



 请点击上方蓝字TonyBai订阅公众号!
请点击上方蓝字TonyBai订阅公众号!

大家好,我是Tony Bai。
Datadog 的故事始于一次对Go 1.24内存回归问题的追踪。在与 Go 社区协作修复了该问题后,他们在部署修复版本的过程中,观察到了一个意料之外的现象:在高流量环境中,内存使用不仅恢复了正常,甚至大幅下降。一个名为 shardRoutingCache 的巨型内存 map,其堆内存占用减少了约 500 MiB,考虑到 Go 的垃圾回收机制(GOGC=100),这相当于节省了近 1 GiB 的物理内存。
这一发现引出了两个核心问题:
Go 1.24 究竟做了什么,让
map在某些场景下变得如此高效?为什么这种内存优化的效果并非在所有环境中都一致?

Go Map 的前世今生:从 Bucket 到 Group
要理解这一变革,我们必须回顾 Go map 的内部实现演进。
Go 1.23 及之前:基于 Bucket 的设计
在 Go 1.24 之前,Go 的 map 实现是基于传统的桶(Bucket)和链式地址法来解决哈希冲突的。
结构:
map由一个 Bucket 数组组成。每个 Bucket 内部有 8 个槽(slot),用于存放键值对。插入与查找:当插入或查找一个键时,Go 会计算其哈希值以确定它属于哪个 Bucket。然后,它需要线性扫描该 Bucket 内的所有槽位来查找匹配的键。
溢出处理:当一个 Bucket 的 8 个槽都满了,后续哈希到此的键值对会被放入一个溢出桶(overflow bucket)中,并形成一个链表。这意味着,在最坏的情况下,一次查找可能需要遍历多个 Bucket。
扩容机制:当
map的平均负载因子超过阈值(约 81.25%)时,会触发扩容。Go 会分配一个两倍大小的新 Bucket 数组,但并不会立即迁移所有数据。为了平摊延迟,数据迁移是增量进行的,在后续的写操作中,旧 Bucket 的数据会逐渐被搬迁到新 Bucket。这种设计虽然降低了单次操作的延迟,但其代价是在迁移期间,新旧两个 Bucket 数组会同时存在于内存中,导致瞬时内存翻倍。
Go 1.24 的革新:Swiss Table 与可扩展哈希
Go 1.24 引入了一套全新的、基于 Swiss Tables 和可扩展哈希(extendible hashing) 的 map 实现,彻底改变了游戏规则。
结构:数据被存储在组(Group)中,每个组同样包含 8 个槽。与 Bucket 不同的是,每个 Group 都有一个 8 字节的控制字(control word)。控制字的每个字节对应一个槽,其低 7 位存储了该槽位 key 哈希值的最后 7 位(
h2),最高位则是一个标记,表示该槽是空闲(empty)、已删除(deleted)还是使用中(in use)。
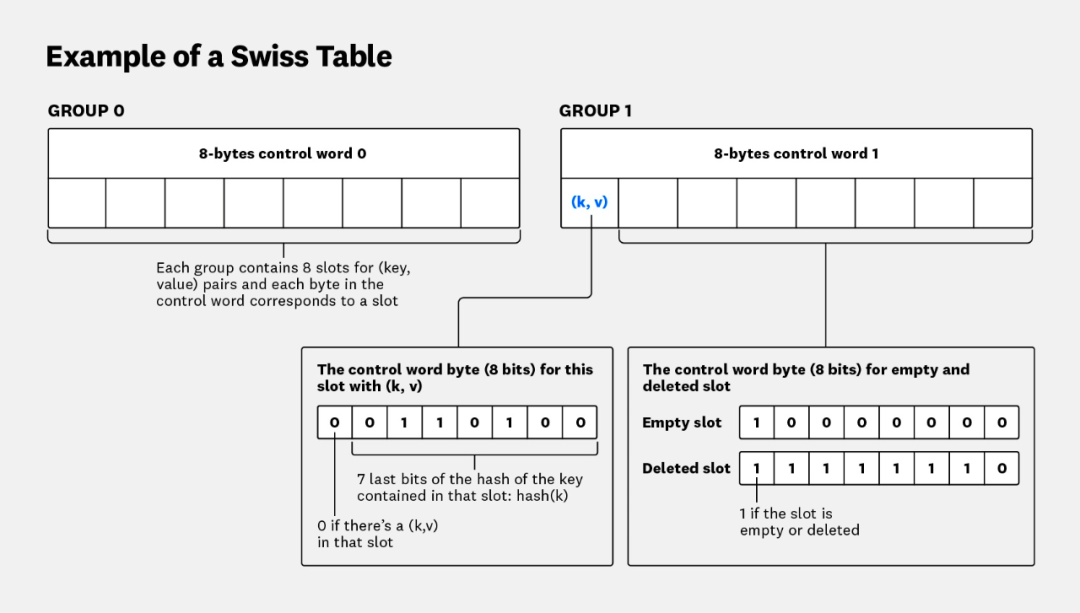
高效查找:当查找一个键时,不再需要线性扫描所有键值对。Go 可以利用单指令多数据流(SIMD)指令,将目标键的
