







欢迎来到ZyyOvO的博客✨,一个关于探索技术的角落,记录学习的点滴📖,分享实用的技巧🛠️,偶尔还有一些奇思妙想💡
本文由ZyyOvO原创✍️,感谢支持❤️!请尊重原创📩!欢迎评论区留言交流🌟
个人主页 👉 ZyyOvO
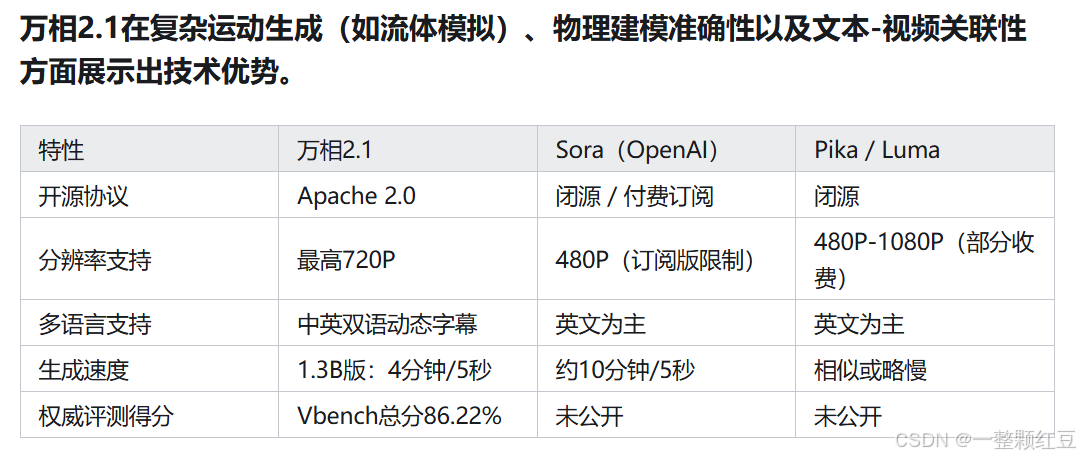
蓝耘GPU × 通义万相2.1
通义万相2.1大模型简介

通义万相2.1:VBench榜单荣登第一!阿里通义万相最新视频生成模型,支持生成1080P长视频
万相2.1 的主要功能
- 复杂动作展现:稳定展现各种复杂的人物肢体运动,如旋转、跳跃、转身、翻滚等,及镜头的移动,让视频内容更加生动和真实。
- 物理规律还原:逼真还原真实世界的物理规律,如碰撞、反弹、切割、挤压等。比如生成雨滴落在伞上溅起水花的场景,让视频更具真实感。
- 中英文视频特效生成:提供多种视频特效选项,如过渡、粒子效果、模拟等,能一键生成中英文视频特效,增强视频的视觉表现力。
- 艺术风格转换:具备强大的艺术风格表现力,能一键转换视频的影视质感与艺术风格,如电影色调、印象笔触、抽象表现等,生成各种风格的视频。
- 图生成:支持分镜效果还原、四格漫画创作、创意头像定制等功能,满足用户的不同需求。
万相2.1 的技术原理
- VAE架构:变分自编码器(VAE)是生成模型,用编码器将输入数据映射到一个潜在空间,再用解码器将潜在空间的表示映射回数据空间,实现数据的生成和重建。
- DiT架构:DiT(Diffusion in
Time)架构是基于扩散模型的生成模型,在时间维度上逐步引入噪声,逐步去除噪声生成数据。DiT能有效地捕捉视频的时空结构,支持高效编解码和生成高质量的视频。 - IC-LoRA:IC-LoRA是一种图像生成训练方法,基于结合图像内容和文本描述,增强文本到图像的上下文能力,让生成的图像更加符合用户的文本描述和期望。
- 上下文建模:基于增强时空上下文建模能力,更好地理解和生成具有连贯性和一致性的视频内容,让视频中的动作、场景和风格等元素更加自然和协调。
模型概述

定位:
- 通义万相2.1(
WanXiang2.1)是阿里巴巴达摩院推出的多模态生成式AI模型,专注于高精度图像、视频及3D内容的生成与编辑,面向企业级AIGC(AI生成内容)场景,提供从创意到生产的全链路解决方案。
核心目标:
- 解决传统内容生产中效率低、成本高、创意迭代慢的痛点,通过AI技术赋能电商、游戏、影视、广告等行业的数字化内容生产。
技术架构与核心功能
- 多模态生成能力
