的线程,但解释器执行代码时,有一个GIL锁:Global Interpreter Lock,任何Python线程执行前,必须先获
得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。这个GIL全局锁实际上把所有线程的执行代码都
给上了锁,所以,多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。
2、python的遗留问题
GIL是Python解释器设计的历史遗留问题,通常我们用的解释器是官方实现的CPython,要真正利用多核,除非重写一个不带GIL的解释
器。所以,在Python中,可以使用多线程,但不要指望能有效利用多核。如果一定要通过多线程利用多核,那只能通过C扩展来实现,不过这
样就失去了Python简单易用的特点。
3、解决办法
不用过于担心,Python虽然不能利用多线程实现多核任务,但可以通过多进程实现多核任务。多个Python进程有各自独立的GIL锁,互不影响。
六、生产消费者模型--多线程
我们这里采用继承的方式实现多线程;import random
import threading
from queue import Queue
import time
class Producer(threading.Thread):
def __init__(self,name,queue):
super(Producer, self).__init__()
self.queue = queue
self.name = name
def run(self):
n = random.randint(1,10)
for i in range(n):
if self.queue.full():
print('queue is full , producer wait')
else:
self.queue.put(str(i))
print('%s put %s into queue' %(self.name,str(i)))
time.sleep(1)
class Consume(threading.Thread):
def __init__(self,name,queue):
super(Consume, self).__init__()
self.name = name
self.queue = queue
def run(self):
n = random.randint(2,7)
for i in range(n):
if self.queue.empty():
print('queue is empty , consume wait')
else:
value = self.queue.get()
print('%s get value %s from queue' %(self.name,value))
print('队列中还有%s个任务要执行'%(self.queue.qsize()))
time.sleep(1)
q = Queue(5)
thread = []
for i in range(3):
thread.append(Producer('producer'+str(i),q))
thread.append(Producer('consumer '+str(i),q))
for j in thread:
j.start()
for k in thread:
k.join()
print('任务结束')这里也有线程间的信息传递 Queue,后面我还会说到进程,线程间的信息传递;
下面是另一种呈现多线程的方式,这里只是为了展示他们的不同,并不提倡大家的使用;
import random
import threading
import time
from queue import Queue
def Producer(queue,name):
n = random.randint(1,10)
for i in range(n):
if queue.full():
print('queue is full , producer wait')
else:
queue.put(str(i))
print('%s put %s into queue' %(name,str(i)))
time.sleep(1)
def Consume(queue,name):
n = random.randint(2, 7)
for i in range(n):
if queue.empty():
print('queue is empty , consume wait')
else:
value = queue.get()
print('%s get value %s from queue' % (name, value))
print('队列中还有%s个任务要执行' % (queue.qsize()))
time.sleep(1)
q = Queue(5)
thread = []
t1 = threading.Thread(target=Producer,args=(q,'producer'))
t2 = threading.Thread(target=Consume,args=(q,'consume'))
t1.start()
t2.start()
t1.join()
t2.join()
print('任务结束')
七、线程池
线程池:在cpu中先申请一片空间,做好提前的多线程的准备工作,这样会节省一部分线程切换的时间;
我们可以来看一个例字:
from concurrent.futures import ThreadPoolExecutor
from concurrent.futures import as_completed
from urllib.request import urlopen
import time
URLS = ['http://httpbin.org', 'http://example.com/', 'https://api.github.com/',
'http://httpbin.org', 'http://example.com/', 'https://api.github.com/']
def load_url(url,timeout=30):
with urlopen(url,timeout=timeout) as urlObj:
return urlObj.read()
def thread_main():
with ThreadPoolExecutor(max_workers=4) as pool:
future_url = {pool.submit(load_url, url ,30):url for url in URLS}
for future in as_completed(future_url):
url = future_url[future]
try:
data = future.result()
except Exception as e:
print('%s网页信息爬取失败'%(url))
else:
print('%s 网页有 %s 字节'%(url,len(data)))
def no_thread():
for url in URLS:
try:
data = load_url(url)
except Exception as e:
print('%s网页信息爬取失败' % (url))
else:
print('%s 网页有 %s 字节' % (url, len(data)))
start = time.time()
thread_main()
end = time.time()
print('main %.2f'%(end-start))
start = time.time()
no_thread()
end = time.time()
print('no_thread %.2f'%(end-start))在这个代码中,我们使用了线程池极大的节省了线程在切换时时间。
无论是多进程还是多线程,只要数量一多,效率肯定上不去,为什么呢?
我们打个比方,假设你不幸正在准备中考,每天晚上需要做语文、数学、英语、物理、化学这5科的作业,每项作业耗时1小时。
如果你先花1小时做语文作业,做完了,再花1小时做数学作业,这样,依次全部做完,一共花5小时,这种方式称为单任务模型,或者批处理,务模型。假设你打算切换到多任务模型,可以先做1分钟语文,再切换到数学作业,做1分钟,再切换到英语,以此类推,只要切换速度足够快,这种方式就和单核CPU执行多任务是一样的了,以幼儿园小朋友的眼光来看,你就正在同时写5科作业。但是,切换作业是有代价的,比如从语文切到数学,要先收拾桌子上的语文书本、钢笔(这叫保存现场),然后,打开数学课本、找出圆规直尺(这叫准备新环境),才能开始做数学作业。操作系统在切换进程或者线程时也是一样的,它需要先保存当前执行的现场环境(CPU寄存器状态、内存页等),然后,把新任务的执行环境准备好(恢复上次的寄存器状态,切换内存页等),才能开始执行。这个切换过程虽然很快,但是也需要耗费时间。如果有几千个任务同时进行,操作系统可能就主要忙着切换任务,根本没有多少时间去执行任务了,这种情况最常见的就是硬盘狂响,点窗口无反应,系统处于假死状态。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









