




 本文介绍如何使用AlexNet进行工程化实现,通过自定义数据集完成三分类任务。详细展示了模型训练代码,包括数据预处理、模型构建、训练及测试流程。适合希望深入理解AlexNet模型及其实战应用的读者。
本文介绍如何使用AlexNet进行工程化实现,通过自定义数据集完成三分类任务。详细展示了模型训练代码,包括数据预处理、模型构建、训练及测试流程。适合希望深入理解AlexNet模型及其实战应用的读者。
本文重在将AlexNet进行工程化实现,使用自己的数据进行训练,完成一个三分类的任务。
训练模型代码如下所示:
# -*- coding: utf-8 -*-
"""
Created on Thu May 30 16:22:42 2019
@author: 666
"""
import os, shutil, random, glob
import cv2
import numpy as np
# os.environ["CUDA_VISIBLE_DEVICES"] = "2"
# CUDA_VISIBLE_DEVICES = 2
import keras
from keras.optimizers import SGD
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D, ZeroPadding2D, BatchNormalization
import matplotlib.pyplot as plt
#训练的第一类图片个数
ifv_num = 191
#训练的第二类图片个数
person_num = 247
#训练的第三类图片个数
tank_num = 217
#训练数据总个数
train_num = 655
#测试数据总个数
test_num = 191
resize = 227
def load_data():
# imgs = os.listdir("./train/")
# num = len(imgs)
train_data = np.empty((train_num, resize, resize, 3), dtype="int32")
train_label = np.empty((train_num, ), dtype="int32")
test_data = np.empty((test_num, resize, resize, 3), dtype="int32")
test_label = np.empty((test_num, ), dtype="int32")
#train——data 的数据和标签
for i in range(ifv_num):
train_data[i] = cv2.resize(cv2.imread('G:/AI/module_3/train/ALL/' + 'ifv' + str(i) + '.jpg'), (resize, resize))
train_label[i] = 0
for i in range(person_num):
train_data[i+ifv_num] = cv2.resize(cv2.imread('G:/AI/module_3/train/ALL/' + 'preson' + str(i) + '.jpg'), (resize, resize))
train_label[i+ifv_num] = 1
for i in range(tank_num):
train_data[i+ifv_num+person_num] = cv2.resize(cv2.imread('G:/AI/module_3/train/ALL/' + 'tank' + str(i) + '.jpg'), (resize, resize))
train_label[i+ifv_num+person_num] = 2
#test——data 的数据和标签
for i in range(61):
test_data[i] = cv2.resize(cv2.imread('G:/AI/module_3/test/ALL/' + 'ifv' + str(i) + '.jpg'), (resize, resize))
test_label[i] = 0
for i in range(62):
test_data[i+61] = cv2.resize(cv2.imread('G:/AI/module_3/test/ALL/' + 'preson' + str(i) + '.jpg'), (resize, resize))
test_label[i+61] = 1
for i in range(68):
test_data[i+123] = cv2.resize(cv2.imread('G:/AI/module_3/test/ALL/' + 'tank' + str(i) + '.jpg'), (resize, resize))
test_label[i+123] = 2