图像生成:
- 支持文本到图像(
Text-to-Image)、图像到图像(Image-to-Image)生成,分辨率最高可达8K。 - 特色功能:细粒度控制(如局部重绘、风格迁移)、多图一致性生成(角色/场景连贯性)。
视频生成:
- 基于文本或关键帧生成短视频(最长30秒),支持动态镜头控制(如推拉摇移)。
3D内容生成:
- 从单张图片生成3D模型(
Mesh+纹理),适配游戏、VR/AR场景需求。
算法创新
混合训练框架:
- 融合
Diffusion模型与Transformer架构,平衡生成质量与速度。
知识增强技术:
- 引入行业知识图谱(如电商商品属性、游戏角色设定),提升生成内容的专业性与可控性。
低资源优化:
- 支持FP16/INT8量化推理,显存占用降低50%,适配边缘设备部署。
企业级功能扩展
API与SDK:
- 提供
RESTful API和Python SDK,支持批量任务调度与异步处理。
版权管理:
- 内置数字水印与版权溯源机制,符合企业合规需求。
私有化部署:
- 支持模型微调与私有数据训练,保护企业数据隐私。
核心优势与竞品对比
| 指标 | 通义万相2.1 | Stable Diffusion XL | MidJourney |
|---|---|---|---|
| 分辨率 | 最高8K,支持超分重建 | 最高4K | 最高2K |
| 多模态支持 | 图像+视频+3D | 仅图像 | 仅图像 |
| 可控性 | 细粒度参数控制(光照、材质等) | 依赖Prompt工程 | 依赖社区插件扩展 |
| 企业级服务 | 私有化部署、API计费 | 开源模型需自建服务 | 仅限订阅制云端服务 |
独特优势
- 行业场景适配:预置电商、游戏等垂直领域模板,减少定制化开发成本。
- 生成效率:在相同硬件下,批量任务处理速度比Stable Diffusion快2.3倍(基于阿里云测试数据)。
- 合规性:内置内容安全审核模块,自动过滤敏感元素。
典型应用场景
电商行业
- 商品场景图生成:输入“夏日沙滩鞋+椰树背景+俯拍视角”,自动生成广告图。
- 虚拟试穿:结合3D生成能力,实现服饰AI试穿效果预览。
游戏与影视
- 角色原画设计:通过文本描述生成角色多视角设定图,保持风格一致性。
- 分镜脚本可视化:将剧本文字快速转化为分镜草图,加速前期制作。
广告营销
-
个性化广告素材:根据用户画像动态生成千人千面的广告内容。
-
节日营销模板:预置春节、双十一等主题素材库,一键批量生成。
未来迭代方向
