







 超级会员免费看
超级会员免费看
 本文探讨了高并发场景下服务器选择的策略,重点分析了HotSpot VM和JVM参数优化,强调了架构和代码调优的重要性。在服务器配置中,建议在高QPS压力下选择8C16G的配置,并使用G1垃圾收集器。此外,文章还详细介绍了CMS和G1收集器的特性和适用场景。
本文探讨了高并发场景下服务器选择的策略,重点分析了HotSpot VM和JVM参数优化,强调了架构和代码调优的重要性。在服务器配置中,建议在高QPS压力下选择8C16G的配置,并使用G1垃圾收集器。此外,文章还详细介绍了CMS和G1收集器的特性和适用场景。
一、服务器选择
1.1 服务器选择的场景
以商品详情页加载为例


- 非夜间QPS 20万-100万,每天晚上8-11点是高峰
- 加载逻辑
- 1、商品分模块组装:商品图文、商品颜色尺码选项、价格、库存、标签、会员信息、历史购买记录等
- 2、部分模块查询本地缓冲,如果有直接返回,如果下一步远程查询
- 3、并行RPC远程查询,设置总等待时间,必要内容(如图文、颜色尺码、价格)在总等待时间内查询到,即可返回给用户
- 4、异步对第3步PRC查询结果,按照数据变化频率,针对性设置本地缓冲(不同模块过期时间不一样)
- 商详查询的逻辑概括如下
- IO密集:大部分是IO,CPU多数时间在等待IO返回。极小部分是逻辑处理组装
- 内存占用高,大量使用了本地缓冲
1.2 不同服务器配置对比
- 50W QPS 稳定压力下,不同配置表现差异比较大
- 依赖的接口,暂时认为性能稳定
- 总的POD机器资源一样,都是240C480G
| POD配置 | TOMCAT | JVM | 效果 | 打分 |
|---|---|---|---|---|
| 4C8G*60台 | 100-300 Thread | CMS 80%内存,新生代500M 老年代5G |
接口RT波动大,YGC频繁,出现长达十几秒的FULLGC 调整新生代1G后,FULLGC频率降低,未出现1s以上FULLGC | 60分 |
| 8C16G*30台 | 300-600 Thread | G1 85%内存,MaxGCPauseMillis=200 |
接口RT波动性小于4C8G FULLGC概率大幅度降低,未出现1s以上FULLGC | 90分 |
- 从40万QPS ,2分钟内升到80W QPS,不同配置表现差异巨大
| POD配置 | TOMCAT | JVM | 效果 | 打分 |
|---|---|---|---|---|
| 4C8G*60台 | 100-300 Thread | CMS 80%内存,新生代500M 老年代5G | 前后接口性能波动巨大,错误率明显增大,FULLGC较长 | 50分 |
| 8C16G*30台 | 300-600 Thread | G1 85%内存,MaxGCPauseMillis=200 | CPU高位时长、接口性能波动范围、报错率,都远小于4C8G | 90分 |
1.3 总结POD不同配置差异
- 如果日常单POD 每秒 QPS压力在1万+,特别是8-10万+,建议选择8C16G + G1版本
- 优势:
- 常驻线程多,创建线程开销减少(通过TOP命令 或 Jstack观察线程可以发现)
- 内存和CPU 弹性更大,特别是内存 8G用6G,16G可以用14G,GC影响降低了很多
- 如果单POD QPS 不到1W,且整体比较稳定 4C或8G都可以