h2值与控制字中的 8 个字节并行比较,一次性找出所有可能匹配的槽位。这极大地加速了查找过程。开放寻址与无溢出桶:当一个 Group 满了,新的键值对会通过开放寻址(probing)的方式,被尝试放入下一个 Group。这种快速的探测机制彻底消除了对溢出桶的需求。
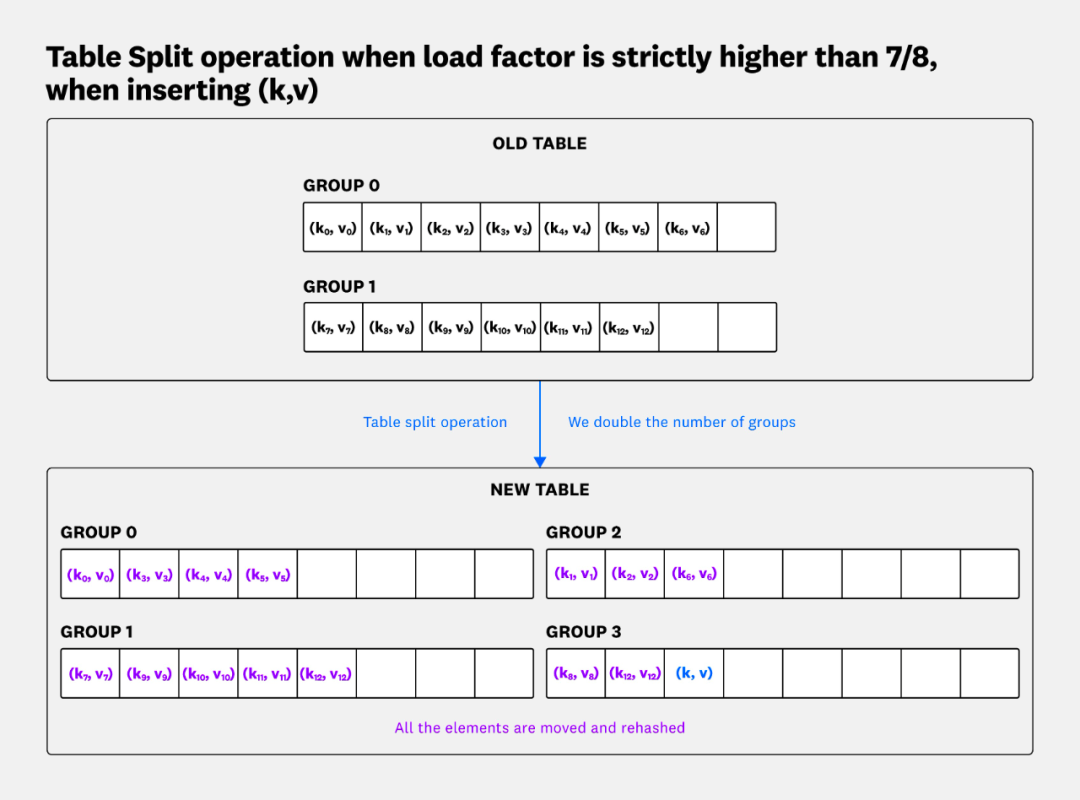
更高的负载因子与更高效的扩容:由于探测速度极快,Swiss Table 可以安全地维持更高的负载因子(87.5%),这意味着在存储相同数量的元素时,所需的总槽位数更少,从而节省了内存。更重要的是,对于非常大的
map,Go 1.24 采用了可扩展哈希,将一个大map视为一个由多个独立的、大小有上限(128个Group)的 Swiss Table 组成的目录。当某个子表需要分裂时,只会影响该子表本身,而不是像旧版map那样保留整个旧的 Bucket 数组,这使得扩容过程的内存效率大大提高。
Datadog 实战:量化 Swiss Table 带来的巨大收益
Datadog 团队通过详细的计算,量化了这次底层变更对他们核心业务数据 shardRoutingCache 的影响。
案例背景:一个巨大的内存缓存 shardRoutingCache
这个 map 在服务启动时从数据库加载,并且很少写入,其结构如下:
// The key represents each routing key derived from the data payload
shardRoutingCache map[string]Response
type Response struct {
ShardID int32
ShardType ShardType // ShardType is an int
RoutingKey string
LastModified *time.Time
}在 64 位架构下,每个键值对(不含 string 内容和 time.Time 结构体)的基础大小为 56 字节。
高流量环境:350 万元素的 map
Go 1.23 下的内存估算:为了存储 350 万个元素,并考虑到增量扩容期间新旧 Bucket 数组共存的情况,Datadog 估算出
map的桶结构本身大约需要 696 MiB 内存。Go 1.24 下的内存估算:得益于更高的负载因子和更高效的扩容机制,存储同样多的元素,Swiss Table 只需要大约 500,000 个 Group,分布在约 3900 个独立的子表中。每个子表独立管理内存,避免了全局的内存加倍。
最终结果是,仅 map 结构本身的内存占用就从近 700 MiB 降至约 200 MiB 左右,实现了约 70% 的惊人降幅,这与他们在生产环境中观察到的 500 MiB 堆内存节省高度吻合。
低流量环境:55 万元素的 map
然而,在元素数量级较小的环境中(约 55 万),内存节省效果(约 28 MiB)远没有那么显著。这点节省甚至不足以抵消 Go 1.24 中 mallocgc 的内存回归带来的开销(约 200-300 MiB RSS 增加)。这完美地解释了为什么内存优化的效果并非普遍存在:Swiss Table 的优势在处理大规模 map 时才能被最大化地体现出来。
