




起初是来源于一个SUBNET问题。一位客户观察到他们的部署出现了性能衰减现象。经过一些调查,我们发现客户运行的一个脚本是问题的原因。该脚本是一个同步脚本,每次运行之间有一分钟的延迟,用于上传目录的内容。
由于客户使用了服务器端复制,目标存储桶启用了版本控制。上传脚本采用了一种简单的方法,每次运行时都会上传所有文件。为了控制版本数量,客户使用了自动对象过期规则,删除所有早于一天的版本。
我们发现的问题是,即使文件很小,版本数量在生命周期运行之间累积的数量也会对系统造成重大负载。
虽然我们可以建议客户快速解决问题,但我们将其视为改进我们如何处理过多版本号的机会。
元数据结构
MinIO服务器没有数据库。这是早期做出的设计选择,也是MinIO能够在数千个服务器上以容错的方式进行扩展的主要因素。MinIO不使用数据库,而是使用一致性哈希和文件系统来存储对象的所有信息和内容。
当我们实施版本控制时,我们调查了各种选项。在版本控制之前,我们将元数据存储为JSON格式。这使得我们可以直接查看元数据,从而更容易调试问题。然而,在我们的研究中,我们发现虽然这很方便,但通过切换到二进制格式,我们可以将磁盘使用量减少约50%,CPU使用量也减少了大约相同的比例。
我们决定选择MessagePack作为我们的序列化格式。这保持了JSON的可扩展性,允许添加/删除键。最初的实现只是一个header,后面跟着一个具有以下结构的MessagePack对象:
{
"Versions": [
{
"Type": 0, // Type of version, object with data or delete marker.
"V1Obj": { /* object data converted from previous versions */ },
"V2Obj": {
"VersionID": "", // Version ID for delete marker
"ModTime": "", // Object delete marker modified time
"PartNumbers": 0, // Part Numbers
"PartETags": [], // Part ETags
"MetaSys": {} // Custom metadata fields.
// More metadata
},
"DelObj": {
"VersionID": "", // Version ID for delete marker
"ModTime": "", // Object delete marker modified time
"MetaSys": {} // Delete marker metadata
}
}
]
}
先前版本的元数据在更新时被转换,新版本则根据操作添加为“V2Obj”或“DelObj”。
我们尝试让我们的基准测试在真实数据上运行,以便它们适用于实际使用。我们评估了读写多达10,000个版本(每个版本有10,000个分片)的时间,作为我们的最坏情况。基准测试显示,解码这需要约120毫秒。读取的内存分配相当大,但由于大多数对象只有1个分片,因此10,000个对象代表了最坏情况,因此被认为是可以接受的。
这是约一年的磁盘表示。内联数据被添加到格式中,允许小对象的数据存储在与元数据相同的文件中。但这并没有改变元数据表示,因为内联数据存储在元数据之后。
这意味着在只需要读取元数据的情况下,我们可以在达到元数据结尾时停止读取文件。这可以通过最多连续两次读取来实现。
对象版本
让我们退后一步,看看对象版本控制作为一个概念。简而言之,它记录对象的更改,并允许您回到过去。简单的客户端不需要担心版本控制,只需在最新的对象版本上操作即可。
后端只需跟踪上传的版本即可。例如:
$ mc ls --versions play/test/ok.html
[2021-12-14 18:00:52 CET] 18KiB 83b0518c-9080-45bb-bfd3-3aecfc00e201 v6 PUT ok.html
[2021-12-14 18:00:43 CET] 0B ff1baa7d-3767-407a-b084-17c1b333ea87 v5 DEL ok.html
