




 本文介绍了Spark的起源、特点、核心组件RDD及其特性,包括速度提升、易用性、通用性和兼容性。Spark Core中的RDD是Spark的核心,提供弹性分布式数据集,支持多种编程语言API,并具有容错能力。文章还概述了Spark集群结构和RDD的创建方式。
本文介绍了Spark的起源、特点、核心组件RDD及其特性,包括速度提升、易用性、通用性和兼容性。Spark Core中的RDD是Spark的核心,提供弹性分布式数据集,支持多种编程语言API,并具有容错能力。文章还概述了Spark集群结构和RDD的创建方式。
今日份总结:我们通过今天先来认识一下spark是什么,了解spark core以及rdd,并掌握一些常用的算子,今天不用知识点的概括去认识spark core,而是用问答的方式去引导知识点,更深入探究和认识。
一、spark是什么?
目标:通过了解spark的历史和产生原因,浅显了解spark的作用
spark历史:Spark 于 2009 年诞生于加州大学伯克利分校 AMPLab,2013 年被捐赠给 Apache 软件基金会,2014 年 2 月成为 Apache 的顶级项目。相对于 MapReduce 的批处理计算,Spark 可以带来上百倍的性能提升,因此它成为继 MapReduce 之后,最为广泛使用的分布式计算框架。
浅显小结:也就是说它是一个分布式计算框架,可能是为了取代mapreduce的计算的,那么问题来了,它为什么比mapreduce快?为什么要取代mapreduce?我们通过一张图来对比mapreduce和spark的区别,再总结一下大家就明白了。
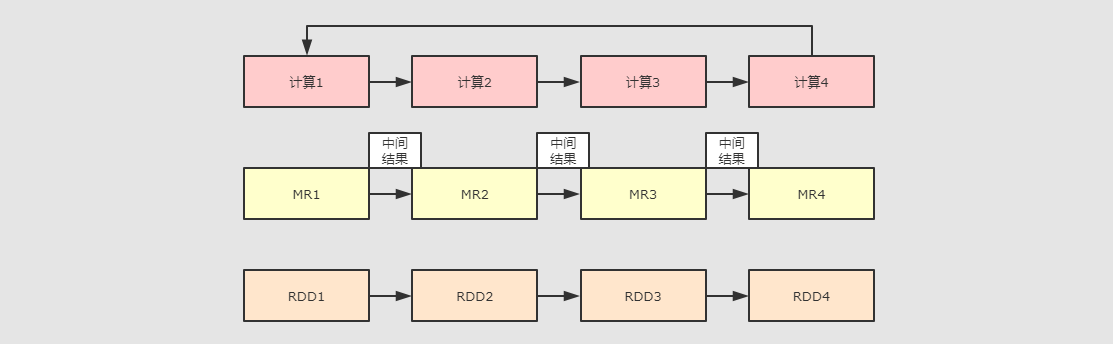
那么现在spark是什么呢?我们可以大概的总结一下
Apache Spark是一个快速的,多用途的集群计算系统,相对于Hadoop Mapreduce将中间结果保存在磁盘中,Spark使用了内存保存中间结果,能在数据尚未写入硬盘时在内存中进行计算。
当然,spark只是一个计算框架,不像hadoop一样具备分布式文件系统和完备的调度系统,如果要使用spark需要结合存储系统和调度系统来使用。
二、Spark的特点是什么?
目标:通过了解spark的特点,从而了解为什么要用spark
(1)速度快:spark在内存时的运行速度时mapreduce的100倍;基于硬盘的运算速度大概时mapreduce的10倍;spark实现了一种叫做RDD的DAG(有向无环图)执行引擎,其数据缓存在内存中可以进行迭代处理。
(2)易用性:spark支持scala,python,java等多语种的API;spark支持超过80个高级运算符使得用户很轻易构建并运行计算程序;spark可以基于scala,paython,r,sql的shell交互式查询。
(3)通用性:spark提供了一个完整的技术栈,包括sql执行,数据集dataset命令式的API,机器学习库MLlib,图计算框架GraphX,流计算SparkStreaming。用户可以在同一个应用中同时使用这些强大的工具,这是划时代的。
(4)兼容性:spark可以运行在Hadoop,Apache Mesos,Kubernets,Spark Standalone等集群中;spark可以访问Hbase、Hive在内的多种数据库。
总结:因为能使用多语种的API;可扩展集群节点超过8k个;在内存中缓存数据集,实现交互式数据分析;提供命令窗口。
三、Spark的核心是什么?为什么是它?