多模态融合:
- 实现文本/图像/音频跨模态联合生成(如带背景音乐的短视频)。
实时交互:
- 支持低延迟实时编辑(如设计师拖拽修改生成结果)。
开放生态:
- 推出模型市场,允许第三方开发者共享垂直领域微调模型。
总结
阿里万相2.1凭借其多模态生成能力、企业级功能扩展和行业场景深度适配,成为AIGC工业化落地的标杆模型。结合蓝耘GPU平台的弹性算力与成本优势,二者共同构建了从创意到生产的高效闭环,推动AI内容生成从“实验性探索”迈向“规模化应用 🚀
蓝耘GPU平台概述

定位:
- 蓝耘GPU平台是面向 AI高性能计算(
HPC)和生成式AI (AIGC) 场景设计的分布式GPU算力服务平台,专注于为企业与开发者提供弹性、高性价比的GPU算力资源,支持从模型训练、推理到大规模部署的全流程需求。
核心目标

- 解决传统算力方案中存在的高成本、低利用率、扩展性差等问题,助力AI模型(如阿里万相2.1)实现高效工业化落地。
技术架构与核心优势:
- 硬件层:弹性GPU集群
多型号GPU支持:搭载NVIDIA A100、V100、H100等高性能显卡,支持混合集群调度。
分布式架构:通过高速网络(如InfiniBand)实现多机多卡并行计算,突破单机算力瓶颈。
按需扩展:支持分钟级动态扩容,适应突发算力需求(如电商大促期间的AI图像批量生成)。
- 软件层:深度优化技术栈
容器化部署:集成Kubernetes与Docker,实现任务快速迁移与隔离。
显存优化:采用显存虚拟化技术与分块加载策略,提升大模型(如万相2.1)的显存利用率。
框架适配:预置PyTorch、TensorFlow等主流框架的定制化版本,降低分布式训练代码改造成本。
- 核心优势
成本降低:通过资源池化与动态调度,GPU利用率提升至80%+(对比传统方案30%-50%)。
性能加速:针对生成式AI任务(如高分辨率图像生成),推理速度提升2-5倍。
稳定性保障:自动故障转移与冗余备份,任务中断率<0.1%。
典型应用场景
- AIGC内容生成
图像/视频生成:支持Stable Diffusion、阿里万相等模型的高并发推理,适用于广告创意、游戏原画等场景。
3D建模:加速NeRF、GAN等模型的训练,缩短3D内容生产周期。
- 大模型训练与微调
千亿参数模型分布式训练:支持数据并行、模型并行混合策略,降低训练耗时。
低成本微调:通过弹性资源分配,按需调用GPU完成垂类模型迭代。
- 科学计算与仿真
分子动力学模拟:利用GPU加速量子化学计算。
气象预测:优化WRF等科学计算框架的并行效率。
