




 本文介绍如何根据需求自定义划分及使用随机方法划分机器学习的训练集和测试集,主要使用Python进行操作。训练集和测试集的样本分布已知,分别保存在CSV文件中,便于后续模型训练和验证。
本文介绍如何根据需求自定义划分及使用随机方法划分机器学习的训练集和测试集,主要使用Python进行操作。训练集和测试集的样本分布已知,分别保存在CSV文件中,便于后续模型训练和验证。
本部分是根据需求 自定义人为划分训练集和测试集,随机划分样本可见上一篇博客。
如有错误之处,欢迎批评指正~
因为是人为规定哪些样本是训练集,哪些样本是测试集,因此训练集和测试集不是随机的,是我们已知的。因此我将训练集和测试集分别放置在两个CSV文档中。
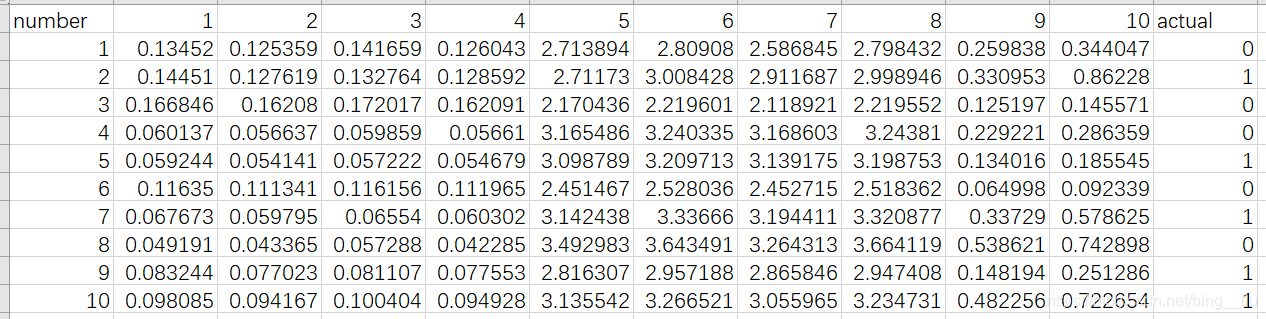
下图是训练集的部分原始数据。第一列是图像编号,中间列是图像特征,最后一列是图像的实际分类结果。(80张图像)
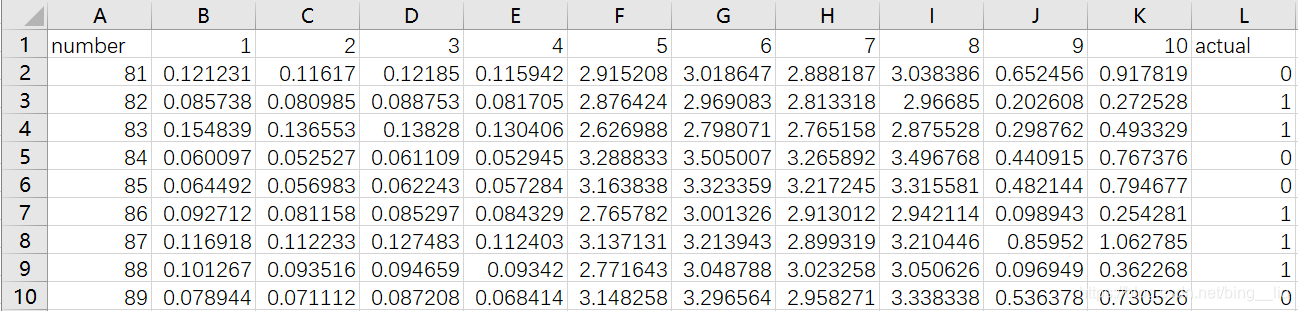
 下图是测试集的部分原始数据:(20张图像)
下图是测试集的部分原始数据:(20张图像)
实际运行过程中可以提前将number列也就是图像编号列给删去,这里为了方便大家理解,就不删除啦~~
代码如下:(我用anaconda实现的哦~)
import pandas as pd
import numpy as np
#将训练集和测试集分别放在两个CSV文件中,并分别读取。
train=pd.read_csv('data-train.csv')
test=pd.read_csv('data-test.csv')
#定义训练集与测试集中的特征和分类结果
y_train=np.array(train['actual'])
x_train=train.drop('actual',axis=1)
y_test=np.array(test['actual'])
x_test=test.drop('actual',axis=1)
print(y_train.shape,x_train.shape,y_test.shape,x_test.shape)
上部分代码的运行结果:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1912
1912




 到【灌水乐园】发言
到【灌水乐园】发言







