







spark shuffle
shuffle分为map阶段和reducer阶段
map阶段
ShuffleManager
在driver和executor的sparkEnv中被创建.基于spark.shuffle.manager的设置.driver用它注册shuffle,executor(或在driver本地运行的任务)可以请求来读或写数据
/**
* Pluggable interface for shuffle systems. A ShuffleManager is created in SparkEnv on the driver
* and on each executor, based on the spark.shuffle.manager setting. The driver registers shuffles
* with it, and executors (or tasks running locally in the driver) can ask to read and write data.
*
*用于shuffle systems的可插拔接口.
*在driver和executor的sparkEnv中被创建.基于spark.shuffle.manager的设置.driver用它注册shuffle
* executor(或在driver本地运行的任务)可以请求来读或写数据
*
*
* NOTE: this will be instantiated by SparkEnv so its constructor can take a SparkConf and
* boolean isDriver as parameters.
*
* 注意这将被sparkEnv 实例化,所以它的构造可以将sparkCOnf和boolean inDriver作为参数
*/
private[spark] trait ShuffleManager {
/**
* Register a shuffle with the manager and obtain a handle for it to pass to tasks.
* 用这个manager注册一个shuffle,为它获取一个handle来传递给任务
*/
def registerShuffle[K, V, C](
shuffleId: Int,
numMaps: Int,
dependency: ShuffleDependency[K, V, C]): ShuffleHandle
/** Get a writer for a given partition. Called on executors by map tasks.
