







"上周三凌晨2点,我突然被CEO电话惊醒:'为什么竞品的新功能比我们早上线3天?!' 看着团队手忙脚乱查数据的模样,我默默打开了Python..."
【技术选型】
🕷️ 对比:Scrapy vs 传统爬虫
# 性能对比实验代码片段
import time
from scrapy import Selector
from bs4 import BeautifulSoup
# 测试Scrapy解析速度
deftest_scrapy():
start = time.time()
for _ inrange(1000):
selector = Selector(text=html_content)
price = selector.css('span.price::text').get()
print(f"Scrapy耗时:{time.time()-start:.4f}s")
# 测试BeautifulSoup解析速度
deftest_bs4():
start = time.time()
for _ inrange(1000):
soup = BeautifulSoup(html_content,'lxml')
price = soup.find('span', class_='price').text
print(f"BS4耗时:{time.time()-start:.4f}s")✅ 实测结果:Scrapy解析速度快3.8倍
【实战教学】分步骤代码详解
🎯 步骤一:创建监控蜘蛛(含防封技巧)
import scrapy
from fake_useragent import UserAgent
classCompetitorSpider(scrapy.Spider):
name ='competition_monitor'
# 动态生成Header
defstart_requests(self):
urls =['https://competitor.com/product1','https://competitor.com/product2']
for url in urls:
yield scrapy.Request(
url=url,
callback=self.parse,
headers={
'User-Agent': UserAgent().random},
meta={
'proxy':'http://127.0.0.1:7890'}# 代理配置
)
# 智能重试机制
defparse(self, response):
if response.status !=200:
yield scrapy.Request(response.url, dont_filter=True)
yield{
'product_name': response.css('h1.product-title::text').get().strip(),
'price': response.xpath('//meta[@itemprop="price"]/@content').get(),
'update_time': response.css('div.update-time::attr(data-timestamp)').get(),
'secret_tag': response.css('script:contains("specialOffer")').re_first(r'\"offerId\":\"(.*?)\"')
}
【数据存储】📈 实时监控看板
from itemadapter import ItemAdapter
import pymongo
import pandas as pd
classMongoPipeline:
def__init__(self, mongo_uri):
self.client = pymongo.MongoClient(mongo_uri)
self.db = self.client['competitor_monitor']
@classmethod
deffrom_crawler(cls, crawler):
return cls(mongo_uri=crawler.settings.get('MONGO_URI'))
defprocess_item(self, item, spider):
collection = self.db[spider.name]
collection.insert_one(ItemAdapter(item).asdict())
# 自动生成日报
if pd.Timestamp.now().hour ==8:
df = pd.DataFrame(list(collection.find()))
daily_report = df.groupby('product_name').agg({
'price':['min','max','mean'],
'update_time':'count'
})
self.db['daily_reports'].insert_one(daily_report.to_dict())
【部署方案】🚀 云服务器自动化
# 使用Crontab设置定时任务
0 */3 * * * cd /opt/monitor && scrapy crawl competition_monitor
*/15 * * * * python /opt/monitor/alert.py # 价格异动报警文末彩蛋:
评论、关注、后台回复"监控系统"获取:
- 完整可运行的GitHub仓库(含代理池配置)
- 电商平台XPath选择器速查表
- 价格监控异常预警脚本
互动:
"你在竞品分析中踩过哪些坑?欢迎在评论区分享,点赞前三送《Scrapy反爬破解指南》电子书"
传统人工监控 vs 自动化系统
时间成本:40小时/周 → 0.5小时/周
数据时效性:3天延迟 → 实时更新
监控维度:5个 → 200+个
最后,我精心筹备了一份全面的Python学习大礼包,完全免费分享给每一位渴望成长、希望突破自我现状却略感迷茫的朋友。无论您是编程新手还是希望深化技能的开发者,都欢迎加入我们的学习之旅,共同交流进步!