Spark 核心的部分就是spark core,而spark core最核心的功能是RDD,RDD存在于spark-core包内,也是spark最核心的包。那我们就来了解spark-core和弹性分布式数据集(RDD)
-
Spark-Core 是整个 Spark 的基础, 提供了分布式任务调度和基本的 I/O 功能
-
Spark 的基础的程序抽象是弹性分布式数据集(RDDs), 是一个可以并行操作, 有容错的数据集合
-
RDDs 可以通过引用外部存储系统的数据集创建(如HDFS, HBase), 或者通过现有的 RDDs 转换得到
-
RDDs 抽象提供了 Java, Scala, Python 等语言的API
-
RDDs 简化了编程复杂性, 操作 RDDs 类似通过 Scala 或者 Java8 的 Streaming 操作本地数据集合
-
四、spark集群结构是怎样的呢?程序怎样运行在集群中的?
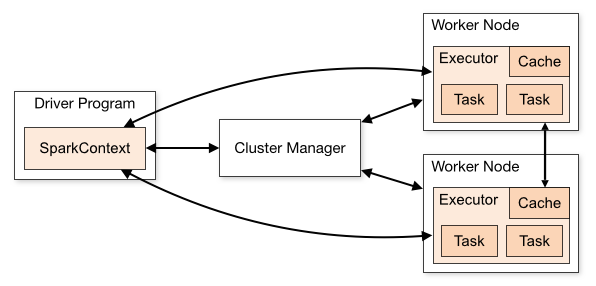
角色解释
-
Driver该进程调用 Spark 程序的 main 方法, 并且启动 SparkContext
-
Cluster Manager该进程负责和外部集群工具打交道, 申请或释放集群资源
-
Worker该进程是一个守护进程, 负责启动和管理 Executor
-
Executor该进程是一个JVM虚拟机, 负责运行 Spark Task
运行一个 Spark 程序大致经历如下几个步骤
-
启动 Drive, 创建 SparkContext
-
Client 提交程序给 Drive, Drive 向 Cluster Manager 申请集群资源
-
资源申请完毕, 在 Worker 中启动 Executor
-
Driver 将程序转化为 Tasks, 分发给 Executor 执行
当然,这里也有spark on yarn模式下的集群,这里大家可以去找找对应的资料。就是调度器的不同,位置也就不尽相同。 ZHE
这里省略了spark的安装,以及shell命令编写案例测试是否正常运行,在文末会有入门级案例wordcount的scala编写,以及demo的依赖,大家可以尝试编写。
四、RDD是什么? ----spark核心RDD
什么是RDD?
