







 该博客介绍了特征工程在文本分类中的应用,包括字典特征抽取、jieba分词和tf-idf文本抽取。同时,讲解了数据预处理的两种方法——归一化和标准化,并展示了主成分分析(PCA)在数据降维中的使用。这些技术对于机器学习模型的性能至关重要。
该博客介绍了特征工程在文本分类中的应用,包括字典特征抽取、jieba分词和tf-idf文本抽取。同时,讲解了数据预处理的两种方法——归一化和标准化,并展示了主成分分析(PCA)在数据降维中的使用。这些技术对于机器学习模型的性能至关重要。
1、特征工程
字典特征抽取
from sklearn.feature_extraction import DictVectorizer # 特征抽取的包
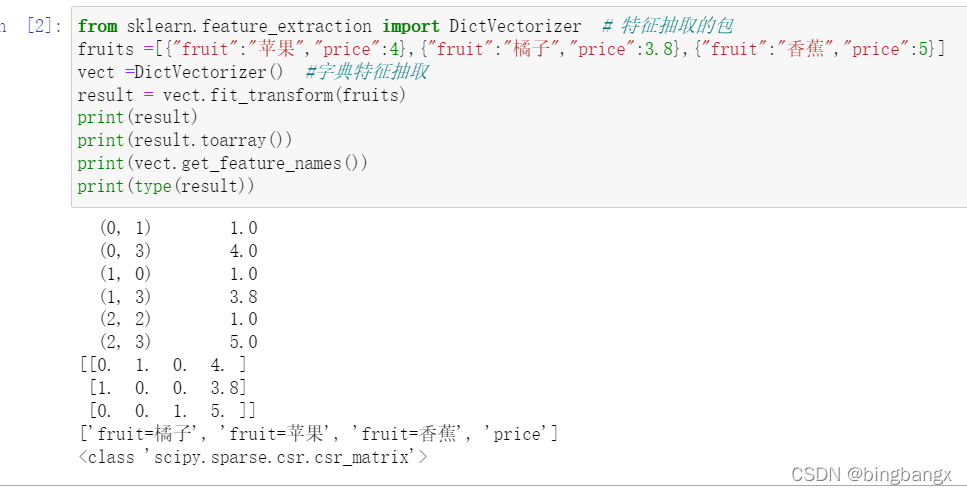
文本特征抽取和jieba分词
文本的特征抽取,比如说文档分类、垃圾邮件分类和新闻分类。文本分类是通过词是否存在、以及词的概率(重要性)来表示。

如果想要统计中文某些词出现的次数,就要先对中文进行分词。jieba
tf-idf文本抽取
是一种用于信息检索与文本挖掘的常用的加权技术,这种统计方法,用以评估一字一词在一份文件中的重要程度。
from sklearn.feature_extraction.text import TfidfVectorizer
特征工程~归一化
归一化
X=(x-min)/(max-min)
其中,max和min分别是某列的最大值和最小值,x为归一化之前的值。
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import MinMaxScaler
scaler =MinMaxScaler()
data =[
[180,75,35],[175,80,17],[159,50,46],[149,79,45]
]
result =scaler.fit_transform(data)
print(result)
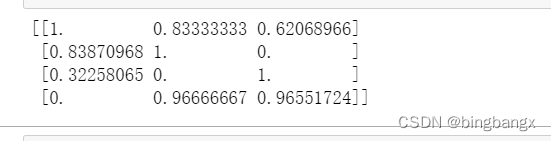
标准化
from sklearn.preprocessing import StandardScaler #标准化
scaler=StandardScaler()
result=scaler.fit_transform(data)
print(result)

特征工程-数据降维
主成分分析
主成分分析,是一种统计统计方法。通过正交变换将一组可能存在相关性变量的变量转换为一组线性不相关的变量,转换后的这组变量叫主成分。
主成分需要记住两点:
-
降维后的特征之间协方差为0,表示各个特征关系是独立的,每个特征都不会随着其他特征变化而有规律的变化。
-
每个特征的方差应尽可能大。
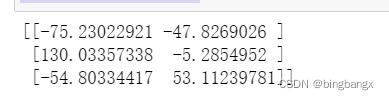
from sklearn.decomposition import PCA
def pca_decomposition():
pca=PCA(n_components=2)#1、0~1之间的,维度的比例-1;2、整形:具体的维度,必须为min(n_samples,n_features)以内
result =pca.fit_transform(
[
[4,2,76,9],
[1,192,1,56],
[34,5,20,90]
])
print(result)
pca_decomposition()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