超越运行时:应用层优化的锦上添花
受到运行时优化的启发,Datadog 团队还审视了自己的数据结构 Response。他们发现:
RoutingKey和LastModified字段在该map的特定用例中从未被填充。ShardType作为一个只有 3 个值的枚举,却使用了 8 字节的int类型。
通过创建一个仅包含所需字段的新结构 cachedResponse,并将 ShardType 从 int 改为 uint8,他们将每个 value 的大小从 40 字节(带填充)锐减至 8 字节(带填充)。这一应用层面的优化,为他们高流量环境中的每个 pod 额外节省了约 250 MiB 的 RSS。
总结与启示
Datadog 的这次深度调查为 Go 开发者社区带来了宝贵的经验:
Go 1.24 的 Swiss Tables 是一个巨大的胜利:对于重度使用大型
map的应用,升级到 Go 1.24 能带来立竿见影的、显著的内存节省和性能提升。升级需谨慎,观测是关键:每个 Go 版本都可能带来优化和回归。没有深入的运行时指标(如 RSS)和堆分析,像
mallocgc回归和 Swiss Table 优化这样的 subtle 变化很容易被忽略或误判。运行时与应用层优化相辅相成:底层的改进为上层应用打开了新的优化空间。审视自己的数据结构,消除浪费,使用恰当大小的类型,这些看似微小的改动在规模化部署下能产生巨大的影响。
社区协作的力量:从发现问题到与 Go 团队协作验证修复,这次经历再次证明了 Go 社区开放协作文化的强大。
总而言之,Go 1.24 中 map 的革新是一次教科书式的工程优化。它不仅提升了 Go 语言的核心竞争力,也通过 Datadog 的分享,为所有 Go 开发者上了一堂生动的、关于性能分析与优化的实践课。
资料链接:https://www.datadoghq.com/blog/engineering/go-swiss-tables/
如果本文对你有所帮助,请帮忙点赞、推荐和转发 !
!
点击下面标题,阅读更多干货!
- Go map使用Swiss Table重新实现,性能最高提升近50%
- 自定义Hash终迎标准化?Go提案maphash.Hasher接口设计解读
- Go新垃圾回收器登场:Green Tea GC如何通过内存感知显著降低CPU开销?
🔥 你的Go技能,是否也卡在了“熟练”到“精通”的瓶颈期?
想写出更地道、更健壮的Go代码,却总在细节上踩坑?
渴望提升软件设计能力,驾驭复杂Go项目却缺乏章法?
想打造生产级的Go服务,却在工程化实践中屡屡受挫?
继《Go语言第一课》后,我的 《Go语言进阶课》 终于在极客时间与大家见面了!
我的全新极客时间专栏 《Tony Bai·Go语言进阶课》 就是为这样的你量身打造!30+讲硬核内容,带你夯实语法认知,提升设计思维,锻造工程实践能力,更有实战项目串讲。
目标只有一个:助你完成从“Go熟练工”到“Go专家”的蜕变! 现在就加入,让你的Go技能再上一个新台阶!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









