




背景介绍
Shuffle 演进
随着B站业务的飞速发展,数据规模呈指数级增长,计算集群也逐步从单机房扩展到多机房部署模式。多个业务线依托大数据平台驱动核心业务,大数据系统的高效性与稳定性成为公司业务发展的重要基石。如图1,目前在大数据基础架构下,我们主要采用 Spark、Flink、Presto 以及 Hive 作为计算引擎支撑各类复杂业务场景需求,离线计算集群基本每天运行30+万左右的 Spark 作业,包括任务调度平台的 ETL 任务、Kyuubi 提交的 Adhoc 作业等,其作业的 Shuffle 数据规模能够达到30PB以上,同时单个作业的 Shuffle 量最大规模有几百TB。同时 Shuffle 算子作为大数据计算引擎中间数据处理最重要的算子,Shuffle 的稳定性关系着线上大量离线作业的可靠性和性能。因此,对于海量的 Shuffle 中间数据和复杂多变的计算环境来说,保证 Shuffle 数据处理的稳定性对线上作业的稳定性和运行效率尤为重要。
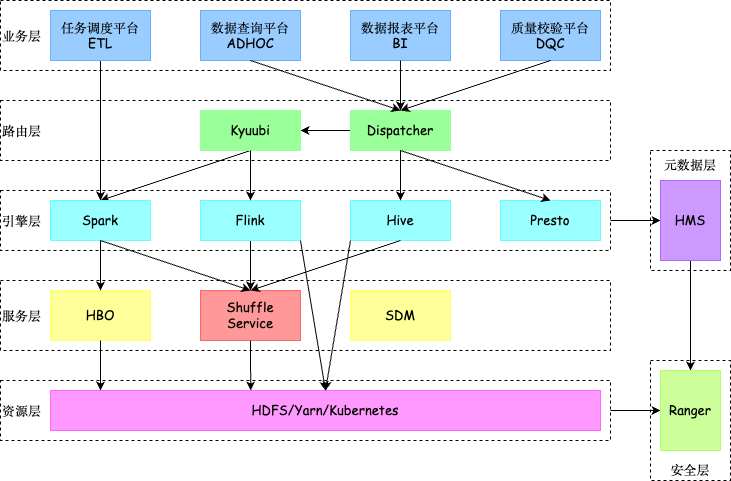
图1:B站大数据基础架构图
-
Local Shuffle 的早期引入
前期我们采用 Spark 社区官方提供 External Shuffle Service(ESS)方案,生产实践过程中,我们发现 Spark 任务运行过程中 ESS 有稳定性差的情况,主要表现在:
-
NodeManager, ESS, Datanode 同时部署,进程之间共享网络带宽,容易导致各组件之间互相影响,节点稳定性差。
-
高网络连接数:Shuffle Read 有大量的网络连接,逻辑连接数是M*N。对于 M*N 次的连接数而言,容易导致线程池消耗过多 CPU,影响作业的性能和稳定性。
-
大量随机读:Shuffle Read 存在大量的随机读盘,假设一个 Mapper 的 Shuffle 数据是 128M,Reducer 的并发是 2000,那么每个文件将会被读 2000 次,每次只随机读 64k,非常容易达到磁盘 IOPS 瓶颈,导致大量小粒度随机读,同时 HDD 盘随机读性能非常差;而 SSD 盘快速消耗磁盘寿命。
-
External Shuffle Service 集群无法弹性扩缩容,难以灵活应对热点数据的大任务。
-
Executor 只会将数据写入其本地存储,并且不会跨多个节点复制数据,意味着如果与 Executor 共存的 Shuffle 服务崩溃,则此节点上所有 Executor 写入的 Shuffle 数据都会丢失,每个在该节点上写入 Shuffle 文件的 Stage 都需要重新计算,消耗额外计算资源。
-
Push Based Shuffle 的演进
中期为了降低 Fetch Failed Exception 造成的作业失败率,选择基于 Spark 社区提供的 Push-based Shuffle 方案,此方案的优缺点主要是:
-
优点:
1. 对 AQE 支持友好:Push-based Shuffle 方案天然支持 Spark 的动态查询执行(AQE),在分区重排和数据分布优化中表现优异。
2. 减少内存压力:通过将中间数据写入本地磁盘再异步推送到远程节点,减少内存占用。
-
缺点:
1. 写放大问题:由于需要先将数据写入本地磁盘,整体的 I/O 开销有所增加,尤其对小任务不够友好。
2. 冷启动问题:作业启动时,Driver 管理的 Executor 数不足,导致可供选择的远程节点有限。SQL 作业中的数据量通常随过滤条件逐渐减少,但在初始 Shuffle 阶段可能因节点不足 Fallback 到原生 Shuffle 实现。
为了解决写放大以及冷启动问题,引入 Shuffle Service Master 节点,主要优化点包括:
-
Shuffle Master 的引入:
1. 注册和心跳机制:所有 External Shuffle 节点启动时都会向 Shuffle Master 节点注册,并且周期性上报心跳和节点的繁忙程度。
2. 集中化的节点管理:DAGScheduler 请求远程节点时,通过 Shuffle Master 动态分配节点,从而缓解冷启动时节点不足的问题,同时能够选择健康度更高的节点。
-
性能优化:
1. 基于任务画像的动态启用:
-
小任务由于等待时间的回退问题对性能影响较大,因此并不强制启用 RSS。
