




 本文详细探讨了数据库中联合索引的概念,解释了其作为B+树的内部结构,以及如何提升查询效率,特别是在涉及多列排序的情况下。通过具体实例说明了联合索引在不同查询条件下的适用性和局限性。
本文详细探讨了数据库中联合索引的概念,解释了其作为B+树的内部结构,以及如何提升查询效率,特别是在涉及多列排序的情况下。通过具体实例说明了联合索引在不同查询条件下的适用性和局限性。
告诫大家想弄懂一些知识,真的得看书,书是成体系的,而且比一般博客靠谱多了,关于这篇文章的这个问题,看了很多博客都是错的,简直误导我等菜鸟!!!
联合索引
联合索引是指对表上的多个列进行索引。
举例:
以下代码创建了一张 t 表,并且索引 idx_a_b 是联合索引,联合的列为 (a, b) 。
CREATE TABLE t{
a INT,
b INT,
PRIMARY KEY (a),
KEY idx_a_b(a, b)
}ENGINE=INNODB
先来看看联合索引内部的结构。从本质上来说,联合索引也是一棵 B+ 树,不同的是联合索引的键值的数量不是 1 ,而是大于等于 2。接这来讨论两个整型列组成的联合索引,假定两个键值的名称分别为 a、b,如下图所示。
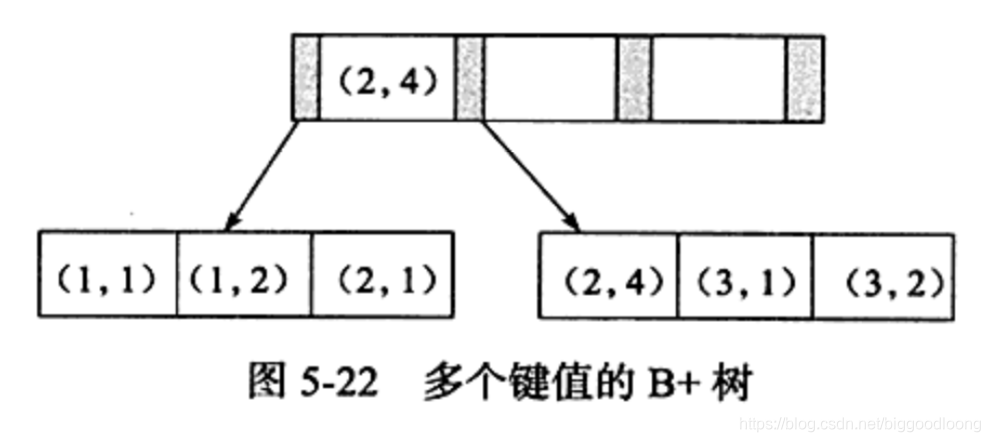
从图中可以观察到多个键值的 B+ 树的情况。其实和单个键值的 B+ 树并没有什么不同,键值都是排序的,通过叶子节点可以逻辑上顺序读出所有数据,就上面例子来说,即 (1, 1)、(1, 2)、(2, 1)、(2, 4)、(3, 1)、(3, 2)。数据按 (a, b) 的顺序进行了排序。
因此,对于查询 SELECT * FROM TABLE t WHERE a=xxx and b=xxx,显然是可以适应 (a, b)这个联合索引的。对于单个的 a 列查询 SELECT * FROM TABLE t WHERE a=xxx,也可以使用 (a, b) 索引。但对于 b 列的查询 SELECT * FROM TABLE t WHERE b=xxx,则不可以使用这棵 B+ 树索引。可以发现叶子节点上的b值为 1、2、1、4、1、2,显然不是排序的,因此对于b列的查询使用不到 (a, b) 的索引。
索引的第二个好处是已经对第二个键值进行了排序处理。例如在很多情况下应用程序都需要查询某个用户的购物情况,并按时间进行排序,最后取出最近三次的购买记录,这时使用联合索引可以避免多一次的排序操作,因为索引本身在叶子节点已经排序了。
参考:
姜承尧《innodb存储引擎》这本书的联合索引这一节

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









