




 Apache Flink是一个用于无界和有界数据流处理的框架,支持实时和记录数据流。它提供分层API,可在不同场景下灵活使用。Flink可以与常见集群资源管理器集成,以任意规模运行应用程序,并保证状态一致性。与其他框架如Spark相比,Flink在事件驱动应用、数据分析和数据管道应用中有独特优势。
Apache Flink是一个用于无界和有界数据流处理的框架,支持实时和记录数据流。它提供分层API,可在不同场景下灵活使用。Flink可以与常见集群资源管理器集成,以任意规模运行应用程序,并保证状态一致性。与其他框架如Spark相比,Flink在事件驱动应用、数据分析和数据管道应用中有独特优势。
Flink概述

flink是什么
Apache Flink是一个框架和分布式处理引擎,用于在无界和有界数据流上进行有状态计算。Flink被设计用于在所有常见的集群环境中运行,以内存中的速度和任何规模执行计算。
Unbounded streams VS Bounded streams
Unbounded streams 无界流有一个开始,但没有定义的结束。它们不会在生成数据时终止并提供数据。必须连续处理无边界流,即事件在被摄入后必须立即处理。等待所有输入数据到达是不可能的,因为输入是无界的,并且不会在任何时间点完成。处理无界数据通常需要以特定的顺序接收事件,例如事件发生的顺序,以便能够推断出结果的完整性。
Bounded streams 有界流有一个定义的开始和结束。在执行任何计算之前,可以通过摄取所有数据来处理有界流。处理有界流不需要有序摄取,因为有界数据集总是可以排序的。有界流的处理也称为批处理。
Unbounded streams VS Bounded streams图

streams
显然,streams是流处理的一个基本方面。但是,streams可以具有不同的特征,这些特征会影响streams的处理方式。Flink是一个多功能的处理框架,可以处理任何类型的流。