未来发展方向
- 边缘计算融合:推动GPU算力下沉至边缘节点,支持实时AI推理(如直播互动、工业质检)。
- 绿色算力:通过液冷技术与能耗优化,降低PUE(电源使用效率)至1.2以下。
- 生态扩展:与更多AI模型(如国产大模型)深度适配,构建开放算力生态。
总结
蓝耘GPU平台通过软硬协同优化与分布式架构设计,成为生成式AI时代的关键算力基座,尤其在与阿里万相2.1等前沿模型的结合中,展现了显著的效率提升与成本优势。其灵活性和企业级服务能力,使其在电商、游戏、科研等领域快速落地,推动AI从实验性技术向生产级工具演进。🌟
蓝耘GPU平台和通义万相2.1的协同优势
技术适配性:软硬协同优化
| 优化维度 | 蓝耘GPU的技术支持 | 对万相2.1的增益效果 |
|---|---|---|
| 分布式并行计算 | 多机多卡协同(如NVIDIA A100集群) | 突破单卡显存限制,支持8K图像/长视频生成 |
| 显存管理 | 显存虚拟化+动态分块加载 | 大模型推理显存占用降低40%,避免OOM中断 |
| 通信优化 | InfiniBand网络+定制NCCL通信库 | 多节点任务通信延迟减少60%,提升批量任务吞吐量 |
| 框架适配 | 预置PyTorch轻量化推理框架 | 万相2.1模型零代码修改即可部署,缩短上线周期 |
- 算力匹配优化
分布式推理加速:蓝耘GPU的多卡并行技术,解决万相2.1高分辨率生成时的显存瓶颈。
弹性资源调度:应对电商大促等流量高峰,动态扩展GPU节点,避免资源闲置。
- 实测性能数据
吞吐量提升:在蓝耘A100集群上,万相2.1的8K图像生成速度达12 FPS(对比单卡V100的2.5 FPS)。
成本对比:相同任务量下,蓝耘GPU集群的综合成本比公有云方案低35%(数据来源:蓝耘技术白皮书)。
- 端到端解决方案
训练-推理一体化:蓝耘平台支持万相2.1的模型微调与实时推理无缝衔接。
全链路监控:提供生成任务耗时、GPU利用率等可视化看板,优化资源分配。
- 成本效率:资源利用率最大化
弹性伸缩降低闲置成本
- 动态资源调度:蓝耘GPU支持秒级扩容,应对万相2.1的流量峰值(如电商大促期间需生成10万张广告图)。
- 混合部署策略:CPU+GPU异构资源池自动分配预处理与生成任务,综合成本下降30%。
量化与压缩技术
-
FP16/INT8混合精度:在保证万相2.1生成质量的前提下,推理速度提升2.5倍,能耗降低50%。
-
模型剪枝:针对企业私有化部署需求,裁剪冗余参数,模型体积缩小35%。
