







人体检测和跟踪是一项基本的计算机视觉任务,涉及在给定场景中识别并跟踪个体的移动。这项技术在各种实际应用中发挥着关键作用,从监视和安全到自动驾驶车辆和人机交互都有涉及。人体检测的主要目标是在图像或视频帧中定位和分类人体,而跟踪侧重于在这些个体在不同帧之间移动时保持连续性,以便进行监测和分析。
本教程分为三个部分,旨在指导您创建自己的人体检测和跟踪系统。它利用了YOLOv8检测算法和多种跟踪方法。检测模型经过精心训练,使用了HumanCrowd(HC)数据集和多目标跟踪(MOT)数据集。在本文中,我们将带领您完成为此项目准备数据的过程。
这里插播一条粉丝福利,如果你在学习Python或者有计划学习Python,想在未来人工智能领域吃上一口饭的,可以点击这里获取最新的Python学习资料和学习路线规划(免费分享,记得关注)
为了开发和评估人体检测和跟踪算法,研究人员和从业者通常依赖于提供各种真实场景和挑战的大型数据集。在这一领域中两个显著的数据集是CrowdHuman和多目标跟踪(MOT)数据集。
CrowdHuman数据集:
CrowdHuman是一个广泛使用的人体检测数据集。它包含超过15,000张带有人体实例注释的图像。CrowdHuman的独特之处在于其多样性,包括拥挤的场景、遮挡以及各种姿势和尺度。该数据集共包括15,000张图像,分为4,370张用于验证和5,000张用于测试,以及训练集。CrowdHuman的注释详尽,并涵盖了各种场景。