-
基于 HBO(History-based Optimization)系统对任务进行画像分析,仅对大任务启用 RSS。
2. 性能测试结果:目前大任务启用 RSS,任务平均执行时间缩短 25%,稳定性显著提升。
改进后 Push-based Shuffle Service 的主要流程如图2所示:
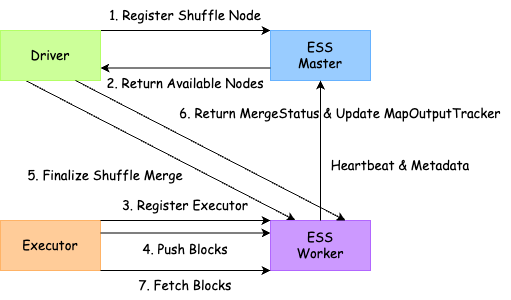
图2:优化后的 Push-based Shuffle Service 流程图
采用 Shuffle Service Master 优化的 Push-based Shuffle 方案能够带来以下收益:
1. 冷启动问题的解决:通过集中化的节点管理,作业启动时能快速分配健康节点,避免因节点不足回退到原始 Shuffle 模式。
2. 性能提升:大任务使用 RSS 后平均执行时间缩短 25%,有效应对高并发场景下的大数据处理需求。
3. 稳定性提高:动态节点分配和健康度监测显著提升服务的可用性。
B站通过上述优化的 Push-based Shuffle 方案基本解决 Spark 作业的 Shuffle 稳定性问题,但随着架构演进和对 Kubernetes 混部环境的适配需求,此方案的局限性逐渐显现,尤其是对本地盘的依赖成为无法支持存算分离的主要瓶颈,由此为了适配满足 Spark On Kubernetes 方案需求,尝试在生产环境使用主流开源 Remote Shuffle Service 实现方案。
最终我们选择了 Celeborn 主要关注以下几个方面:
1. Celeborn 开源社区活跃度相比其他开源 Remote Shuffle Service 实现方案更高。
2. Celeborn 源于阿里云自研的 EMR Remote Shuffle Service,具备良好的架构设计和稳定的生产实践输出。
3. 离线计算团队内部具备 Celeborn 的技术储备,技术演进代价相对较低。
4. 稳定性和性能方面具备流量反压控制、磁盘负载均衡、优雅滚动升级、支持多层存储、提供双副本机制等关键功能特性,以及异步化操作包括异步 Push、异步 Flush、异步 Commit 以及异步 Fetch 满足不论是在读写还是 Control Message 过程中不阻塞计算引擎处理要求。
5. 集成 Native 引擎比如 Gluten、Blaze 等,未来对B站向量化引擎演进大有裨益。
6. 使用云原生的 Push-Style Shuffle 代替 Pull-Style
Celeborn 概览
Apache Celeborn 是由阿里云捐赠给 Apache 软件基金会的开源大数据计算引擎通用 Remote Shuffle Service,旨在解决大数据引擎处理中间数据遇到的性能、稳定性及弹性问题,专注于处理中间数据提高中间数据的流转效率,从而提升 Shuffle 的性能、稳定性和弹性。Celeborn 的定位是大数据引擎统一中间数据服务,通过接管中间数据解决传统 Shuffle 问题。目前 Celeborn 已经在包括阿里云、小红书、Shopee、网易、LinkedIn 以及 Pinterest 等在内的多家国内外公司生产落地,同时 Celeborn 开源社区活跃度也非常高,吸引来自海内外开发者贡献功能特性,性能优化以及 Bugfix。
如图3所示,Celeborn 的整体架构采用典型的 Client-Server 架构,主要由 Master、Worker 以及 Plugin 三个重要部分组成,其中:
-
服务端包括:
1. Master 的主要职责是管理 Celeborn 集群状态,负责分配 Slot 负载,同时基于 Raft 协议实现高可用。
2. Worker 的主要职责是接收、存储和服务 Shuffle 数据,实现多层存储适配各种硬件环境。
-
客户端包括:
1. Lifecycle Manager 负责管理当前作业的 Shuffle Metadata,把 Shuffle 元数据从 Master 转移到 Celeborn Application,使得 Ap
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 687
687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