* 对于给定的分区得到一个writer,被mapTask在executor上调用 */
def getWriter[K, V](handle: ShuffleHandle, mapId: Int, context: TaskContext): ShuffleWriter[K, V]
/**
* Get a reader for a range of reduce partitions (startPartition to endPartition-1, inclusive).
* Called on executors by reduce tasks.
*得到一个关于范围reduce分区的reader(startPartition to endPartition-1包含)
* 在executor的reduce任务调用
*/
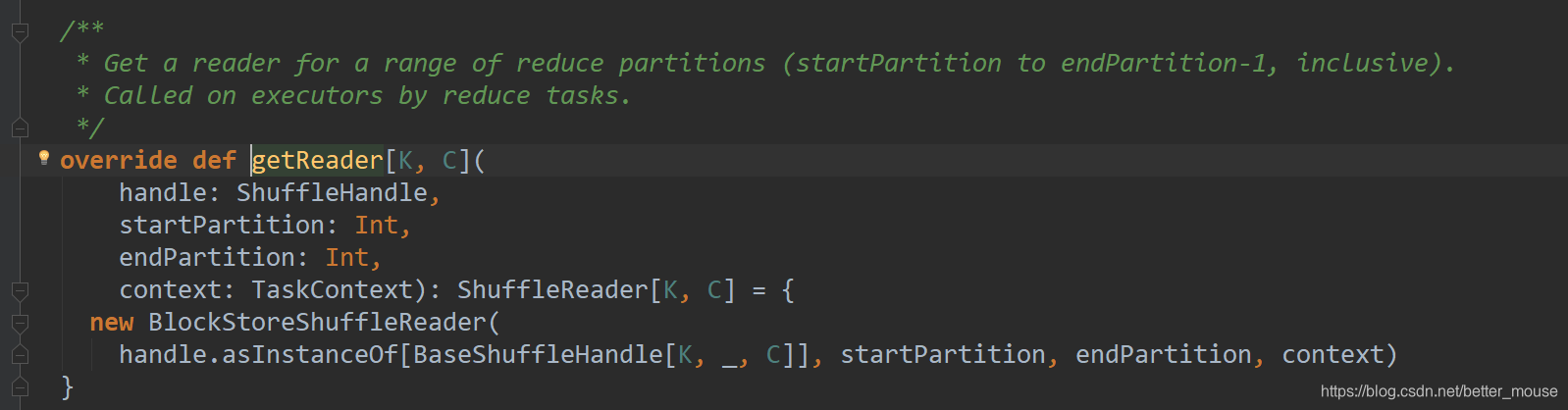
def getReader[K, C](
handle: ShuffleHandle,
startPartition: Int,
endPartition: Int,
context: TaskContext): ShuffleReader[K, C]
}
SortShuffleManager
在spark2.0.0以后,使用的都是SortShuffleManager
// Let the user specify short names for shuffle managers
val shortShuffleMgrNames = Map(
"sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName,
"tungsten-sort" -> classOf[org.apache.spark.shuffle.sort.SortShuffleManager].getName)
val shuffleMgrName = conf.get("spark.shuffle.manager", "sort")
val shuffleMgrClass =
shortShuffleMgrNames.getOrElse(shuffleMgrName.toLowerCase(Locale.ROOT), shuffleMgrName)
val shuffleManager = instantiateClass[ShuffleManager](shuffleMgrClass)
SortShuffleManager registerShuffle
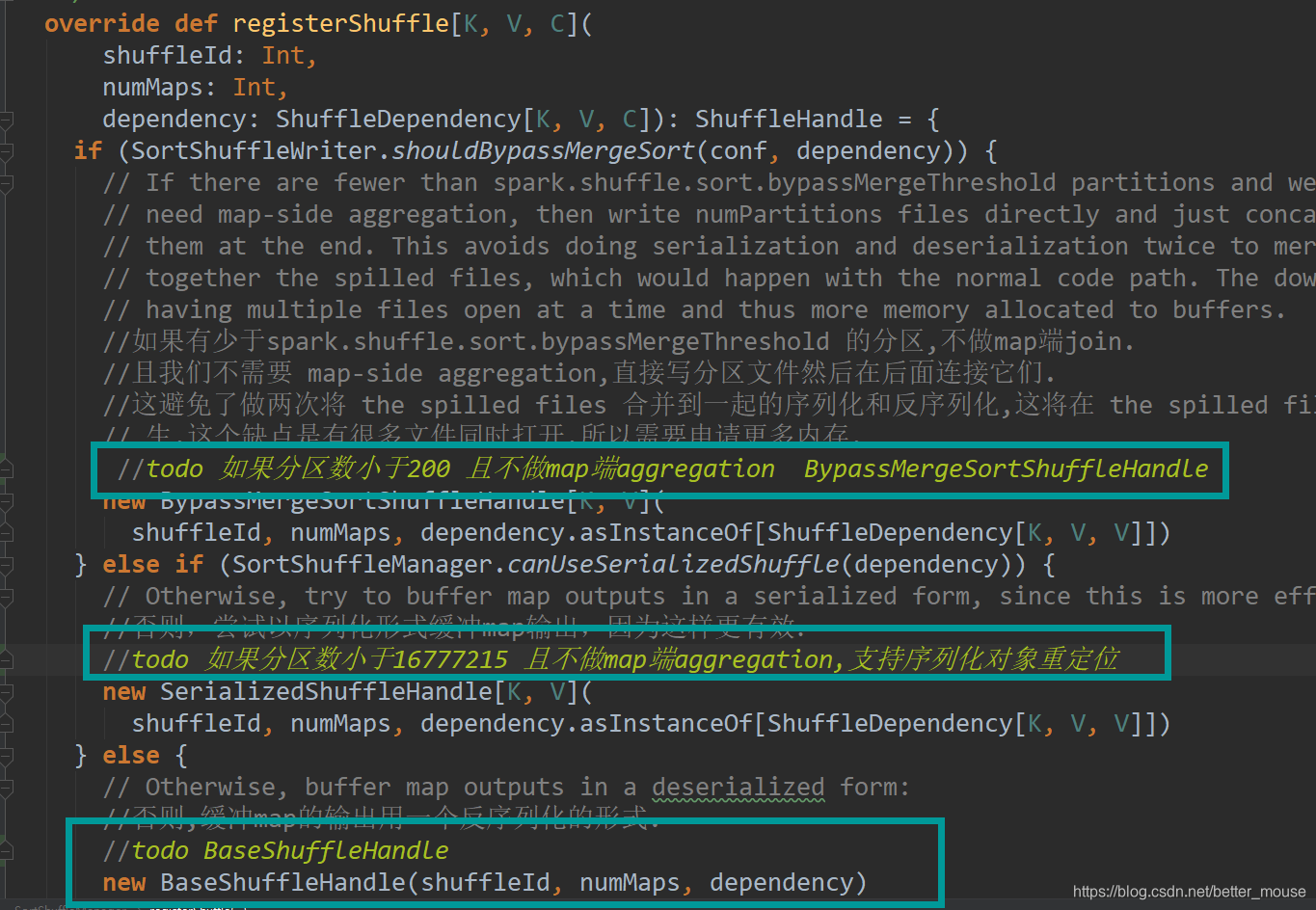
sort shuffle manager根据不同的内容选择不同的方式.