二、HotSpot VM
在2006年的JavaOne大会上,Sun公司宣布最终会把Java开源,并在随后的一年,陆续将JDK的各个部分(其中当然也包括了HotSpot VM)在GPL协议下公开了源码, 并在此基础上建立了OpenJDK。HotSpot VM便成为了Sun JDK和OpenJDK两个实现极度接近的JDK项目的共同虚拟机。
本文后续内容,都是基于HotSpot VM探讨。
三、JVM 参数
本文基于JDK 8+ 讨论JVM参数配置
2.1 优化JVM前要遵循原则
优先架构调优和代码调优,大多数导致GC问题的原因, 是代码层面的问题导致。JVM优化是不得已的手段。
- 架构调整
- 应用上线之前,先将机器的JVM参数设置到最优
- 代码调优
- 减少不受限制,创建对象的数量(代码层面)
- 减少使用全局变量和大对象(代码层面)
2.2 GC选择
没有最好的垃圾收集器,更加没有万能的收集器,只能选择对具体应用最合适的收集器。
2.2.1 HotSpot虚拟机包含所有收集器
大家主要掌握CMS 和 G1
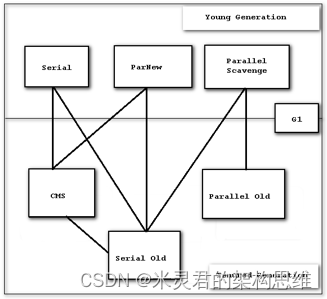
- Serial收集器,适用于Client模式下java应用。
- ParNew 收集器其实就是Serial收集器的多线程版本
- Parallel 吞吐量优先的并行收集器 ,适合后台运算无需太多交互的任务,Server模式下的默认垃圾收集器。
- Serial Old,Serial收集器的老年代版本,是一个单线程收集器,使用“标记-整理算法”。
- Parallel Old,Parallel收集器的老年代版本,使用多线程和“标记-整理”算法,在注重吞吐量以及CPU资源敏感的场合,都可以优先考虑Parallel 收集器+Parallel Old收集器的组合
- ConcMarkSweep 响应时间优先的并发收集器 ,适用于互联网站或者B/S系统的服务端上。基于“标记-清除”算法实现的。
- G1 分区收集 , JDK 7 Update 4后开始进入商用。
- 在G1收集器之前的其他收集器,进行收集的范围都是整个新生代或者老年代,而G1收集器整个Java堆分为多个大小相等的独立区域(Region),虽然还保留有新生代和老年代的概念,但新生代和老年代不再是物理隔离的了,它们都是一部分Region的集合。
- G1收集器跟踪各个Region里面的垃圾堆积的价值大小,在后台维护一个优先列表,每次根据允许 的收集时间,优先回收价值最大的Region(这也是Garbage-First名称的由
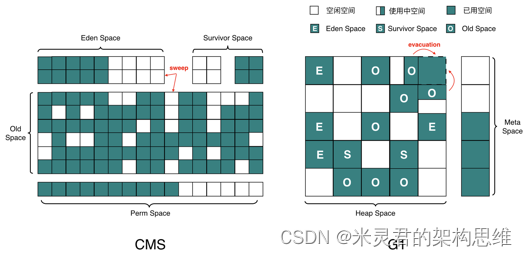
2.2.2 CMS 和 G1 二者结构
虽然设计结构差异很大,单依然保留了分代的概念
2.2.3 判断GC的两个核心指标
- 延迟(Latency): 也可以理解为最大停顿时间,即垃圾收集过程中一次 STW 的最长时间,越短越好,一定程度上可以接受频次的增大,GC 技术的主要发展方向。
- 吞吐量(Throughput): 应用系统的生命周期内,由于 GC 线程会占用 Mutator 当前可用的 CPU 时钟周期,吞吐量即为 Mutator 有效花费的时间占系统总运行时间的百分比,例如系统运行了 100 min,GC 耗时 1 min,则系统吞吐量为 99%,吞吐量优先的收集器可以接受较长的停顿。