场景落地:企业级生产闭环
电商行业:广告素材批量生成
流程优化:
- 万相2.1生成基础素材 → 蓝耘GPU集群批量超分至4K/8K → 自动审核并推送至投放平台。
效果数据:
- 日均处理量:50万张图片 → 成本0.02元/张(对比外包设计1.5元/张)。
- 影视制作:实时分镜预览
技术联动:
- 导演输入文本描述 → 万相2.1生成分镜草图 → 蓝耘边缘GPU节点实时渲染 → 低延迟投屏讨论。
延迟对比:
- 传统方案:10-15秒/帧 → 协同方案:2秒/帧(1080P分辨率)。
算力匹配:
- 针对万相2.1的多模态生成需求,蓝耘GPU提供多卡协同推理能力,支持单任务跨多GPU显存共享。
- 优化模型分片策略,减少跨节点通信开销,提升批量任务吞吐量。
实际效果:
- 吞吐量提升:在512x512图像生成任务中,8卡集群对比单卡速度提升6.8倍。
- 成本优化:通过混合精度推理与动态批处理,单位图像生成成本下降45%。
| 指标 | 蓝耘GPU | 公有云通用GPU实例 |
|---|---|---|
| 弹性伸缩 | 秒级扩容,支持异构GPU混合调度 | 通常需预留实例,扩容延迟较高 |
| 定价模型 | 按需计费+预留资源折扣 | 按小时计费,长期使用成本高 |
| 定制化支持 | 提供框架级优化与私有化部署方案 | 标准化服务,定制能力有限 |
| 本地化合规 | 支持私有化部署与数据隔离 | 依赖全球数据中心,合规门槛高 |
通义万相2.1文生图,文生视频已上线蓝耘应用市场,如下就是:

看到这里是否也跃跃欲试,接下来我们为大家介绍如何注册蓝耘GPU平台使用如此强大的模型,注册就有算力券相送!点击一键跳转注册🔥
跳转到如下界面:我们根据需要填写对应信息就可以注册成功。

注册成功后进入主页面,进入应用市场,即可看到阿里万相2.1模型:
蓝耘GPU平台 x 通义万相2.1应用教程
首先选择自己需要的阿里万相模型,是文生图,还是文生视频,这里我以文生图为例:
点击部署,跳转到如下界面:
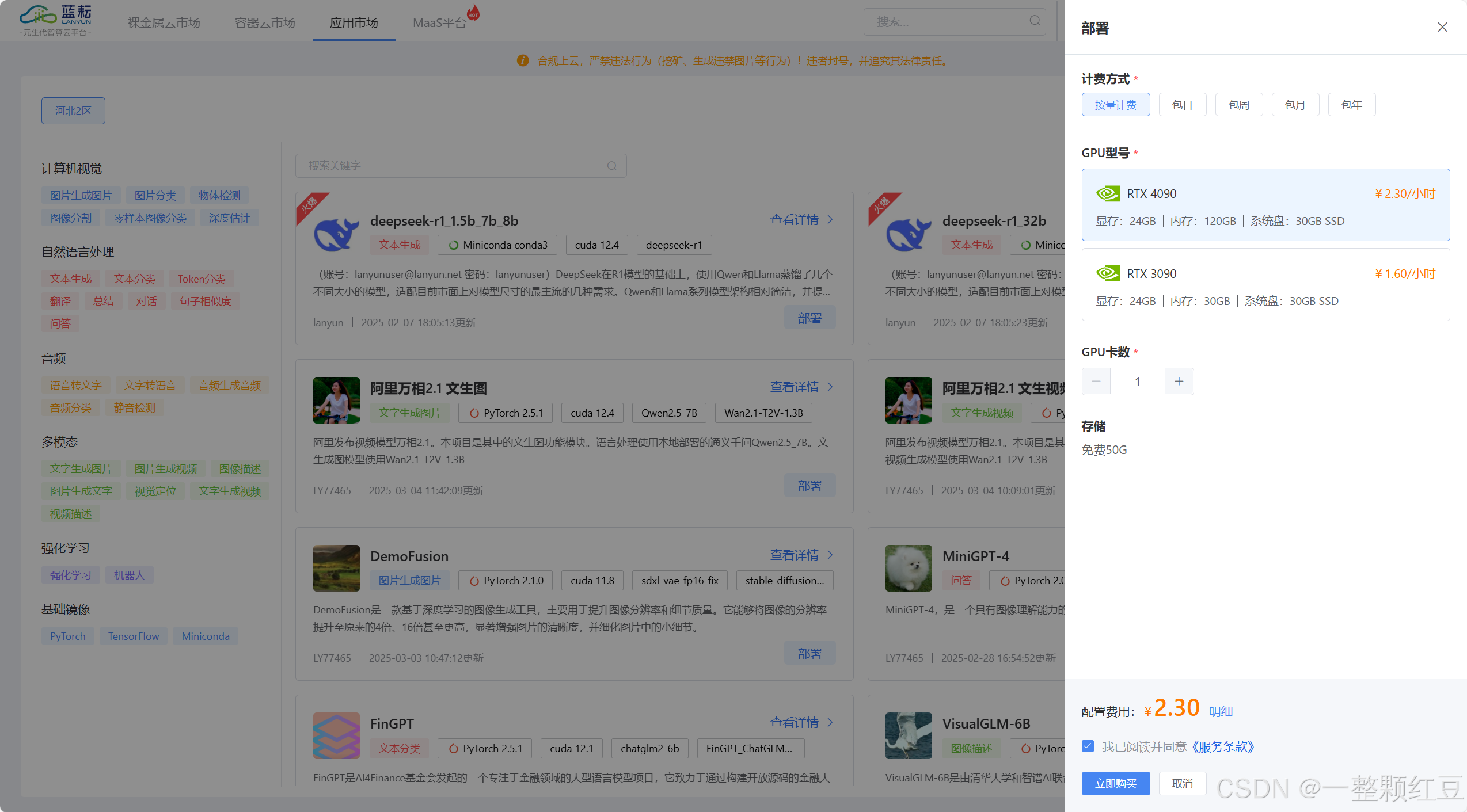
按照自己的需求完成配置。
配置好之后打开工作空间,启动应用后进入如下界面:
这就是通义万相2.1文生图片的具体操作页面!
参数介绍
下面为大家介绍这些参数的具体含义:
- 提示词输入(
Prompt)
在 “Describe the image you want to generate” 下方的文本框中,尽可能详细地描述你期望生成的图像内容。比如,你想要生成一幅海边日落的画面,可以写 “一幅展现金色夕阳洒在平静海面上,沙滩上有几串脚印,远处有一艘小船的图像” 。描述越细致,生成的图像就越可能符合你的预期。