SortShuffleManager getWriter[K, V]
shuffle write 用在map阶段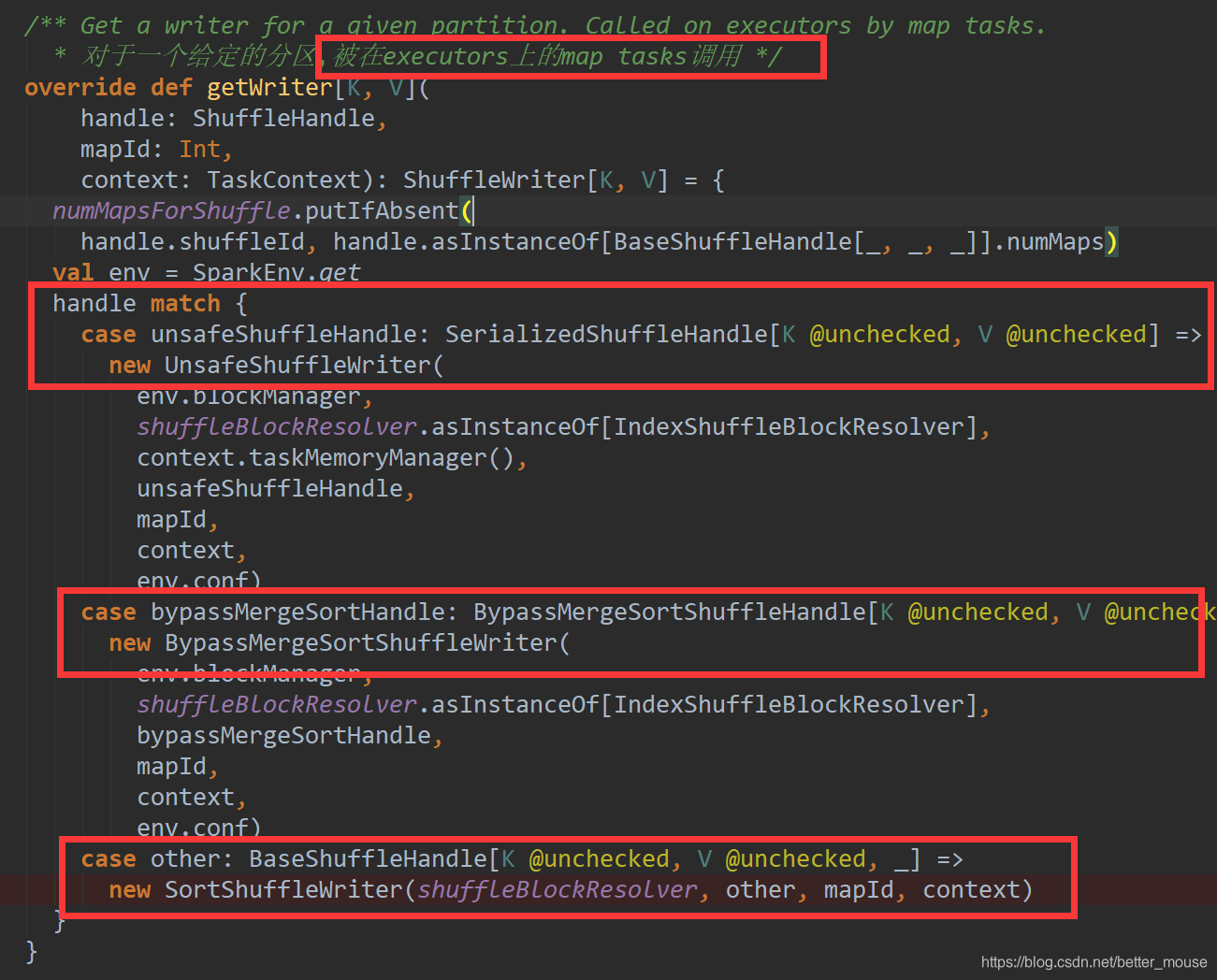
BypassMergeSortShuffleWriter
每个reduce分区写一个文件,最后合并起来,在没有ordering,没有Aggregator的时候使用
SortShuffleWriter
利用上面讲的ExternalSorter进行使用.外部排序.