RDD 全称为 Resilient Distributed Datasets,是 Spark 最基本的数据抽象,它是只读的、分区记录的集合,支持并行操作,可以由外部数据集或其他 RDD 转换而来,它具有以下特性:
- 一个 RDD 由一个或者多个分区(Partitions)组成。对于 RDD 来说,每个分区会被一个计算任务所处理,用户可以在创建 RDD 时指定其分区个数,如果没有指定,则默认采用程序所分配到的 CPU 的核心数;
- RDD 拥有一个用于计算分区的函数 compute;
- RDD 会保存彼此间的依赖关系,RDD 的每次转换都会生成一个新的依赖关系,这种 RDD 之间的依赖关系就像流水线一样。在部分分区数据丢失后,可以通过这种依赖关系重新计算丢失的分区数据,而不是对 RDD 的所有分区进行重新计算;
- Key-Value 型的 RDD 还拥有 Partitioner(分区器),用于决定数据被存储在哪个分区中,目前 Spark 中支持 HashPartitioner(按照哈希分区) 和 RangeParationer(按照范围进行分区);
- 一个优先位置列表 (可选),用于存储每个分区的优先位置 (prefered location)。对于一个 HDFS 文件来说,这个列表保存的就是每个分区所在的块的位置,按照“移动数据不如移动计算“的理念,Spark 在进行任务调度的时候,会尽可能的将计算任务分配到其所要处理数据块的存储位置。
这里的特性,我们只是翻译过来的,真正的特性我们可以在源代码中找到,按ctrl+n+n,然后搜索RDD,我们可以看到这样一个描述: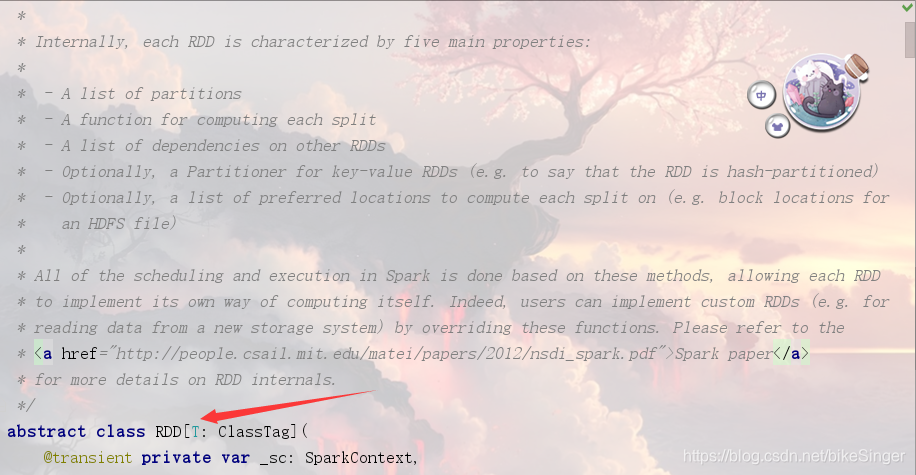
五、创建RDD
这里的代码都是scala语言,由于scala语言小众,先设成java模式。
从本地创建RDD:
val conf = new SparkConf().setAppName("Spark shell").setMaster("local[4]")
val sc = new SparkContext(conf)
val data = Array(1, 2, 3, 4, 5)
// 由现有集合创建 RDD,默认分区数为程序所分配到的 CPU 的核心数
val dataRDD = sc.parallelize(data)
// 查看分区数
dataRDD.getNumPartitions
// 明确指定分区数
val dataRDD = sc.parallelize(data,2)
从外部创建RDD
val conf = new SparkConf().setMaster("local[4]")
val sc = new SparkContext(conf)
val source: RDD[String] = sc.textFile(dataset/wordcount.txt")
从其它RDD衍生新的RDD
val conf = new SparkConf().setMaster("local[4]")
val sc = new SparkContext(conf)
val source: RDD[String] = sc.textFile(dataset/wordcount.txt")
val words = source.flatMap { line => line.split(" ") }
wordcount案例以及相关spark依赖代码
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>sparkDemo</groupId>
<artifactId>sparkDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<scala.version>2.11.8</scala.version>
<spark.version>2.2.0</spark.version>
<slf4j.version>1.7.16</slf4j.version>
<log4j.version>1.2.17</log4j.version>
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>jcl-over-slf4j</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass></mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
package zyp.spark
import org.apache.spark.{SparkConf, SparkContext}
/*
* 单词统计
* */
object wordcount {
def main(args: Array[String]): Unit = {
//1.创建sparkcontext对象
val conf = new SparkConf().setAppName("wordcount").setMaster("local[4]")
val sc = new SparkContext(conf)
// 第二步,读取文件的位置
val add1 = sc.textFile("dataset/wordcount.txt")
// 第三步,切分单词,并压缩转换为map
val add2 = add1.flatMap((_.split(" ")))
// 第四步,将每个单词后面添加1,词频
val add3 = add2.map(_->1)
// 第五步,统计总数
val add4 = add3.reduceByKey(_+_)
add4.foreach(println(_))
print(add4)
}
}

















 17万+
17万+



 到【灌水乐园】发言
到【灌水乐园】发言