Bounded and unbounded streams=>有界和无界流:streams可以是无界的或有界的,即固定大小的数据集。Flink具有处理无界流的复杂功能,但也有专门的运营商来有效地处理有界流。
Real-time and recorded streams=>实时和记录的流:所有数据都作为streams生成。有两种方法可以处理数据。在生成时实时处理它或将流持久保存到存储系统(例如,文件系统或对象存储库),并在以后处理它。Flink应用程序可以处理记录或实时的流。
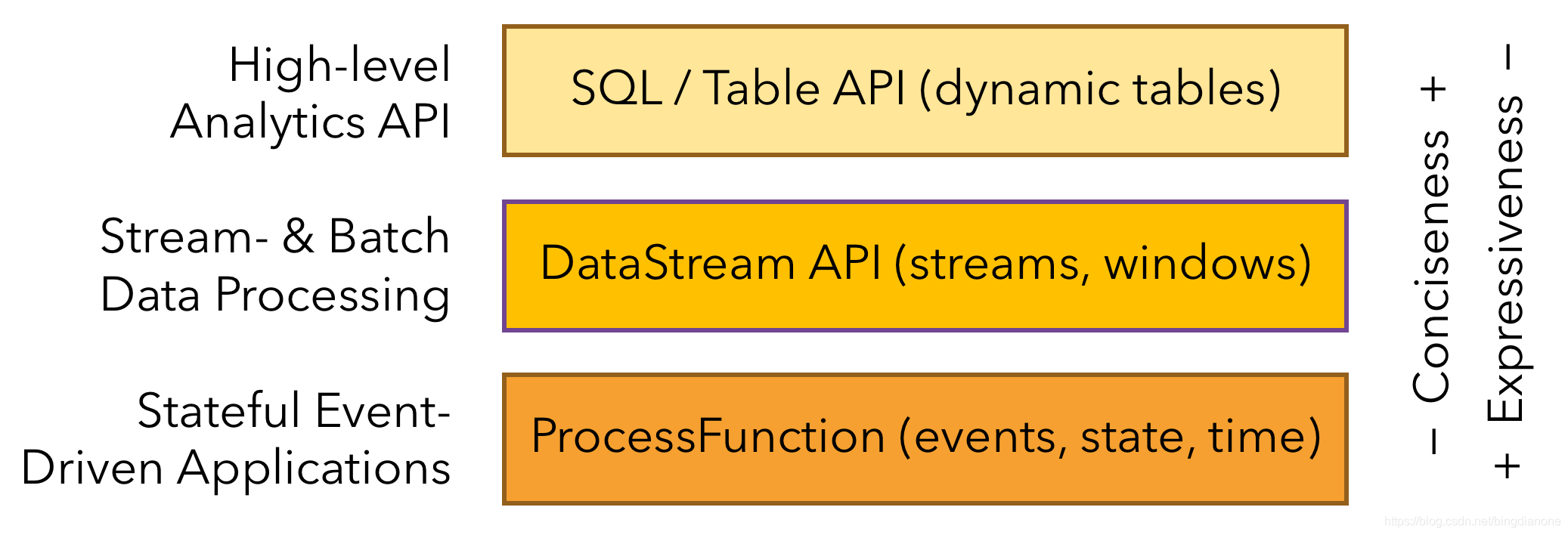
分层 API
Flink提供三层API。每个API在简洁性和表达性之间提供不同的权衡,并针对不同的用例。
部署应用程序的多样化
Apache Flink是一个分布式系统,需要计算资源才能执行应用程序。Flink与所有常见的集群资源管理器(如Hadoop YARN,Apache Mesos和Kubernetes)集成,但也可以设置为作为独立集群运行。
Flink旨在很好地运作以前列出的每个资源管理器。这是通过特定于资源管理器的部署模式实现的,这些模式允许Flink以其惯用方式与每个资源管理器进行交互。
部署Flink应用程序时,Flink会根据应用程序配置的并行性自动识别所需资源,并从资源管理器请求它们。如果发生故障,Flink会通过请求新资源来替换发生故障的容器。提交或控制应用程序的所有通信都通过REST调用进行。这简化了Flink在许多环境中的集成。
以任何规模运行应用程序
Flink旨在以任何规模运行有状态流应用程序。应用程序并行化为数千个在集群中分布和同时执行的任务。因此,应用程序可以利用几乎无限量的CPU,主内存,磁盘和网络IO。而且,Flink很容易保持非常大的应用程序状态。其异步和增量检查点算法确保对处理延迟的影响最小,同时保证一次性状态一致性。
与Spark框架对比
-
1.定位:
spark:流是批的特例(spark) flink:批是流的特例(flink) -
2.数据模型:
spark:Rdd集合,依靠lineage做恢复,存在宽窄依赖 flink:数据流和event的序列,依靠checkpoint做恢复,保证一致性 DAG: 来一条数据处理一条,传输到下一个节点,也可以优化批次处理,其中 ck(checkpoint)可以不用落盘,这样可以提高性能以及低延迟 -
3.处理模型:
spark: 支持各种数据处理,对机器迭代训练支持比较好(基于RDD本身模型) flink: 有状态的计算,尤其API层级多样,支持丰富 -
4.抽象层次:
spark: 一套API flink: DataSet和DataStream是独立API -
5.内存管理:
spark: java -> tungsten flink: 自己管理内存 -
6.支持语言:
spark比flink支持的丰富 -
7.SQL支持:
Spark比flink要好很多 -
8.外部数据源:
spark:nosql、orc、parquet。。。 flink:map/reduce、InputFormat
使用场景
Apache Flink因其丰富的功能集而成为开发和运行多种不同类型应用程序的绝佳选择。Flink的功能包括支持流和批处理,复杂的状态管理,事件时处理语义以及状态的一次性一致性保证。此外,Flink可以部署在各种资源提供者(如YARN,Apache Mesos和Kubernetes)上,也可以作为裸机硬件上的独立群集。配置为高可用性,Flink没有单点故障。Flink已被证明可扩展到数千个核心和太字节的应用程序状态,提供高吞吐量和低延迟,并为世界上最苛刻的流处理应用程序提供支持。
1.Event-driven Applications 事件驱动的应用程序
传统的应用程序和事件驱动的应用程序对比图
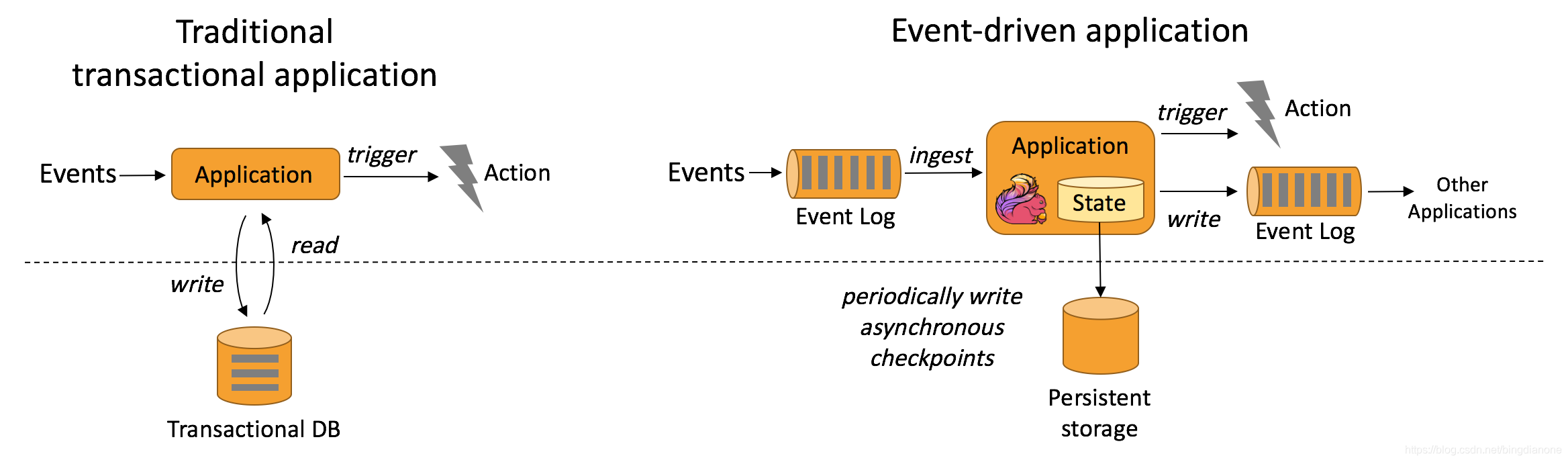
定义:
stateful app
checkpoints保证容错,录取remote data 做持久化存储
优势:
读取本地数据而非远程数据库
分层体系中多个应用可以共享一个数据库
如何支持:
有一些高级源语
支持time、window、processfunction..
