



 本文探讨Redis在缓存、排行榜、计数器、社交网络及消息队列的应用,解析其数据结构与内部编码,以及如何高效利用Redis进行性能优化。
本文探讨Redis在缓存、排行榜、计数器、社交网络及消息队列的应用,解析其数据结构与内部编码,以及如何高效利用Redis进行性能优化。
Redis作为目前最为火热的NoSql数据库有着非常多的优点,对于没有做过大型项目或者没有接触过Redis的程序员来说一直有一个问题,Redis这么优秀,但是他的应用到底在哪些领域那?
1.缓存
缓存机制可以说是所有大型网站必备的,缓存能够有效地缓解后端数据源的压力。Redis提供了键值过期时间的设置,提供了灵活控制最大内存和内存溢出后的淘汰策略。
2.排行榜
排行榜系统几乎存在于所有的网站,比如按照热度排名的排行榜,按照时间,以及按照各种复杂维度计算出的排行榜。Redis提供了列表和有序集合数据结构,对于排行榜非常方便。
3.计数器应用
计数器在网站中至关重要,如视频网站播放数,电商浏览数,为了保证数据实时性,这对高并发的的传统关系型数据库的性能是一种很大的挑战。Redis却非常方便。
4.社交网络
赞/踩,粉丝,共同好友/洗好,推送,下拉刷新等是社交网站的必备功能,由于社交网站的访问量比较大,传统的关系型数据库不适合保存这种类型的数据,Redis提供的数据结构可以比较容易的实现这些功能。
5.消息队列系统
消息队列也是大型网站的必备基础组件,因为其具有业务解耦,非实时业务削峰等特性。Redis也提供了这些功能。
Redis不适合做什么?
对于Redis不适合做什么,可以从数据大小和数据冷热角度进行分析。比如如果每天有几亿用户行为数据,使用redis来存储基本就是个无底洞。冷热数据是指,对于视频网站来说,视频基本信息是各个业务线都要经常操作的数据,需要存在Redis,而用户的观看记录不是经常访问的数据,所以可以放在传统数据库里。
Redis安装好后,src和/usr/local/bin目录下多了几个以redis开头的可执行文件,我们称为Redis Shell,这些可执行文件可以做很多事情,例如启动停止redis,检测和修复Redis的持久化文件,还可以检测redis的性能。
|可执行文件|作用|
|redis-server|启动Redis|
|redis-cli|Redis命令行客户端|
|redis-benchmark|Redis基准测试工具|
|redis-check-aof|Redis AOF持久化文件检测和修复工具|
|redis-check-dump|Redis RDB持久化文件检测和修复工具|
|redis-sentinel|启动Redis Sentinel|
启动Redis的三种方式:默认配置,运行配置和默认文件启动。
默认配置:redis-server,这种方式无法自定义配置。
运行启动:redis-server --configKey1 configValue1 --configKey2 configValue2
比如要用6380作为端口启动Redis,可以执行
redis-server --port 6380
配置文件启动:将配置写到指定文件中,redis -server /opt/redis/redis.conf
在客户端上停止Redis服务的命令:
redis-cli shutdown
Redis关闭的过程:断开与客户端的连接,持久化文件生成,是一种相对优雅的关闭方式。