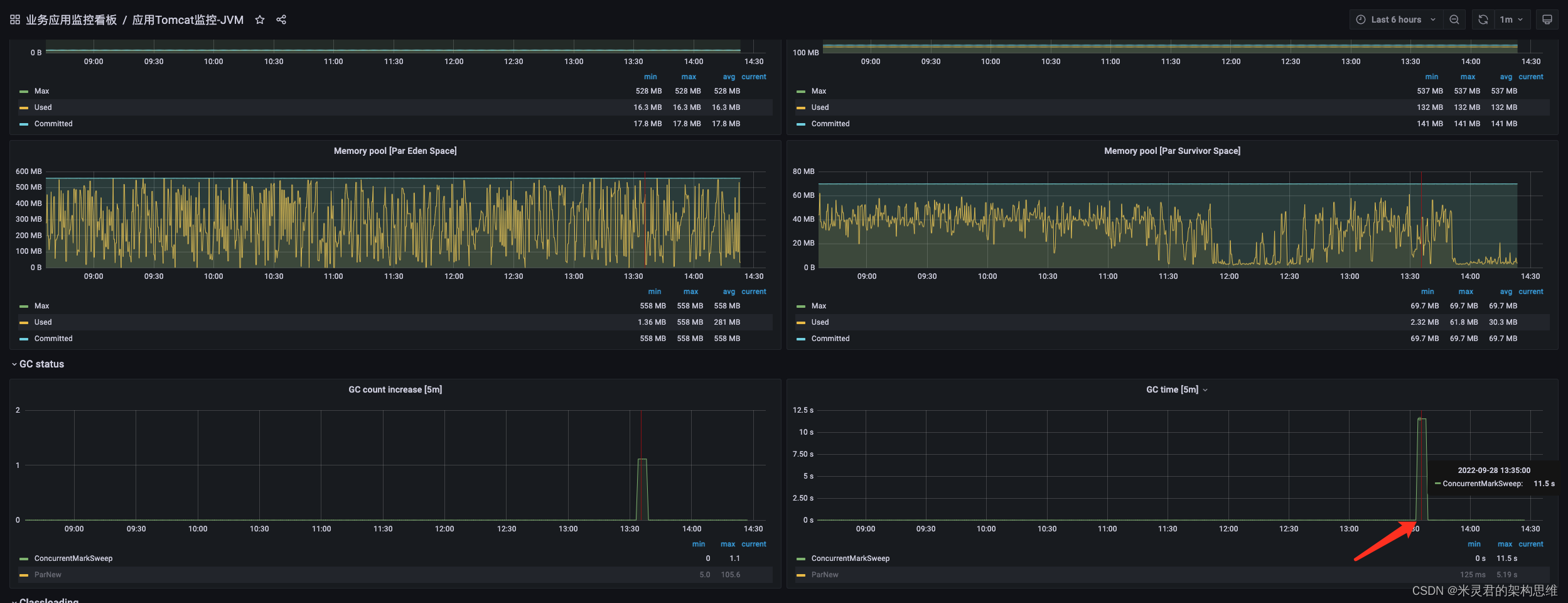
2.3 8G\16G内存 GC配置
8G内存,CMS和G1均可以
注意CMS的话,特别是有本地缓冲的系统,新生代最好达1G-2G,太小会导致大量内存直接进入老年代
老年代的fullgc特别频繁,且容易出现超长的fullgc
如下图1:fullgc耗时长
2.3.1 8G内存CMS 线上配置
注意不了解的参数不要调整
-Xmn2048M
-XX:MetaspaceSize=256M
-XX:MaxMetaspaceSize=256M
-XX:SurvivorRatio=8
-XX:MaxTenuringThreshold=8
-XX:CMSInitiatingOccupancyFraction=80
2.3.2 16G内存推荐的G1 线上配置
-XX:MaxRAMPercentage=85.0
-XX:InitialRAMPercentage=85.0
-XX:MinRAMPercentage=85.0
-XX:+UseG1GC
-XX:MaxGCPauseMillis=200
-XX:+ParallelRefProcEnabled
-XX:+PrintGCDetails
-Xloggc:/home/ops/logs/tomcat_gc.log
-XX:+PrintGCDateStamps
2.4、JVM常用命令
本文章节2.3 给出的JVM配置,需要我们结合实际情况持续调优。JVM常用命令整理如下:
jps: 输出JVM中运行的进程状态信息
jstack:查看某个Java进程内的线程堆栈信息
jmap:用来查看堆内存使用状况
jstat:JVM统计监测工具
jhat:与jmap搭配使用,用来分析jmap生成的dump
top :实时动态地查看LINUX系统的整体运行情况
本专栏会在工具篇>> Linux 和 JVM工具中专门介绍,此处不做进一步讲解。


















 219
219





 到【灌水乐园】发言
到【灌水乐园】发言