return train_data, train_label, test_data, test_label
train_data, train_label, test_data, test_label = load_data()
train_data, test_data = train_data.astype('float32'), test_data.astype('float32')
train_data, test_data = train_data/255, test_data/255
#将数据打乱,很重要
np.random.seed(200)
np.random.shuffle(train_data)
np.random.seed(200)
np.random.shuffle(train_label)
np.random.seed(200)
np.random.shuffle(test_data)
np.random.seed(200)
np.random.shuffle(test_label)
train_label = keras.utils.to_categorical(train_label, 3)
test_label = keras.utils.to_categorical(test_label, 3)
# AlexNet
model = Sequential()
#第一段
model.add(Conv2D(filters=96, kernel_size=(11,11),
strides=(4,4), padding='valid',
input_shape=(resize,resize,3),
activation='relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(3,3),
strides=(2,2),
padding='valid'))
#第二段
model.add(Conv2D(filters=256, kernel_size=(5,5),
strides=(1,1), padding='same',
activation='relu'))
model.add(BatchNormalization())
model.add(MaxPooling2D(pool_size=(3,3),
strides=(2,2),
padding='valid'))
#第三段
model.add(Conv2D(filters=384, kernel_size=(3,3),
strides=(1,1), padding='same',
activation='relu'))
model.add(Conv2D(filters=384, kernel_size=(3,3),
strides=(1,1), padding='same',
activation='relu'))
model.add(Conv2D(filters=256, kernel_size=(3,3),
strides=(1,1), padding='same',
activation='relu'))
model.add(MaxPooling2D(pool_size=(3,3),
strides=(2,2), padding='valid'))
#第四段
model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1000, activation='relu'))
model.add(Dropout(0.5))
# Output Layer,dense(x) x为分类的类别个数
model.add(Dense(3))
model.add(Activation('softmax'))
model.compile(loss='categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
model.fit(train_data, train_label,
batch_size = 64,
epochs = 100,
validation_split = 0.2,
shuffle = True)
model.save(r'G:\AI\module_3\alexnet.h5')
训练数据如下:
注意更改对应的类别数,还有路径。
存放的图片命名:类别x.jpg(x = 0,1,2,.......),格式为jpg的
模型训练好之后,会产生一个 .h5 的文件,这个就是自己训练的最终模型。
训练模型的过程如下:
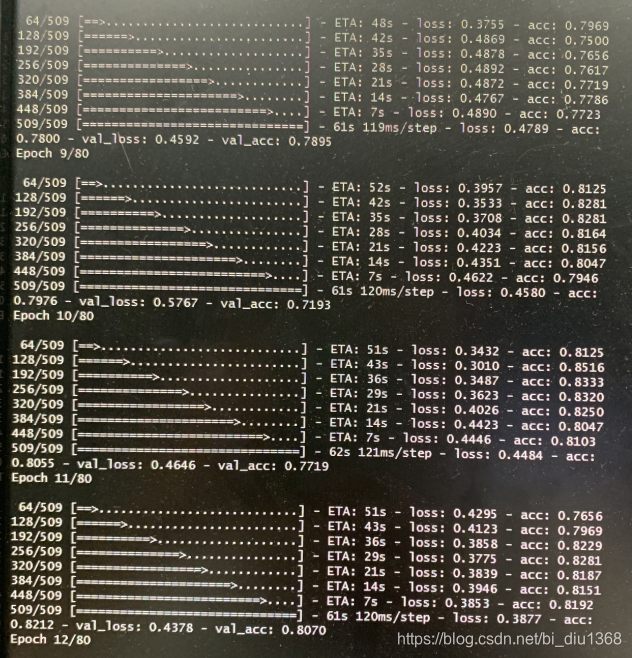
测试代码如下所示:
# -*- coding: utf-8 -*-
"""
Created on Tue May 28 17:29:12 2019
@author: 666
"""
import matplotlib
matplotlib.use('Agg')