savepoints:一个一致的映像文件
案例:
XX检测、web应用(社交网络)
2.Data Analytics Applications 数据分析应用
批量和流式分析应用程序
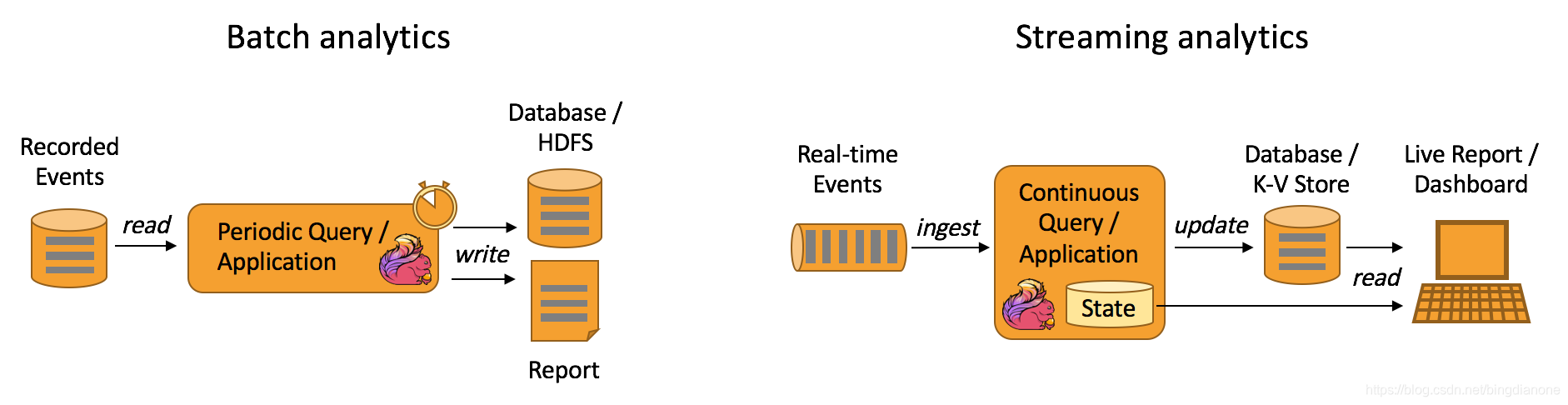
定义:
无界处理
依赖内部state做flink故障恢复机制
优势:
降低延迟
如何支持:
anis的sql接口,对于批处理和流处理提供了统一的语义
案例:
网络质量监控、大规模图分析
3.Data Pipeline Applications 数据管道应用
定期ETL作业和连续数据管道之间的差异
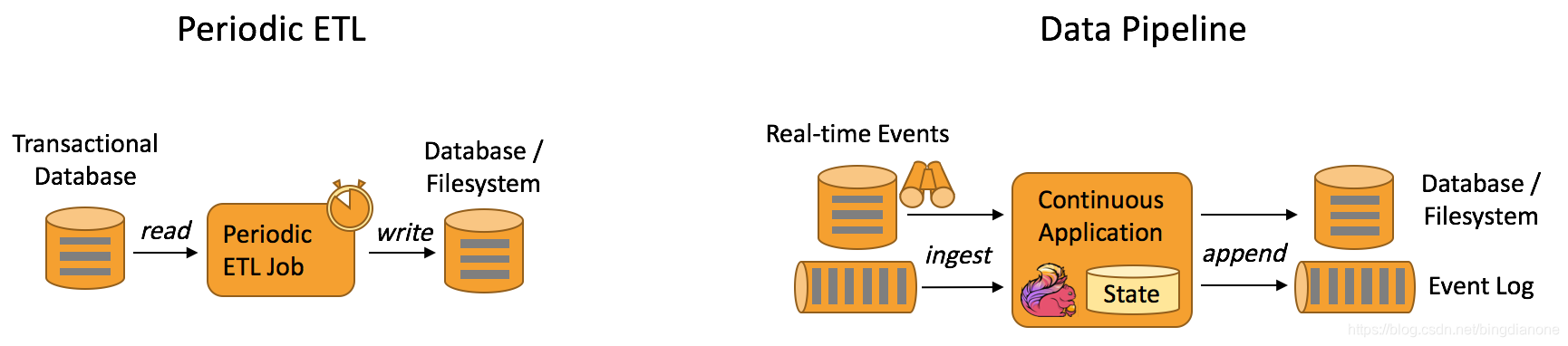
定义:
类似于etl,但并非周期性操作,而是连续性操作,这会降低目标间数据移动的延迟
优势:
降低延迟,更加通用
如何支持:
基于多层API结构以及多种多样的Connectors
案例:
电商的实时搜索的索引构建、电商的连续的ETL
Flink发展路线
主要参考官网的Roadmap;也就是flink的路线图
如下
https://flink.apache.org/roadmap.html

















 542
542

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









