




01. 前言
现实世界的数据普遍存在长尾分布特性,绝大多数样本集中于少量头部类别,而大量尾部类别仅拥有极少量样本数据。尽管传统分类方法在平衡数据集上表现优异,但在面对长尾数据时往往过度偏向多数类而忽视少数类识别。针对这一挑战,学界提出的解耦训练范式(Decoupled Training)[1]通过特征学习和分类器再训练两阶段分离的方式取得了显著进展。现有研究多侧重同时改进特征提取与分类器优化,使得难以准确评估分类器优化的独立贡献。最新研究文献[2]表明,简单的正则就可以得到一个鲁棒的特征表示,基于该泛化的特征表示单凭分类器再训练即可超越前面所有复杂方法。因而,我们需要对分类器再训练阶段的方法统一基准,进行分析比较从而挖掘真正有效提升模型性能的因素。
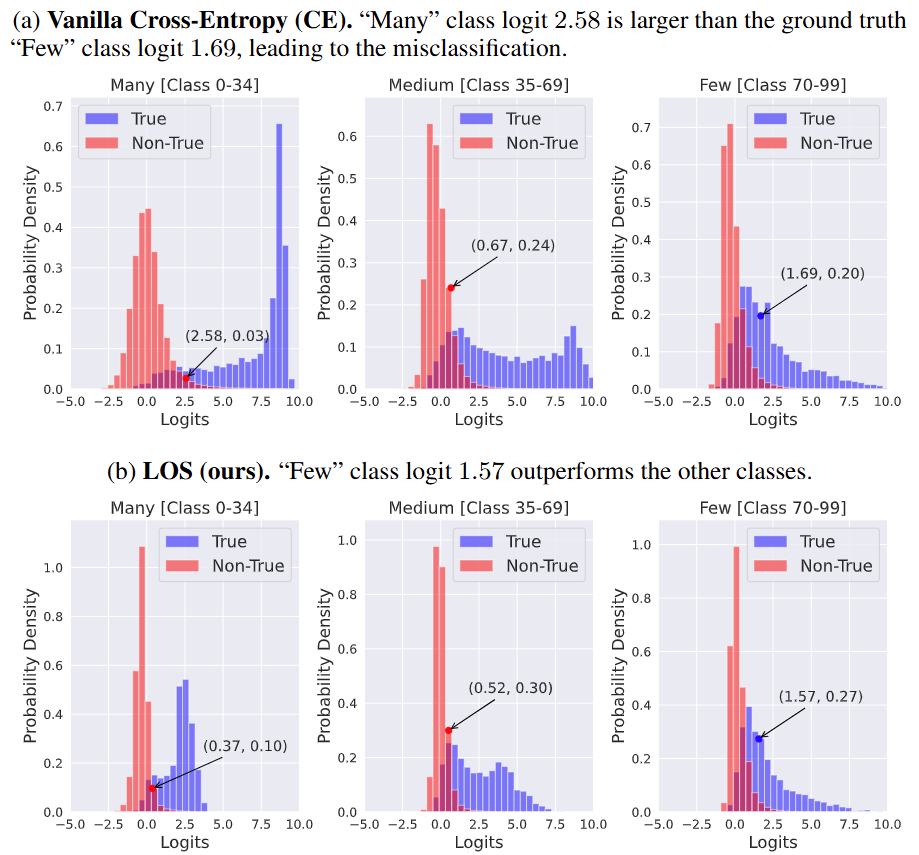
图1:Logits Magnitude指标影响的直观理解。基于同样的特征表示,样本类内的区分度变化不大,但是类间的Logit Magnitude在我们LOS方法下更加平衡,有效减少了头部类对于尾部类的干扰
近日,哔哩哔哩Index团队联合上海交通大学系统重新构建了主流的分类器再训练方法(包含重加权、重采样、参数正则化等),提出了两个创新评价指标——Logits幅度(Logits Magnitude, LoMa)与正则化标准差(Regularized Standard Deviation)。前者对于每个类别计算当前真实类与非真实类Logits均值差异,后者则将Logits的标准差对于LoMa进行正则。基准实验发现当LoMa在不同类别中更平衡可以获取更优的性能。在此发现基础上,我们创新提出标签过度平滑(Label Over-Smooth, LOS)方法,通过将原始one-hot标
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1383
1383

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









