




 该文介绍了FlowNet在光流估计中的应用,FlowNet通过CNN学习计算两帧图像间的光流。FlowNetSimple直接堆叠图像进行处理,而FlowNetCorr则通过相关层对比特征差异。文章指出,虽然FlowNet速度较快,但准确度有待提高。网络结构采用先压缩后恢复分辨率的设计,加入压缩过程中的特征以保持信息多样性。在Refinement阶段,利用反卷积层恢复分辨率并结合高层信息。整个流程旨在平衡速度与精度,同时利用不同层次的特征。
该文介绍了FlowNet在光流估计中的应用,FlowNet通过CNN学习计算两帧图像间的光流。FlowNetSimple直接堆叠图像进行处理,而FlowNetCorr则通过相关层对比特征差异。文章指出,虽然FlowNet速度较快,但准确度有待提高。网络结构采用先压缩后恢复分辨率的设计,加入压缩过程中的特征以保持信息多样性。在Refinement阶段,利用反卷积层恢复分辨率并结合高层信息。整个流程旨在平衡速度与精度,同时利用不同层次的特征。
简介
- 使用CNN需要大量数据,所以需要人工生成大量数据。但是Flying Chairs数据库有几个缺点。
- 缺少微小位移的样本
- 样本没有考虑光照的影响,只做了平移、旋转、缩放变换
- 样本缺少多样性
- 这个方法的速度比传统方法块(每秒10帧),但是准确性不如传统方法。
网络结构
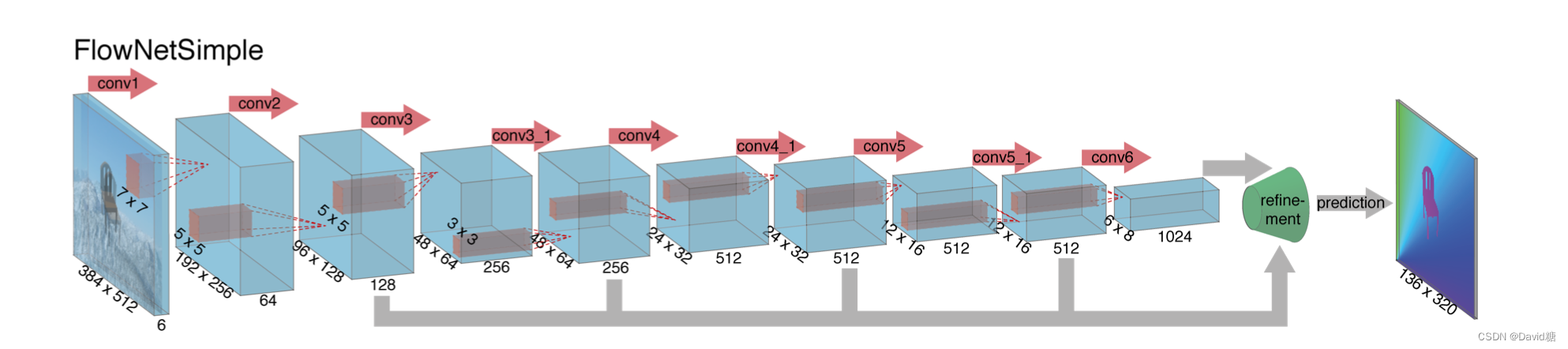
- 整体上先压缩(contractive),逐渐获取不同接受域的特征。
- 然后是逐渐 upconvolve 的过程,恢复原来的分辨率。
- upconvolve 过程中比较特别的是:会加入压缩过程中的特征。
- 问题:这个原理是不是ResNet比较像?
- 问题:具体是怎么加入压缩过程中的特征的?