[2021-12-11 10:01:01 CET] 18KiB ff471de8-a96b-43c2-9553-8fc21853bf75 v4 PUT ok.html
[2021-12-11 10:00:21 CET] 18KiB d67b20e2-4138-4386-87ca-b37aa34c3b2d v3 PUT ok.html
[2021-12-11 10:00:11 CET] 18KiB 47a4981a-c01b-4c6a-9624-0fa44f61c5e9 v2 PUT ok.html
[2021-12-11 09:57:13 CET] 18KiB f1528d08-482d-4945-b8ee-e8bd4038769b v1 PUT ok.html
这里显示了6个ok.html版本的写入和1个版本(v5)的删除。元数据将跟踪版本。
在最简单的情况下,管理元数据纯粹是追加更改的问题。然而,在现实中可能并不是那么简单。例如,当更改被写入时,磁盘可能处于离线状态。如果我们可以写入足够的磁盘,我们就接受这个更改,但这意味着当磁盘回来时,它们将需要进行修复。复制和分层可能需要更新旧版本,标签可以添加到版本中等等。
几乎任何更新都意味着我们需要检查版本是否仍然按正确顺序排序。对象版本严格按“修改时间”排序,这意味着对象版本上传的时间。对于上面的结构,这意味着我们需要加载所有版本才能访问此信息。
当版本数量非常高时,初始设计开始显示其局限性。对于某些操作,我们需要所有版本信息都可用,有时需要超过1GB的内存才能完成。使用这么多内存将对可以进行的并发操作数量产生很大限制,这当然是不可取的。
设计考量
起初,我们评估了将所有版本的元数据存储在单个文件中的可行性。我们很快就拒绝了将单个版本存储为单个文件的方法。一个版本的元数据通常少于1KB,因此列出所有版本将导致随机IO的爆炸。
列出单个版本还会返回版本计数和“后继”修改时间,即任何更新版本的时间戳。因此,我们需要了解所有版本的信息,这意味着每个版本都有一个文件将对性能产生反作用。
我们考虑了一种日志类型的方法,其中更改是附加而不是在每次更新时重写元数据。虽然这可能对写入有优势,但在读取时会带来很多额外的处理。这不仅适用于单个读取,而且还会显著减慢列表速度。因此,这不是我们想要追求的方法。
相反,我们决定看看我们通常需要进行所有版本操作的信息以及我们需要哪些信息来处理单个版本。
大多数操作要么操作“最新版本”,要么操作特定版本。如果您进行GetObject调用,可以指定版本ID并获取该版本,否则您的请求将被视为针对最新版本。
大多数操作都类似。唯一操作涉及所有版本的是ListObjectVersions调用,它返回对象的所有版本。
对象变异需要检查现有版本ID和修改时间以进行排序。列表需要跨磁盘合并版本,因此需要能够检查元数据在各个磁盘上是否相同。
如果我们可以访问此信息,则没有任何操作需要一次性在内存中解压缩所有版本元数据。对性能的影响是巨大的。
实现
实际上,我们决定进行一个相当小的更改,以实现所有这些改进。我们不再将所有版本完全解压缩到内存中,而是改为以下结构:
// xlMetaV2 contains all versions of an object.
type xlMetaV2 struct {
// versions sorted by modification time,
// most recent version first.
versions []xlMetaV2ShallowVersion
}
// xlMetaV2ShallowVersion contains metadata information about
// a single object version.
// metadata is serialized.
type xlMetaV2ShallowVersion struct {
header xlMetaV2VersionHeader
meta []byte
}
// xlMetaV2VersionHeader contains basic information about an object version.