- 提示词语言选择(
Target language of prompt enhance)
CH(中文):若你用中文输入提示词,就选择这个选项。工具会基于中文提示词进行处理和优化。
EN(英文):当你使用英文输入提示词时,选择此项。
- 提示词优化(
Prompt Enhance)
这部分系统会自动根据你输入的提示词进行优化,以提高生成图像的质量和准确性,一般无需额外手动操作。
高级选项设置(Advanced Options)
- 分辨率(
Resolution (Width*Height)):点击下拉框,可选择预设的分辨率,也可以手动输入自定义的宽和高数值,例如常见的“1920*1080”。高分辨率能呈现更丰富的细节,但可能会增加生成时间。 - 扩散步数(
Diffusion steps):数值范围是 1 到 1000。较低的步数(如 20 -
50)能快速生成图像,但可能细节不足、质量欠佳;较高的步数(如 200 - 500)生成的图像会更精细、噪点更少,但耗时更长。 - 引导尺度(
Guide scale):范围是 0 到20。数值越小,生成图像的随机性越强,可能与提示词的匹配度稍低,但会有更多创意元素;数值越大,生成图像会严格按照提示词内容,风格相对更保守、精准。 - Shift 尺度(
Shift scale):范围是 0 到 10。该参数用于调整生成过程中的某些偏移效果,数值不同会使生成图像在细节和构图上有一定差异,通常保持默认或根据生成效果微调。 - 随机种子(
Seed):输入特定的整数数值,能使每次使用相同的提示词和参数设置时,生成相同的图像,方便你固定某种满意的效果;输入 “-1”则每次生成随机效果。 负向提示词(NegativePrompt):在文本框中输入你不希望出现在图像中的元素或特征。比如,你不希望图像中有云朵,可以输入“没有云朵”,这样能避免生成包含此类元素的图像。
图像生成
- 完成上述所有设置后,点击 “Generate Image” 按钮,系统开始处理并生成图像。生成的图像会显示在右侧 “GeneratedImage” 区域。如果对生成结果不满意,可以调整提示词或各项参数,再次点击生成,直至得到满意的图像。
实战案例
我们先来一个简单点的:
提示词
- 输入:一只毛茸茸的橘猫趴在洒满阳光的窗台上,旁边放着一个小鱼形状的玩具
提示词语言选择,选择 “CH”,因为提示词是中文。