- FlowNetSimple
- 将两帧图片堆叠,其他的和传统的CNN没有区别,让CNN自己学习如何计算光流
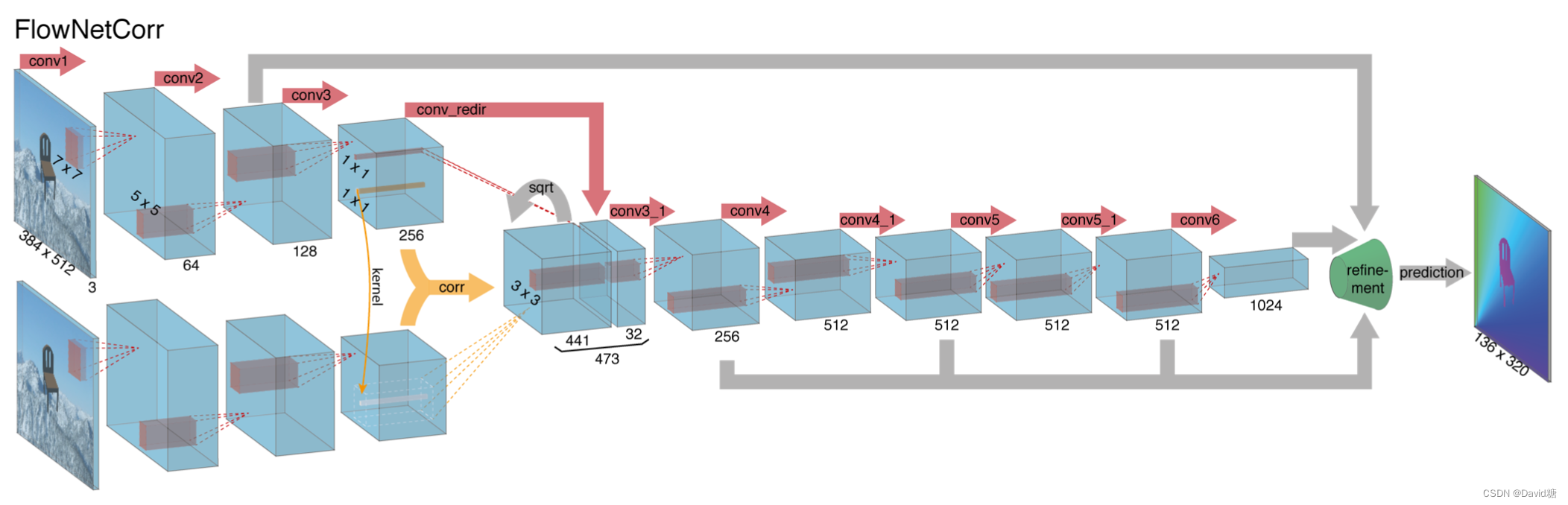
- FlowNetCorr
- 第一阶段两帧图片分贝提取特征
- 然后通过相关层(correlation layer)对比它们的差异
- 同样是先压缩后 upconvolve,并在upconvolve中加入前面的特征
correlation layer
- 这个层的输入是两个 feature map,命名为f1、f2,shape: w(宽度)h(高度)c(channel数量)
- 我们现在对比 f1 中的点 x1 与 f2 中的点 x2 的相关性
- 首先选定x1、x2 周围的一片区域,令区域的长和宽都是 2K+1
- 将这个两个区域中所有的点相乘,得到 c(x1 , x2 ) ,这个计算结果体现了两个区域的相似性
- 如果要将点 x1 与 f2 中的所有点做c(x1 , x2 ) 运算那么计算量过大,所以我们限定一个最大范围
- 例如这个最大范围是 D := 2d + 1 ,并且 x2 以stride=2的幅度移动,这个计算输出的结果是四维的,但是实际中我们我们压缩到三维(w × h × D^2)。
- 同时最终的计算结果还会加上上一层的 feature map
- 问题:这有什么作用呢?
- conv_redir: 通过
1*1*32的 filter 把256维的数据压缩到32维
Refinement
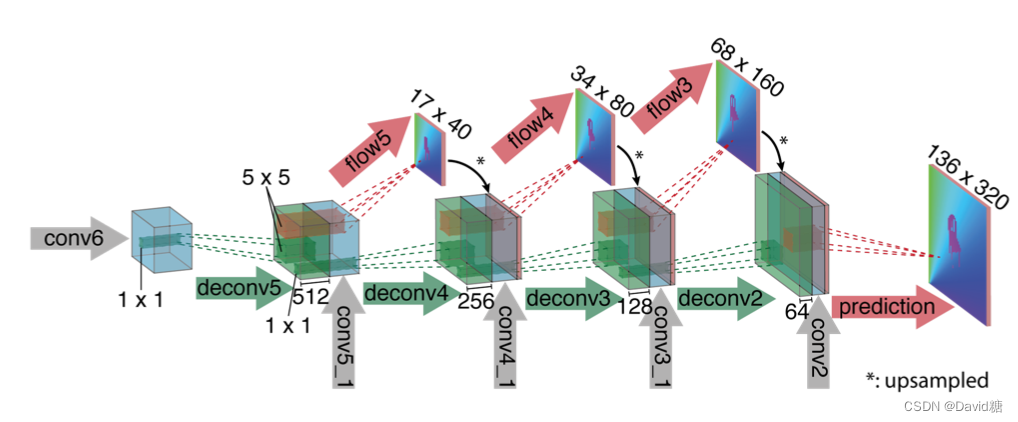
CNN 中的 Pooling 有利于提取高层的图片特征,并且减少计算量。但是分辨率大大降低,所以我们需要Refinement。
‘upconvolutional’ layers
- 反卷机层主要包含一个 unpooling、一个 convolution。
- 绿色部分通过 unpooling 使得分辨率翻倍
- 蓝色部分从收缩过程中复制
- 红色部分是卷机过程,输入是绿色和蓝色部分取一个patch,然后通过5*5的 filter 生成一个 flow 预测
- 最后一步 prediction 直接生成最终的 flow
- 问题:每一步 filter 的大小都是 5*5 吗?
- upconvolutional应用于 feature map
- 并且 refine 的过程中也加入了收缩过程中的 feature map,和经过 upsampled 的光流估计
- 这么做的好处是同时保留了高层和底层的信息
- 每一次 upconvolutional 使得分辨率翻倍,这样重复四次,此时分辨率是输入的四分之一。
- 之后使用计算更快的 bilinear upsampling 提升分辨率

















 9015
9015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