type xlMetaV2VersionHeader struct {
VersionID [16]byte
ModTime int64
Signature [4]byte
Type VersionType
Flags xlFlags
}
现在,我们仍然将所有版本“存储在内存中”,但我们现在将每个版本的元数据保留为序列化形式。实际上,这个序列化数据只是从磁盘加载的元数据的子切片。这意味着我们只需要为所有版本分配一个固定大小的切片。为了执行我们的操作,我们有一个带有有限信息的头文件,每个版本都有足够的信息,我们永远不需要扫描所有元数据。
磁盘上的表示也已更改以适应此。以前,所有元数据都存储为一个包含所有版本的大对象。现在,我们将其写成这样:
- 带版本的签名
- 头数据的版本(整数)
- 元数据的版本(整数)
- 版本计数(整数)
读取此头文件允许我们在xlMetaV2实例中分配“versions”。由于xlMetaV2ShallowVersion中的所有字段大小都是固定的,因此这将是我们唯一需要的分配。

对于每个版本,有两个二进制数组,一个包含序列化的xlMetaV2VersionHeader,另一个包含完整的元数据。对于所有操作,我们只读取头文件并将序列化的完整元数据保留在内存中。在磁盘上,这每个版本增加了约30-40个字节,即使这是重复的数据,由于性能提升,这仍然是一个可以接受的折衷。
这意味着对于只影响单个版本的常规变异,我们只需要反序列化该特定版本,应用变异并序列化该版本。同样地,对于删除和插入,我们永远不必处理完整的元数据。
对象版本可以(重新)排序,而不移动更多的头文件和序列化的元数据。此外,我们现在还保证保存的文件已经预先排序。这意味着我们现在可以快速识别最新版本,并且获取“后继”修改时间是微不足道的。
对于最常见的读取操作,这意味着我们一旦找到所需内容就可以立即返回。列表现在可以一次反序列化一个版本-节省内存并提高性能。
升级
MinIO已经有数千个部署,存储了数十亿个对象,因此平稳升级非常重要。当更改对象存储方式时,我们采用“不转换”方法,即即使数据处于旧格式,我们也不会更改存储的数据。对于许多对象,转换所有对象将是一项耗时和资源消耗巨大的任务。
任务的一个重要部分是确保现有数据不会消耗大量资源进行读取。我们不能接受升级会显著降低性能。但我们不希望为旧版本保留重复的代码。现有数据通常最终需要进行转换,我们希望尽早处理。
在这种情况下,我们能够利用MessagePack的一些优势。虽然我们仍然需要反序列化所有版本,但我们可以做一些技巧:
- 查找“Versions”数组。
- 读取大小。 分配我们需要的[]xlMetaV2ShallowVersion。
- 对于数组中的每个元素:
- 反序列化到临时位置
- 基于反序列化的数据创建xlMetaV2VersionHeader。
- 观察反序列化时消耗的字节数。
- 从序列化数据创建子切片。
这与以前的版本一样快,因为我们正在处理相同的数据。唯一的区别是我们一次只需要一个版本在内存中,这显著减少了内存使用。
通过这个技巧,我们能够以与以前相同的处理量加载现有元数据。如果需要将元数据写回磁盘,则现在处于新格式,并且在下一次读取时不需要进行转换。
扩展性基准测试和分析
为了评估扩展性,我们总是尝试创建真实的负载,但也力求达到最坏的情况。在这种情况下,我们有一个明确的客户案例,超过1000个版本开始导致性能问题。虽然我们会对系统的各个部分进行基准测试,但真正的测试始终是综合端到端的测量。