CrowdHuman数据集包含每个人的全身、可见身体和头部边界框注释的基准数据
在该数据集中,训练和验证子集中的个体人数总计达到惊人的470,000,每张图像平均有22.6名行人。此外,提供了详细的注释,包括可见区域的边界框、头部区域的边界框以及全身注释,确保了对人体检测研究而言是一种全面且宝贵的资源。数据首先使用以下代码转换为COCO格式:
def crowdhuman_to_coco(DATA_PATH, OUT_PATH, SPLITS= ['val', 'train'], DEBUG=False):if OUT_PATH is None:OUT_PATH = DATA_PATH + 'annotations/'if not os.path.exists(OUT_PATH):os.makedirs(OUT_PATH, exist_ok=True)for split in SPLITS:data_path = DATA_PATH + splitout_path = OUT_PATH + '{}.json'.format(split)out = {'images': [], 'annotations': [], 'categories': [{'id': 1, 'name': 'person'}]}ann_path = DATA_PATH + 'annotation_{}.odgt'.format(split)anns_data = load_func(ann_path)image_cnt = 0ann_cnt = 0video_cnt = 0for ann_data in tqdm(anns_data):image_cnt += 1file_path = DATA_PATH + split + '/Images/{}.jpg'.format(ann_data['ID'])assert os.path.isfile(file_path)im = Image.open(file_path)image_info = {'file_name': 'Images/{}.jpg'.format(ann_data['ID']),'id': image_cnt,'height': im.size[1],'width': im.size[0]}out['images'].append(image_info)if split != 'test':anns = ann_data['gtboxes']for i in range(len(anns)):if anns[i]['tag'] == 'mask':continue # ignore non-humanassert anns[i]['tag'] == 'person'ann_cnt += 1fbox = anns[i]['fbox'] # fbox means full body boxann = {'id': ann_cnt,'category_id': 1,'image_id': image_cnt,'track_id': -1,'bbox_vis': anns[i]['vbox'],'bbox': fbox,'area': fbox[2] * fbox[3],'iscrowd': 1 if 'extra' in anns[i] and \'ignore' in anns[i]['extra'] and \anns[i]['extra']['ignore'] == 1 else 0}out['annotations'].append(ann)print('loaded {} for {} images and {} samples'.format(split, len(out['images']), len(out['annotations'])))json.dump(out, open(out_path, 'w'))
在这里,我们只考虑人类类别并忽略头部位置的边界框。
多目标跟踪(MOT)数据集:
另一方面,MOT数据集专门设计用于人体跟踪任务。这些数据集包含视频序列,并提供了关于在帧之间移动的个体人的跟踪注释。MOT数据集对于评估跟踪算法的稳健性和准确性至关重要,因为它们提供了地面实况数据,以衡量算法在长时间内能够一致地跟踪和识别个体的能力。著名的MOT数据集包括MOT17和MOT20,每个都包含各种具有挑战性的场景,使其对跟踪研究至关重要。
COCO(上下文中的通用对象)格式数据集和YOLO(You Only Look Once)格式数据集是用于目标检测和图像识别任务的两种广泛使用的数据格式,各自具有其特定的结构和目的。以下是每种格式的概述:
COCO格式数据集:
{"images": [{"file_name": "000001.jpg","height": 500,"width": 353,"id": 1}, {...}, {"file_name": "009962.jpg","height": 375,"width": 500,"id": 9962}, {"file_name": "009963.jpg","height": 500,"width": 374,"id": 9963}],"type": "instances","annotations": [{"segmentation": [[47, 239, 47, 371, 195, 371, 195, 239]],"area": 19536,"iscrowd": 0,"image_id": 1,"bbox": [47, 239, 148, 132],"category_id": 12,"id": 1,"ignore": 0}, {"segmentation": [[138, 199, 138, 301, 207, 301, 207, 199]],"area": 7038,"iscrowd": 0,"image_id": 2,"bbox": [138, 199, 69, 102],"category_id": 19,"id": 3,"ignore": 0}, {...}, {"segmentation": [[1, 2, 1, 500, 374, 500, 374, 2]],"area": 185754,"iscrowd": 0,"image_id": 9963,"bbox": [1, 2, 373, 498],"category_id": 7,"id": 14976,"ignore": 0}],"categories": [{"supercategory": "none","id": 1,"name": "aeroplane"}, {"supercategory": "none","id": 2,"name": "bicycle"}, {"supercategory": "none","id": 3,"name": "bird"}, {"supercategory": "none","id": 4,"name": "boat"}, {...}, {"supercategory": "none","id": 19,"name": "train"}, {"supercategory": "none","id": 20,"name": "tvmonitor"}]}
注释结构:
COCO数据集格式以其结构化和全面的注释而闻名。数据集中的每个图像都与一个包含有关图像中存在的对象的信息的JSON文件相关联。注释通常包括对象类别、边界框坐标、分割掩膜以及姿势估计的关键点等详细信息。COCO还支持关键点检测、对象关系等方面的注释。
YOLO(You Only Look Once)格式数据集:
注释结构:YOLO格式数据集专门设计用于目标检测任务。YOLO的注释通常存储在与每个图像相关联的文本文件中,与COCO相比,其格式更简单。文件夹结构定义如下:
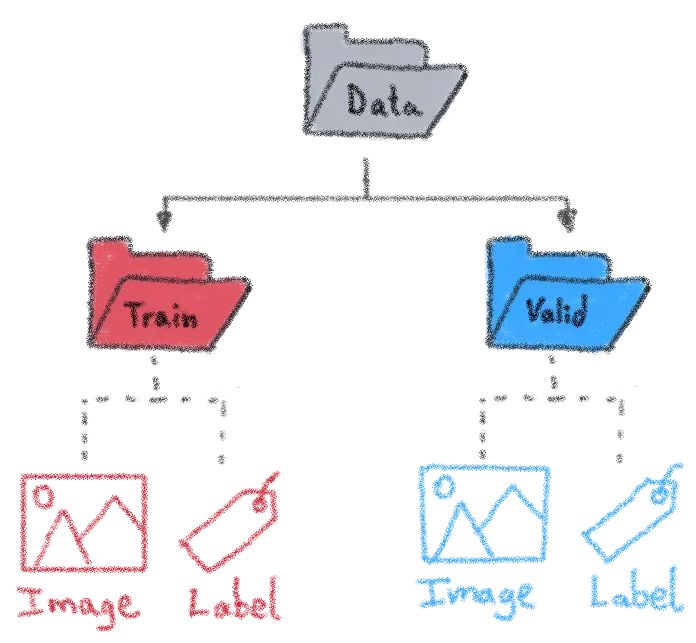
在“Label”文件夹中,有一些与“Image”文件夹中的图像名称相似的文本文件。在每个文本文件中,YOLO格式提供了有关图像中每个对象的详细信息,如对象类别和边界框的坐标(class_id、中心 x、中心 y、宽度和高度),这些坐标是相对于图像尺寸进行标准化的。
这里,我为您精心准备了一份全面的Python学习大礼包,完全免费分享给每一位渴望成长、希望突破自我现状却略感迷茫的朋友。无论您是编程新手还是希望深化技能的开发者,都欢迎加入我们的学习之旅,共同交流进步!
🌟 学习大礼包包含内容:
Python全领域学习路线图:一目了然,指引您从基础到进阶,再到专业领域的每一步学习路径,明确各方向的核心知识点。
超百节Python精品视频课程:涵盖Python编程的必备基础知识、高效爬虫技术、以及深入的数据分析技能,让您技能全面升级。
实战案例集锦:精选超过100个实战项目案例,从理论到实践,让您在解决实际问题的过程中,深化理解,提升编程能力。
华为独家Python漫画教程:创新学习方式,以轻松幽默的漫画形式,让您随时随地,利用碎片时间也能高效学习Python。
互联网企业Python面试真题集:精选历年知名互联网企业面试真题,助您提前备战,面试准备更充分,职场晋升更顺利。
👉 立即领取方式:只需【点击这里】,即刻解锁您的Python学习新篇章!让我们携手并进,在编程的海洋里探索无限可能!



















 440
440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