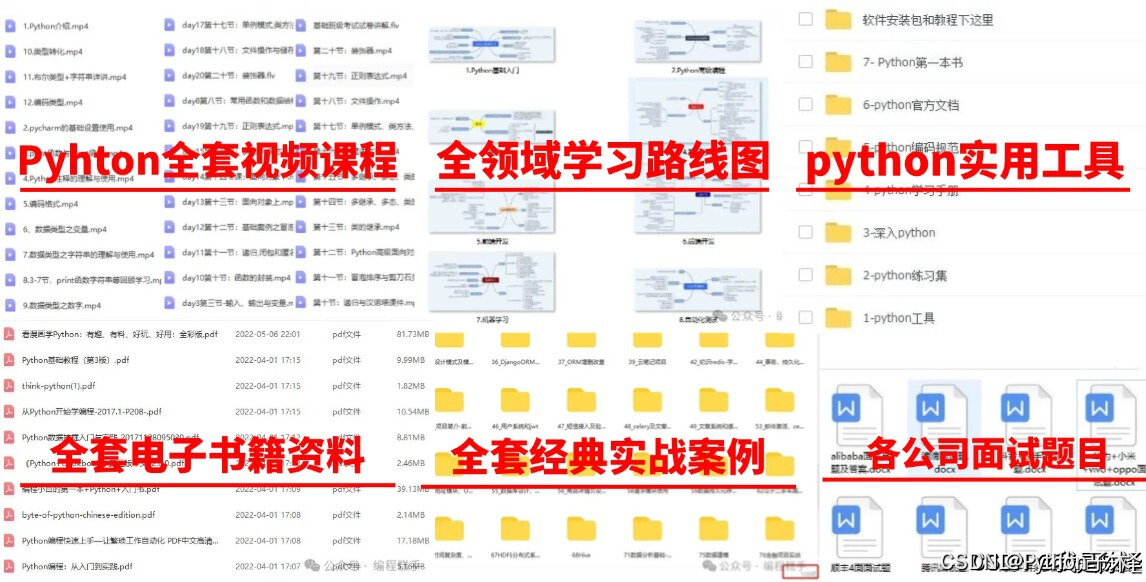
🌟 学习大礼包包含内容:
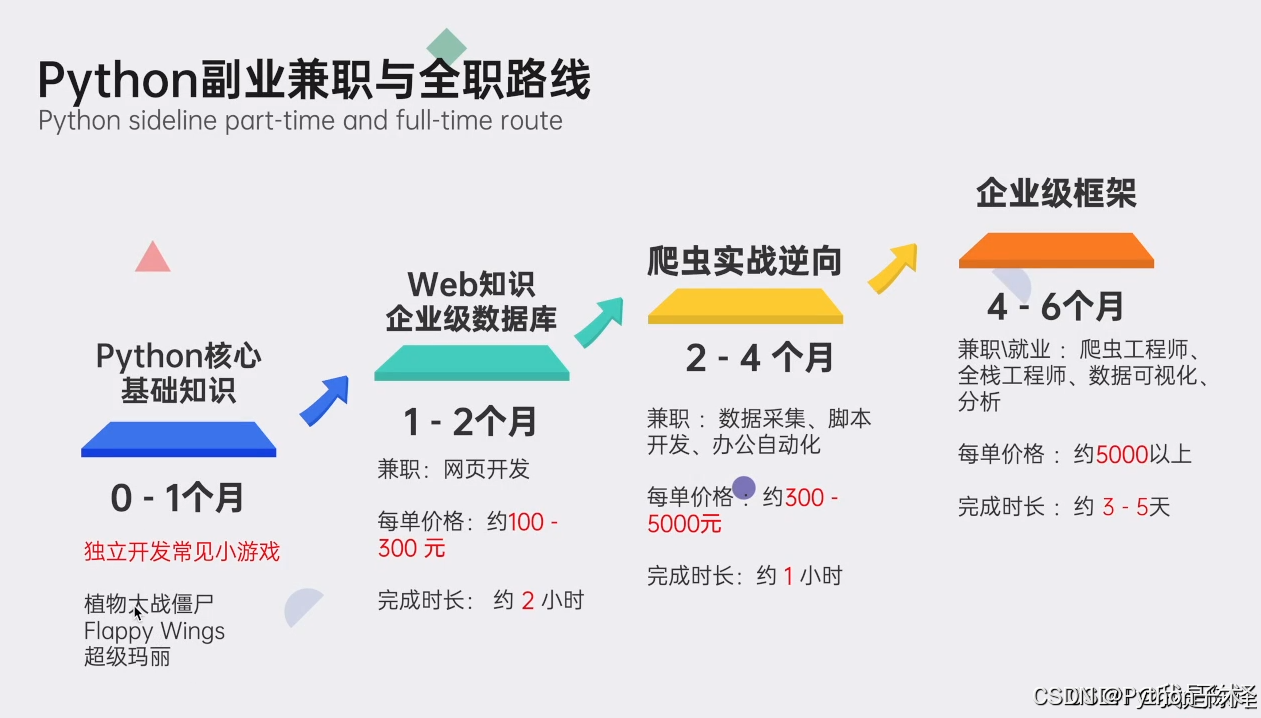
Python全领域学习路线图:一目了然,指引您从基础到进阶,再到专业领域的每一步学习路径,明确各方向的核心知识点。
超百节Python精品视频课程:涵盖Python编程的必备基础知识、高效爬虫技术、以及深入的数据分析技能,让您技能全面升级。
实战案例集锦:精选超过100个实战项目案例,从理论到实践,让您在解决实际问题的过程中,深化理解,提升编程能力。
华为独家Python漫画教程:创新学习方式,以轻松幽默的漫画形式,让您随时随地,利用碎片时间也能高效学习Python。
互联网企业Python面试真题集:精选历年知名互联网企业面试真题,助您提前备战,面试准备更充分,职场晋升更顺利。
👉 立即领取方式:只需【点击这里】,即刻解锁您的Python学习新篇章!让我们携手并进,在编程的海洋里探索无限可能

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