为了评估MinIO的扩展能力,我们使用了我们的Warp S3基准测试工具。Warp使得创建非常特定的负载成为可能。对于这个测试,我们使用了put(PutObject)和stat(HeadObject)基准测试。我们创建了许多对象,每个对象都有不同数量的版本,并观察我们能够多快地从随机对象/版本中获取元数据。
我们在一个分布式服务器上进行了测试,只使用了一个NVME。这些数字并不代表完整的MinIO集群,而只代表单个服务器。不再拖延,让我们看看这些数字:
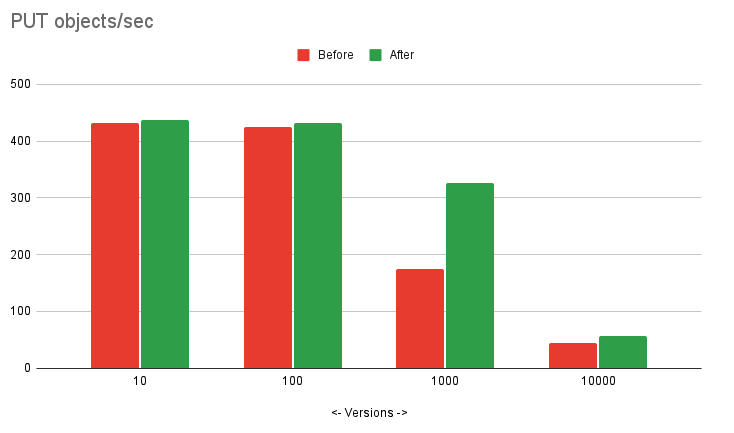
垂直轴表示每秒提交到服务器的对象版本数量。请注意,每个样本代表版本数量的数量级。请注意,更高的条形图意味着更多的操作/秒,这意味着更高的性能。
分析这些数字,当版本数量为10和100时,我们基本上看到相同的上传速度。这是预期的,因为我们没有观察到“正常”版本数量可能出现的问题。即便如此,轻微的加速也是好的观察结果。
当版本数量为1,000时,我们观察到了我们调查的问题,并且我们很高兴看到这种情况下的1.9倍加速。
当版本数量为10,000时,出现了一个有趣的问题。此时,我们的服务器在NVME存储上达到了IO饱和状态,约为1.5GB/s。这将瓶颈从系统的一个部分转移到另一个部分,从内存转移到存储。添加对象的第10,000个版本所需的时间仅为350毫秒。
查看读取性能:

需要注意的第一件事是规模不同。我们正在处理超过一个数量级的更多对象。您可以看到一个明显的好处是不必反序列化所有对象版本 - MinIO可以平稳地扩展,以提供最佳性能,无论版本化对象的数量如何。我们优化的结果是,对于具有1000个或更多版本的对象的读取,在整体性能和系统响应性方面实现了3-4倍的速度提高。
请记住,这些测试是在单个服务器上进行的,使用单个NVME驱动器,不是最适合性能测试的系统。即使在这种配置下,我们每秒读取大约180个对象版本信息,因此,虽然读取10000个对象版本比读取较少数量的对象要慢,但绝不会无响应。
结论和未来改进
我们的主要目标是减少多个版本的处理开销。我们将内存使用量降低了几个数量级,并提高了版本处理的速度。
解决问题的好处在于,总会有更多的挑战需要解决。在这个迭代中,我们将可行版本数量增加了一个数量级。然而,在MinIO,我们从来不满足于此——我们已经在研究进一步提高已经是世界上最快的分布式对象存储的性能和可扩展性。
我们可以观察到,在某个点上,我们达到了IO限制,其中变异变得负担重重,因为总元数据大小。变异文件在千字节范围内是可以接受的,但一旦达到兆字节范围,对系统来说就变得很密集了。
现在我们有一个称为“XL”的单一数据格式。在未来,我们可能会研究将头文件和完整元数据/内联数据拆分为两个文件的选项。这对于少量版本来说是次优的,因为IOPS很珍贵,但对于1000个以上的版本,这可能是我们可以采取的方法。让我们称之为“XXL”格式。
控制系统使用的数据格式有很大的优势。这种控制水平意味着您可以不断改进系统,并确保您可以这样做。在MinIO,我们的目标是不断改进并帮助我们的客户扩展。当然,我们可以简单地告诉客户,如果不拥有太多相同数据的版本,他们将获得最佳性能,但这不是MinIO的方式。我们为您做重活,让MinIO的客户可以专注于他们的应用程序,将备份存储留给我们。
不要只听广告,看疗效的话 - 下载MinIO,亲自体验差异。
 https://blog.min.io/minio-versioning-metadata-deep-dive/
https://blog.min.io/minio-versioning-metadata-deep-dive/
















 185
185

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