还可以通过kill进程的方式关闭Redis,但是不要粗暴的使用kill -9强制杀死Redis,不但不会做持久化操作,还会操作缓冲区等资源不能被优雅关闭,极端情况会找成AOF和复制丢失数据的情况。
shutdown还有一个参数,代表是否在关闭Redis前,生成持久化文件:
redis-cli shutdown nosave|save
获取当前redis的键总数时有两种方式,一种是使用dbsize,dbsize在计算键总数时不会遍历所有键,而是直接获取Redis内置的键总数变量,所以dbsize的时间复杂度是o(1)。而keys命令会遍历所有键,在的时间复杂度是o(n),当Redis保存了大量键时,线上环境禁止使用keys。
set设置键值对,del删除,exists 是否存在, exprie 设置键的过期时间,ttl可以查看键的过期时间。type key 查看键的类型。
数据结构和内部编码
type命令实际返回的就是当前键的数据类型,分别是:string(字符串),hash(哈希),list(列表),set(集合),zset(有序集合)。每个数据类型都有自己的底层实现,可以通过object encoding命令查询。比如ziplist比较节省内存,但是在列表元素较多的情况下,性能有所下降,这时Redis会根据配置的选项将列表类型的内存转换为linkedlist。
Redis使用了单线程架构和I/O多路复用的模型来实现高性能内存数据服务。
Redis每此客户端调用都经历了发送命令,执行命令和返回结果三个过程。所有命令都会进入一个队列中,然后被逐个执行,但是不会有两条命令被同时执行。
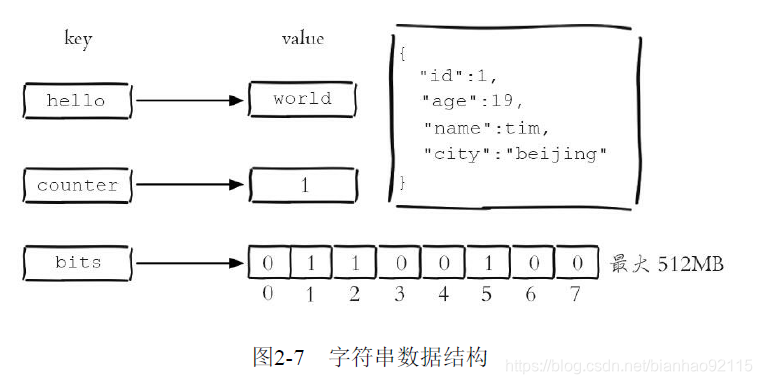
字符串类型是Redis最基础的数据结构,其他几种类型都是在字符串的基础上构建出来的。字符串类型的值可以是简单的字符串,复杂的字符串(JSON,XML),数字(整数和浮点数),甚至是二进制(图片,音频,视屏),但是不能超512M。
set方法,有一个参数选项,nx|xx,nx表示键必须不存在,才可以设置成功,用于添加,xx表示键必须存在,才可以设置成功,用于更新。
mget/mset 可以用来进行批量操作。
getset方法在set值的同时会返回上一次的值。
字符串类型的内部编码有三种,int:8个字节的长整型,embstr:小于39个字节的字符串,raw:大于39个字节的字符串。Redis会根据当前值的类型和长度决定使用哪种内部编码实现。
字符串类型的典型使用场景
1.缓存功能,Redis作为缓存层,MySQL作为存储层,绝大部分请求的数据都是从Redis中获取,Redis具有支撑高并发的特性,所以缓存通常能起到加速读写和降低后端压力的作用。
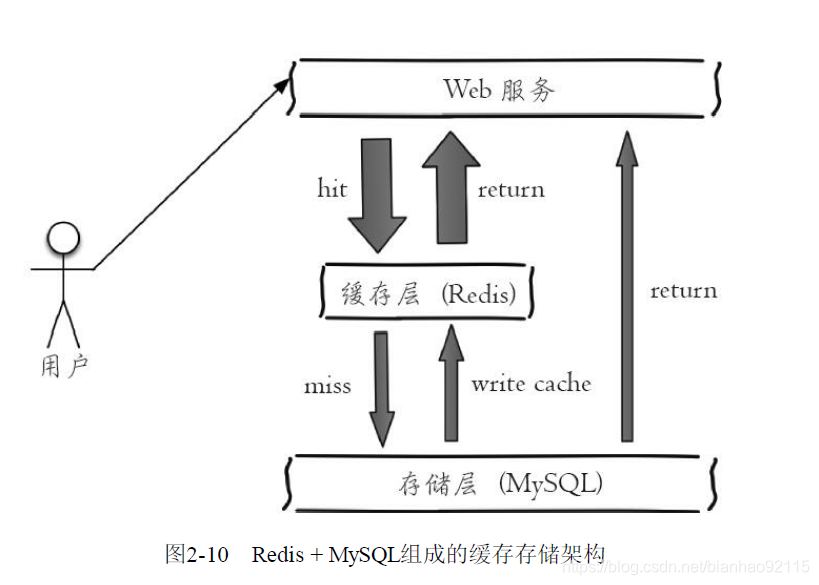
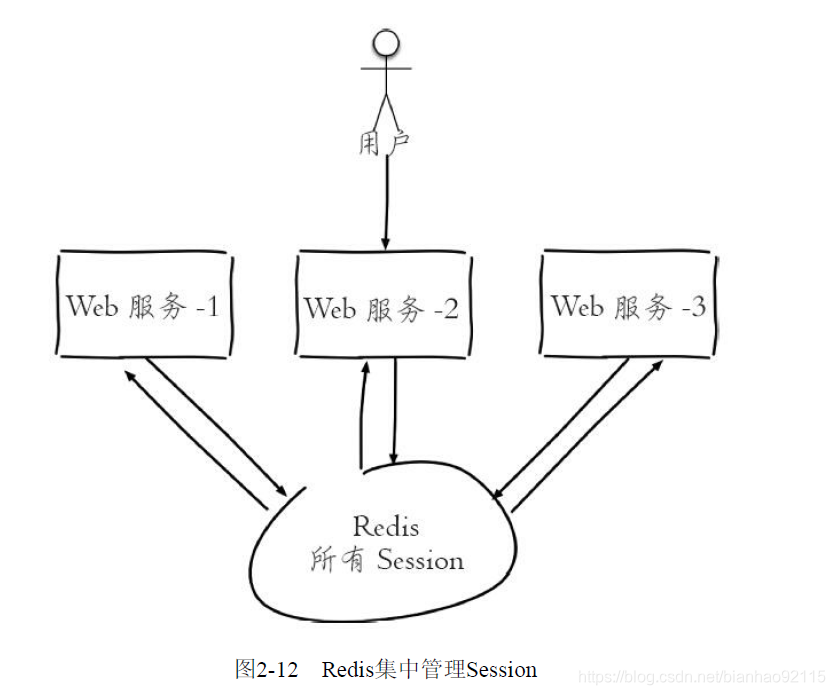
2.共享session
一个分布式web服务将用户的Session信息保存在各自服务器中,可能会有Session不同步的问题。为了解决这个问题,可以使使用Redis将用户的Session进行集中管理。每次用户更新或者查询登陆信息都直接从Redis中获取。
3.限速
为了短信接口不被频繁访问,会限制用户每分钟获取验证码的频率,这个功能可以使用Redis来实现。
SET key value EX 60 NX
哈希类型
哈希类型值的是值本身又是一个键值对结构。
hset key field value