高级选项设置(Advanced Options)
- 分辨率(Resolution (Width*Height)):保持默认的 “720 * 1280”。
- 扩散步数(Diffusion steps):可以先保持默认的 “50” ,若对生成效果不满意,后续可适当增加步数来提高图像质量。
- 引导尺度(Guide scale):默认 “5”,这个数值能让生成图像与提示词有较好的匹配度,先不做调整。
- Shift 尺度(Shift scale):维持默认的 “5” 。
- 随机种子(Seed):输入 “-1”,让每次生成都是随机效果。
- 负向提示词(Negative Prompt):输入 “不要杂乱的背景,不要其他动物” ,避免生成的图片中出现不想要的元素。
完成以上设置后,点击 “Generate Image” 按钮,即可开始生成图片。
等待几秒后,我们看到图片已经生成,和我们的预期符合:
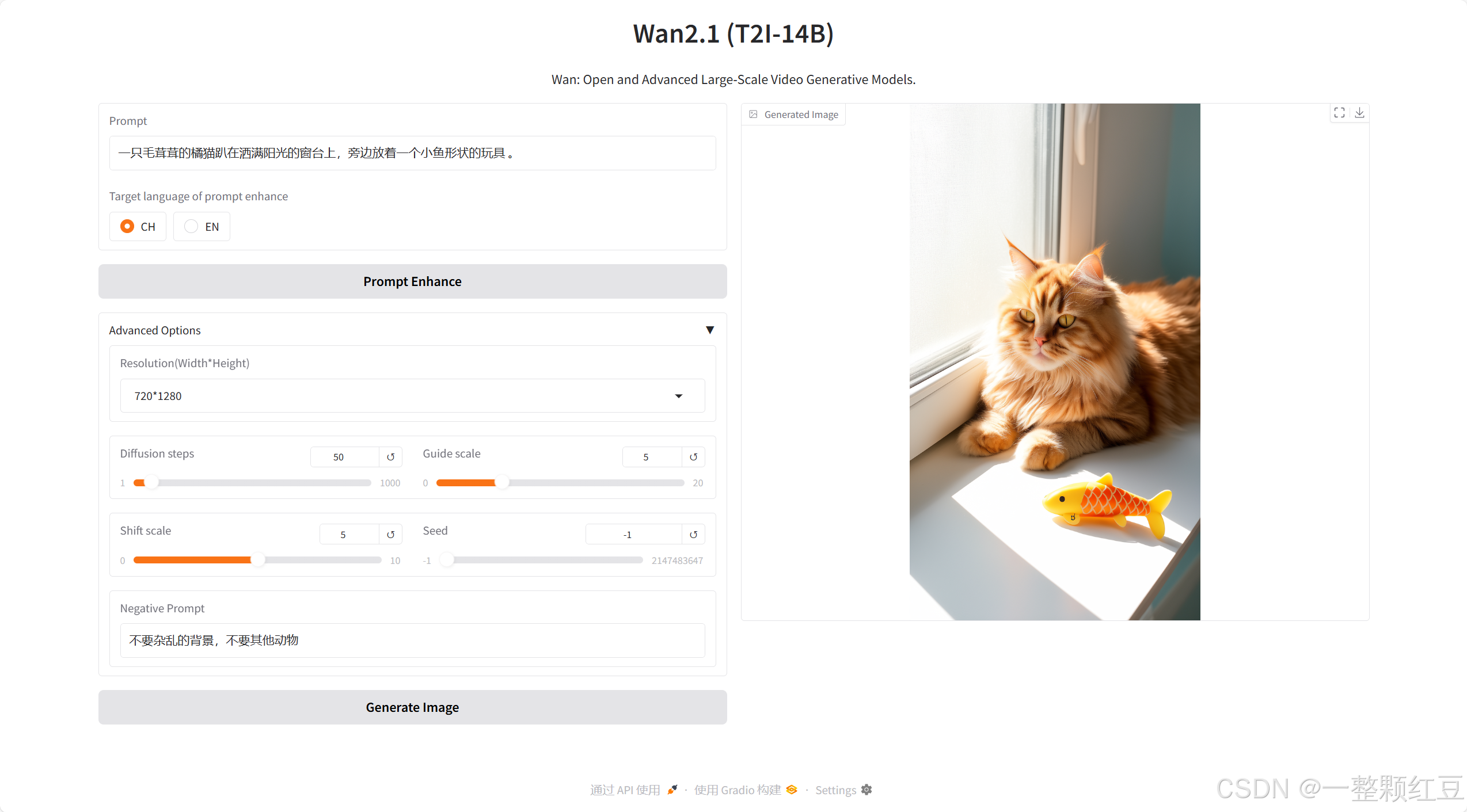
经过这个例子,我们看到蓝耘GPU平台的通义万相2.1的实力还是很在线的,我们继续来几个例子带大家感受一下其功能的强大
功能测试
自然风光类
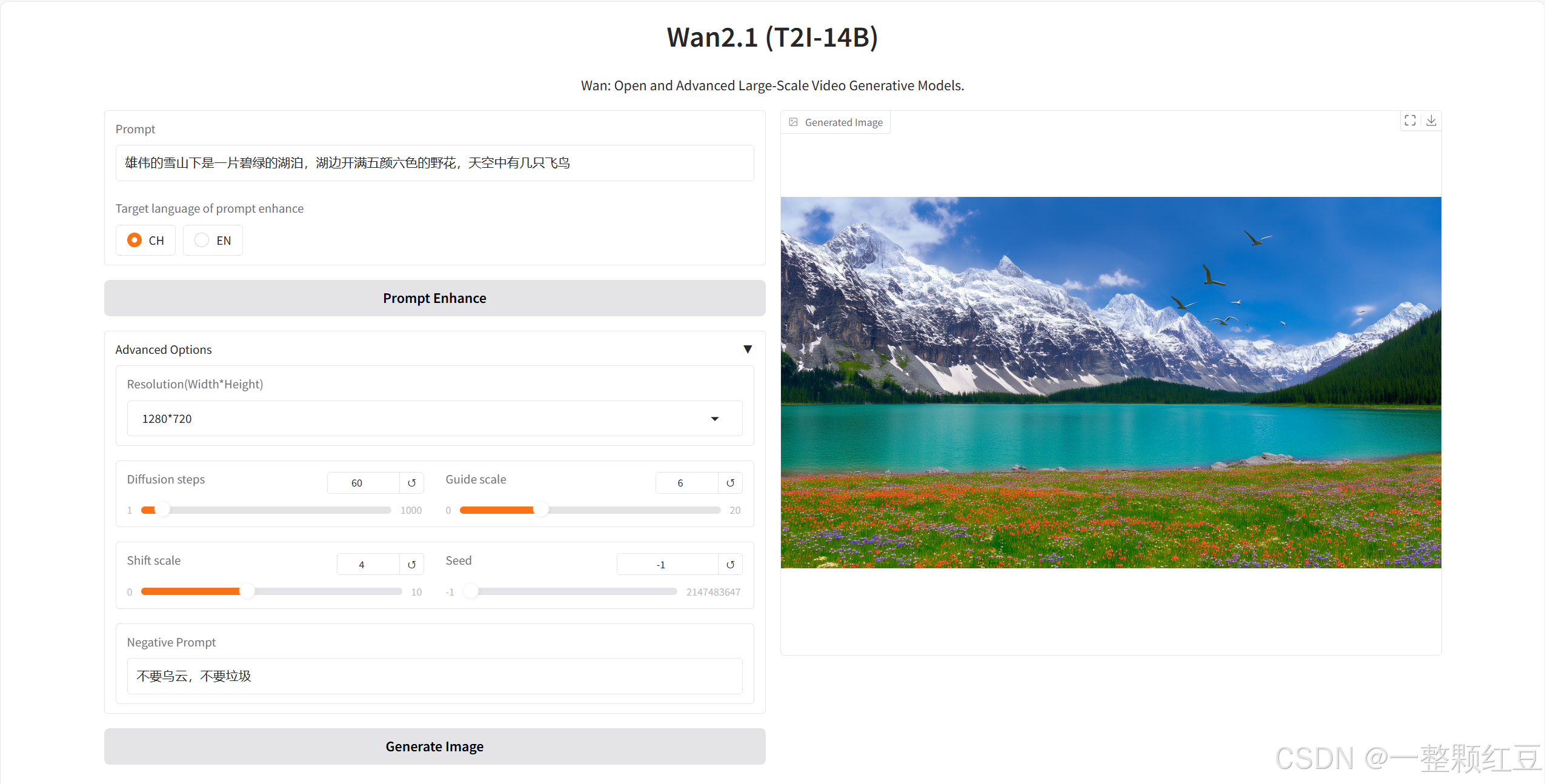
- 提示词(Prompt):在 “Describe the image you want to generate” 中输入
“雄伟的雪山下是一片碧绿的湖泊,湖边开满五颜六色的野花,天空中有几只飞鸟”。 - 提示词语言选择:选 “CH” 。
- 高级选项:分辨率选 “1280*720” ,扩散步数设为 “60” ,引导尺度设为 “6” ,Shift 尺度为 “4” ,随机种子填 “-1” ,负向提示词写 “不要乌云,不要垃圾” 。
然后点击生成,等待后我们查看效果:

科幻场景类
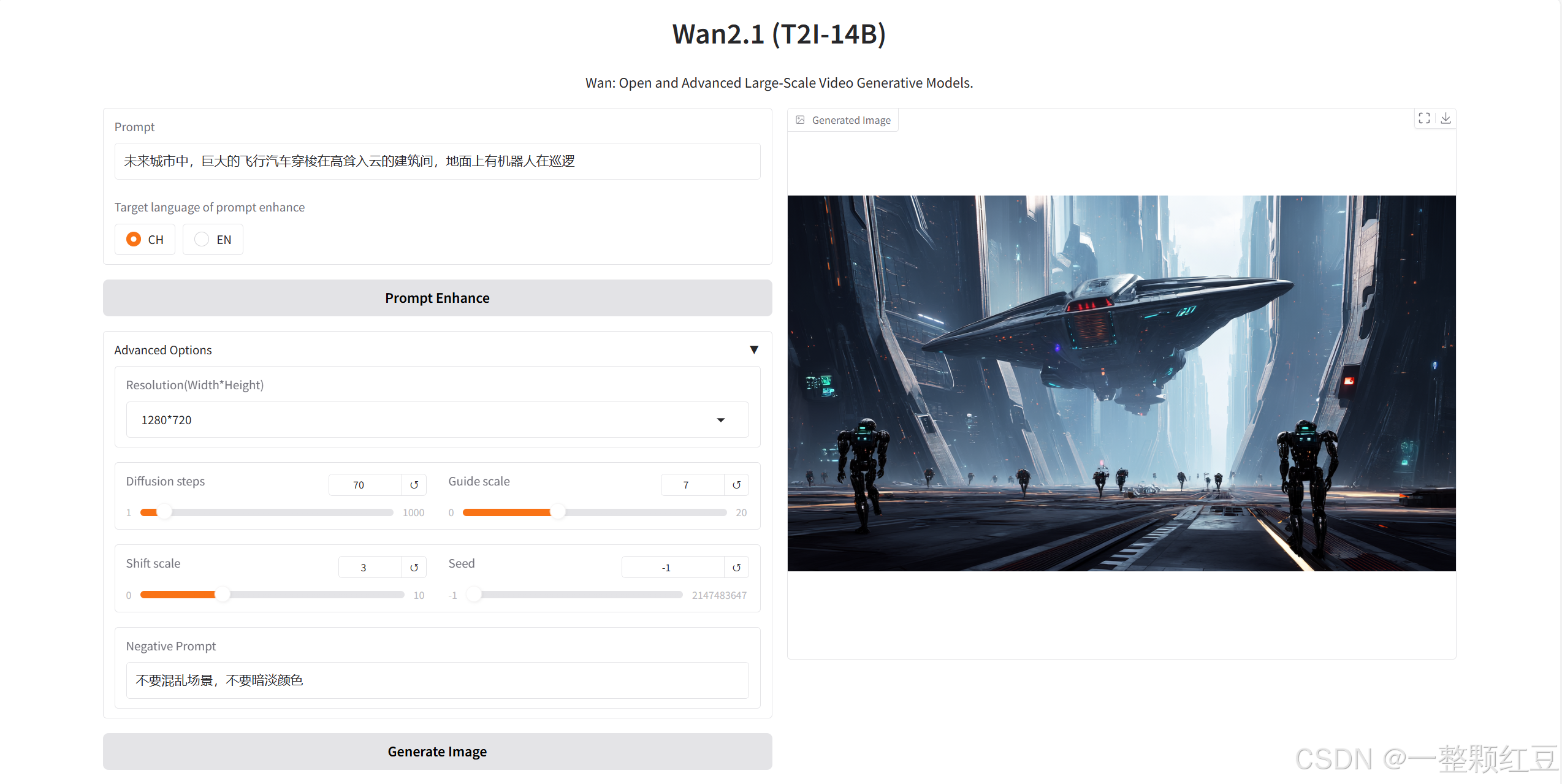
- 提示词(Prompt):输入 “未来城市中,巨大的飞行汽车穿梭在高耸入云的建筑间,地面上有机器人在巡逻”。
- 提示词语言选择:选 “EN”(若用英文提示词) 。
- 高级选项:分辨率选 “1280*720” ,扩散步数设为 “70” ,引导尺度设为 “7” ,Shift 尺度为 “3” ,随机种子填 “-1” ,负向提示词写 “no chaotic scenes, no dim colors”(不要混乱场景,不要暗淡颜色)。
效果图如下:

复古人文类
