




1. 前言
视频场景分类算法是计算机视觉领域研究的热门内容,并作为复杂任务系统的前置算法,能够应用于我们多媒体实验室多项业务,如内容自适应转码、画质智能修复和视频质量评估(VQA)中。通过针对不同类型的图像自适应抉择不同的模型,从而精准有效提升算法在业务中的实际效果。语言、视觉是人类感知世界最基本的方法,也是人工智能理解世界的两大支柱。多模态是结合了图像、文本、音频等多种数据类型的一种技术方案。该技术不仅提高了模型的泛化能力,还扩展了人工智能技术的应用方向,如图像分类、图像问答、文本图像生成等。本文研究了多模态算法在多媒体系统中进行场景分类的应用,探讨了实施过程中的挑战并给出对应的解决方案。
2. 背景
B站作为一个聚集了海量创作者投稿视频的社区,拥有丰富的多品类、多场景的优质视频内容。然而,随着用户年龄和兴趣圈层的不断扩展,UGC(User Generated Content,用户生成内容)视频内容五花八门,画质良莠不齐,这给多媒体分析与处理带来了极大挑战。以画质修复为例,多媒体系统会对视频画质进行增强处理,辅助改善用户的视频观看体验。由于同一个视频内可能会包含不同类型的场景,且不同场景画质质量差异较大,使用相同的增强方式处理不同场景往往不是最佳选择。因此,迫切需要一个能够识别和分类视频场景的前置算法,使多媒体系统根据场景特征自适应选择最合适的画质修复算法,从而实现更加精细和高效的画质增强处理。视频场景分类算法可以通过识别单帧图像特征进行分类来实现。
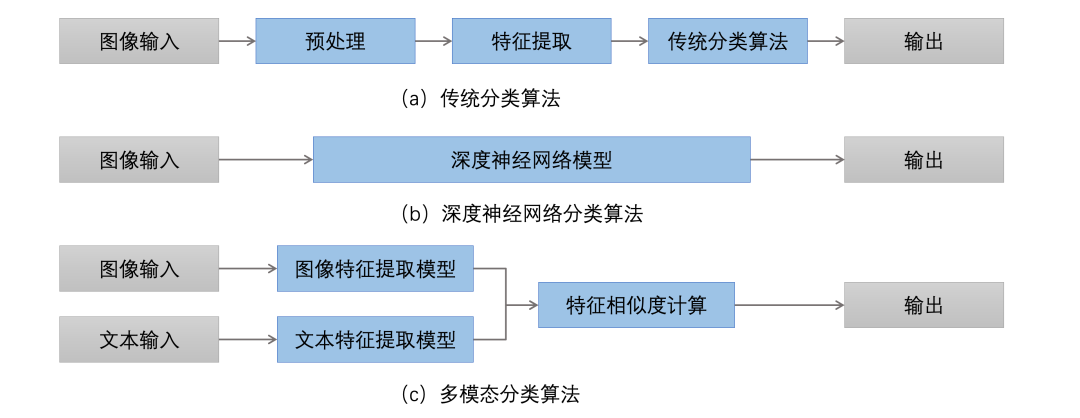
图1 图像分类算法简要流程
传统的图像分类方法通常使用 SIFT(Scale Invariant Feature Transform,尺度不变特征变换)、HOG(Histogram of Oriented Gradients,方向梯度直方图) 等技术,从图像中提取出关键信息,如颜色、形状和纹理。再使用SVM(Support Vector Machine,支持向量机)、决策树、随机森林、K近邻算法和朴素贝叶斯等方法对标注好的训练数据进行分类训练。尽管这些算法在某些任务上取得了较好的效果,但它们通常需要大量的手工调整和参数优化,且在处理大规模图像数据集时,性能有限。随着深度学习技术的快速发展,CNN(Convolutional Neural Networks,卷积神经网络)作为一种端到端(end-to-end)的模型,能够通过卷积、池化、全连接层等操作,从数据中学习到更加丰富的特征表示,无需手动设计特征和分类器,可以获得更好的分类效果。然而大多数基于深度学习的算法均需要大量的标签数据进行训练,而公开的数据集并不一定适合实际业务场景,因此需要人工收集和标注更适合业务场景的大规模数据集。
近年来,多模态算法成为解决特定问题或任务的重要研究方向。这类算法能够处理包括视觉、语音、文本在内的多种模态数据类型,并将这些数据映射到同一个空间域中。这种方式不仅提高了模型的泛化能力,还使得跨模态的分类算法成为可能,进一步扩展了人工智能在复杂应用场景中的应用潜力。同时,大模型的快速发展也使得预训练特征提取模型在各种应用场景成为可能。
3. 现有技术
图像分类是计算机视觉领域的核心任务,旨在将图像准确地分配到预定义的类别中。随着深度学习技术的快速发展,图像分类算法受
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 879
879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