hset user:1 name tom
hget user:1 name => tom
hdel key field 删除某个field
hlen key 计算field个数
哈希类型的内部编码方式有两种,一种是ziplist 压缩列表,一种是hashtable哈希表,压缩列表占用的内存更小,对于元素个数(512个)和值的大小(64个字节)都有限制。当超过ziplist的条件时,Redis会使用hashtable作为哈希的内部是西安。
使用场景
可以用来保存用户信息:
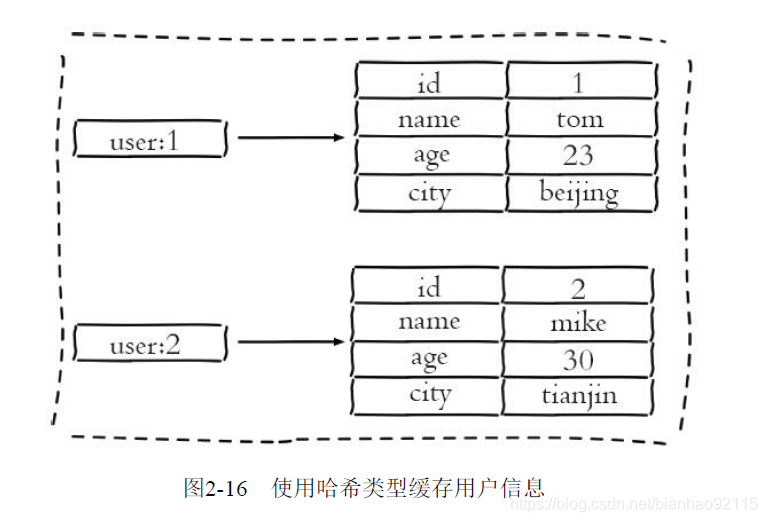
三种保存用户信息的方法的优缺点:
1)原生字符串类型:每个属性一个键
set user:1 name tom
set user:1 age 23
set user:1 city beijing
优点:简单直观,每个属性都支持更新操作。
缺点:占用的键过多,占用内存较大。
2)序列化字符串,将用户信息序列化后用一个键保存。
set user:1 serialize(userinfo)
优点:简化编程,如果合理化使用可以提高内存效率。
缺点:序列化和反序列化有一定的开销。
3)哈希类型:每个用户属性使用一对field-value,但是只用一个键保存。
hset user:1 name tom age 23 city beijing
优点:简单直观,如果合理使用可以减少内存空间的使用。
缺点:要控制哈希在ziplist和hashtable两种内部编码的转换,hashtable会消耗更多内存。
列表
列表类型是用来存储多个有序的字符串。a,b,c,d,e五个元素从左到右组成了一个有序的列表,列表中每个字符串称为元素。Redis中,可以对列表两端插入(push)和弹出(pop),还可以获得指定范围的元素列表,获取指定索引下标的元素。列表的元素时有序的。
编码方式有ziplist(压缩列表)和linkedlist(链表)。当元素个数小于512个,同时每个元素的值小于64个字节时,Redis会使用ziplist来作为列表的内部实现。linkedlist:当列表无法满足ziplist的条件时,Redis会使用linkedlist作为列表的内部实现。
使用场景
1)消息队列
Redis的lpush+brpop命令组合即可实现阻塞队列,生产者客户端使用lpush从列表左侧插入元素,多个消费者客户端使用brpop命令阻塞式的从列表尾部抢元素。
2)文章列表
每个用户都有属于自己的文章列表,现在需要分页展示。此时可以考虑使用列表,因为列表不但有序,同时支持按照索引范围获取元素。
集合
集合类型也是用来保存多个的字符串元素,但和列表类型不一样的是,集合中不允许有重复元素。并且结合中的元素时无序的,不能通过索引下标获取元素。Redis除了支持集合内的增删改查,还支持多个集合取交集,并集,差集。
集合内部编码有两种:
intset(整数集合):当结合中所有元素都是整数且个数小于512个时,Redis会选用intset作为集合内部实现。当集合类型无法满足intset条件时,会使用hashtable作为集合内部实现。
使用场景:
标签,用户的兴趣,可以计算用户共同感兴趣的标签等等。
sadd = 标签
spop/srandmember = 生成随机数,比如抽奖
add + sinter = 社交需求。


















 3万+
3万+



 到【灌水乐园】发言
到【灌水乐园】发言