import os
from keras.models import load_model
import numpy as np
from PIL import Image
import cv2
#所分类别每一个的数目
ifv = 61.0
person = 62.0
tank = 68.0
#在当前文件夹之下,新建一个1.txt,用来存放模型测试之后的结果
f=open('./1.txt',mode='a+')
#加载模型h5文件
model_path = 'G:\\AI\\module_3\\alexnet.h5'
model = load_model(model_path)
model.summary()
#规范化图片大小和像素值
def get_inputs(src=[]):
pre_x = []
for s in src:
input = cv2.imread(s)
input = cv2.resize(input, (227, 227))
input = cv2.cvtColor(input, cv2.COLOR_BGR2RGB)
pre_x.append(input) # input一张图片
pre_x = np.array(pre_x) / 255.0
return pre_x
#要预测的图片保存在这里
predict_dir = 'G:\\AI\\test\\'
#这个路径下有三个文件,分别是ifv和person tank
test = os.listdir(predict_dir)
#打印后:['ifv', 'person', ‘tank’]
print(test)
#新建一个列表保存预测图片的地址
i = 0
j = 0
images = []
#获取每张图片的地址,并保存在列表images中
for testpath in test:
#ifv 的 个数
a = 0
#person的个数
b = 0
#tank的个数
c = 0
for fn in os.listdir(os.path.join(predict_dir, testpath)):
if fn.endswith('jpg'):
fd = os.path.join(predict_dir, testpath, fn)
#print(fd)
images.append(fd)
#调用函数,规范化图片
pre_x = get_inputs(images)
pre_y = model.predict_classes(pre_x)
if int(pre_y[i]) == 0:
a = a+1
elif int(pre_y[i]) == 1:
b = b+1
else:
c = c+1
if int(pre_y[i]) != int(j):
print(fd)
print(int(pre_y[i]))
f.write(fd)
f.write(' ')
f.write(str(int(pre_y[i])))
f.write('\n')
i= i+1
print('ifv:' +str(a) + ' , person:' + str(b) + ' , tank:' + str(c))
f.write('ifv_num:' + str(a) + ' , person_num:'+str(b) + ' , tank:' + str(c))
#计算每个类别的正确率
if j == 0:
accuracy = float(a)/ifv
elif j == 1:
accuracy = float(b)/person
else:
accuracy = float(c)/tank
print('accuracy: '+str(accuracy))
f.write(' , accuracy: '+str(accuracy)+'\n')
f.write('----------------------------------------------------\n')
j = j+ 1
f.close()
测试数据格式:
测试过程如下:
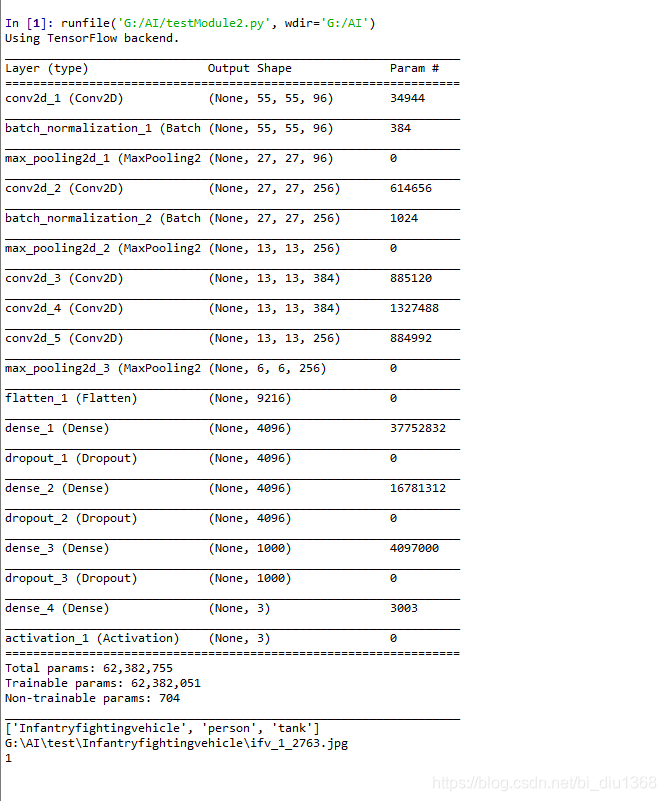
在当前路径下,所建的1.txt 所存的内容如下:
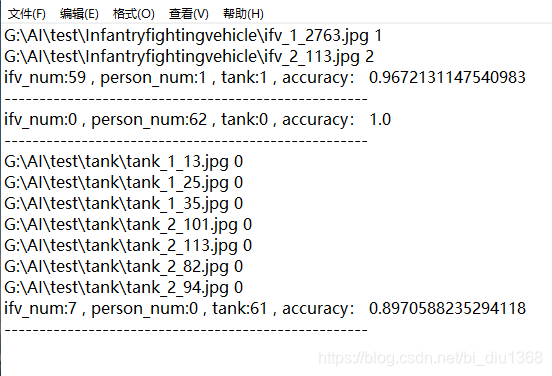
txt 文件解释:
G:\AI\test\Infantryfightingvehicle\ifv_2_113.jpg 2
前面是错误识别图片的路径,2 是识别错误的类别
ifv_num:59 , person_num:1 , tank:1 , accuracy: 0.9672131147540983
这个是在识别测试数据 ifv 的时候,分别识别成ifv,person,tank的数据,以及测试的准确率。


















 1349
1349

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