- 提示词(Prompt):输入 “老上海的弄堂里,一位身着旗袍的女子撑着油纸伞缓缓走过,墙面略显斑驳,地上有青苔”。
- 提示词语言选择:选 “CH” 。
- 高级选项:分辨率选 “960*960” ,扩散步数设为 “55” ,引导尺度设为 “5.5” ,Shift 尺度为 “4.5”,随机种子填 “-1” ,负向提示词写 “不要现代物品,不要明亮色彩” 。

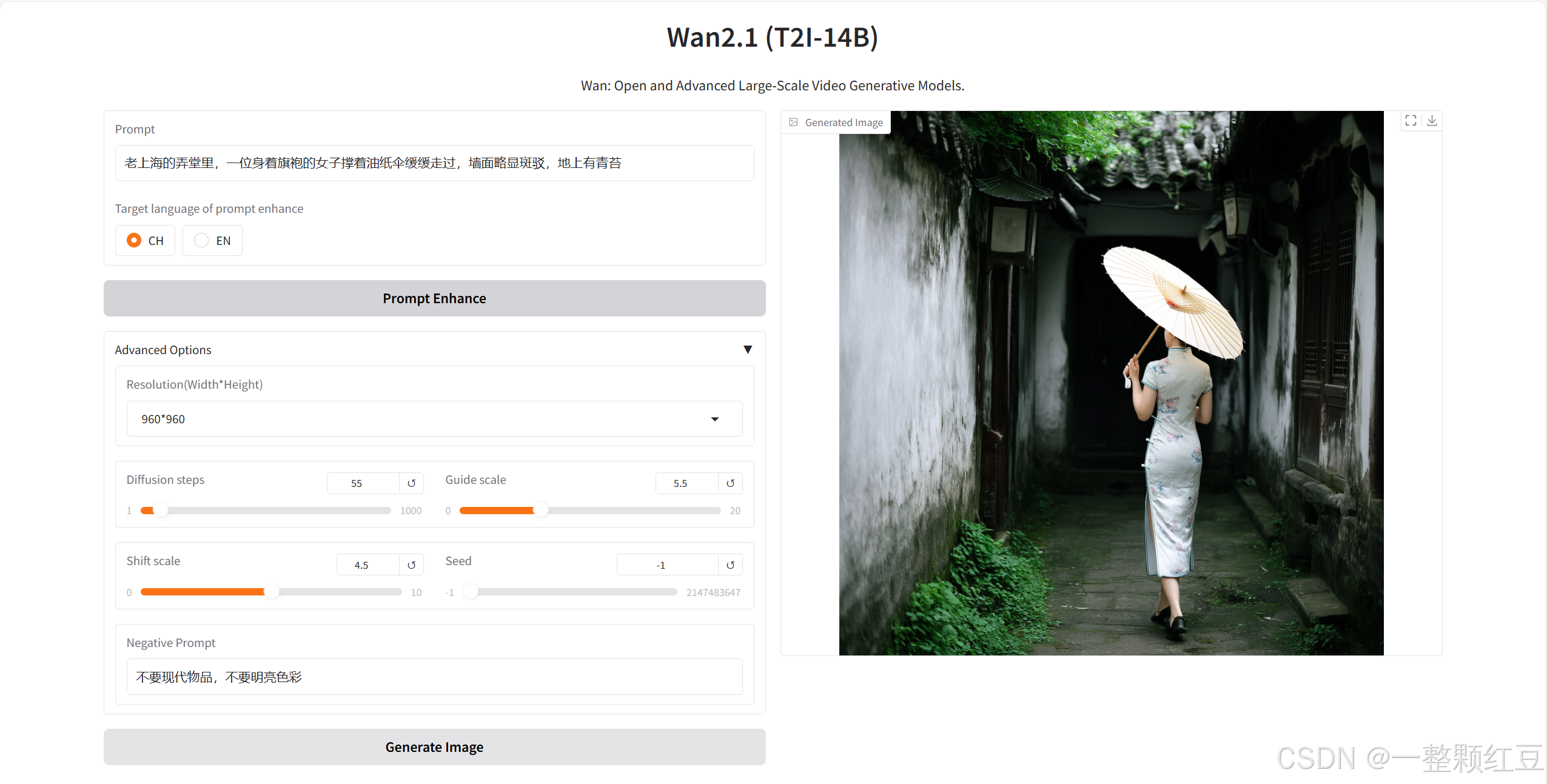
经过多轮测试下来,我们发现蓝耘GPU平台部署的通义万相2.1大模型还是非常强大的,生成的图片质量很高,分辨率也很高,速度也是非常快的,最重要的是同时也符合我们对图片的描述和预期,有强大的GPU算力支持也能发挥万象2.1大模型的多用途!
实际用途
那么我们通过蓝耘平台部署的通义万相2.1大模型生成我们具体描述的图片之后可以用来做什么呢?
- 艺术创作:可以作为绘画、插画的灵感来源,比如插画师借鉴画面的构图和色调,创作出新的作品;也能为摄影师提供场景和风格参考,进行类似主题的拍摄。
- 商业宣传:用于古风服饰、传统工艺品的广告宣传,凸显产品的古典韵味;民宿、古镇旅游景点也能用它来制作宣传海报,展现古雅氛围,吸引游客。
- 社交媒体分享:分享到朋友圈、微博等平台,展示对中式美学的欣赏,引发文化话题讨论,还能作为个人社交账号的背景图,彰显独特品味。
- 文字配图:为古风小说、散文等文字作品配图,帮助读者更直观地感受文中描绘的意境;也可用于文化类公众号文章,辅助内容表达,增强可读性。
例如:有一部小说,大家都知道小说是纯文字的,有些读者可能对女主角的倾国倾城的颜值无法想象,此时我们就可以通过通义万相2.1模型生成图片来满足你的要求!


本文总结
那么根据你的需求不同,万相2.1大模型的功能也会有所差别,要让它发挥最大的能力还要看我们如何去使用,根据具体提示词以及高级选项参数的不同,完全可以达到不同程度的要求,直到符合我们的需求为止!
那么本文到这里就结束了,有关蓝耘GPU平台部署和使用通义万相2.1大模型的具体操作相信你也已经学会了,快去使用如此强大的法宝完成你的修炼吧!我们下期再见!
写在最后:
蓝耘GPU平台注册链接:
https://cloud.lanyun.net//#/registerPage?promoterCode=0131



















 773
773

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