UnsafeShuffleWriter
reduce
SortShuffleManager getReader
Get a reader for a range of reduce partitions (startPartition to endPartition-1, inclusive). Called on executors by reduce tasks.
得到reduce分区的reader 被executor的reduce task 调用.

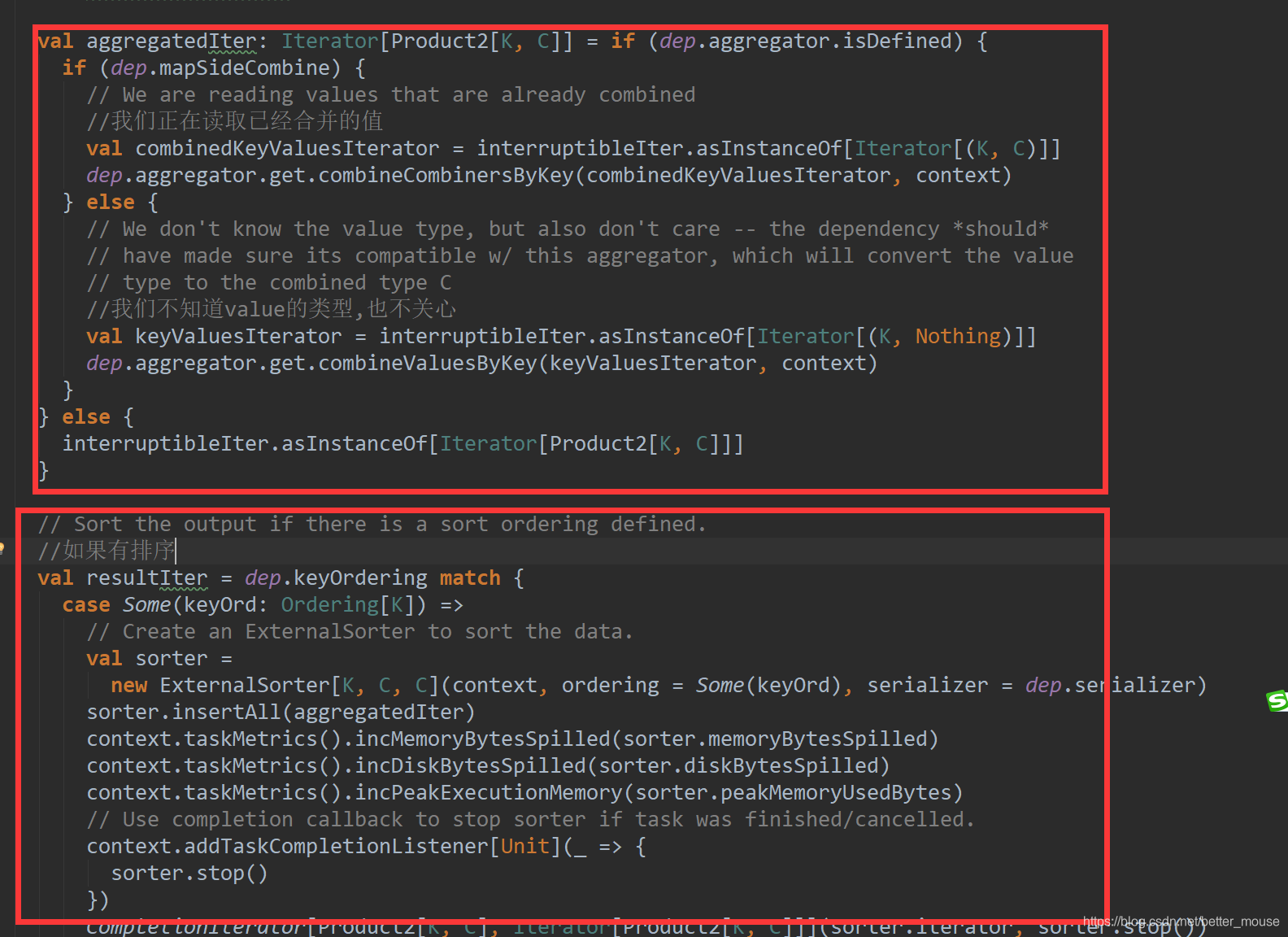
这里可以发现spark先做聚合,再做排序.也就是说它想避免掉排序的性能消耗.而mapreduce 在reduce端是先排序然后在做聚合.感觉如果是有排序的话,
reduce阶段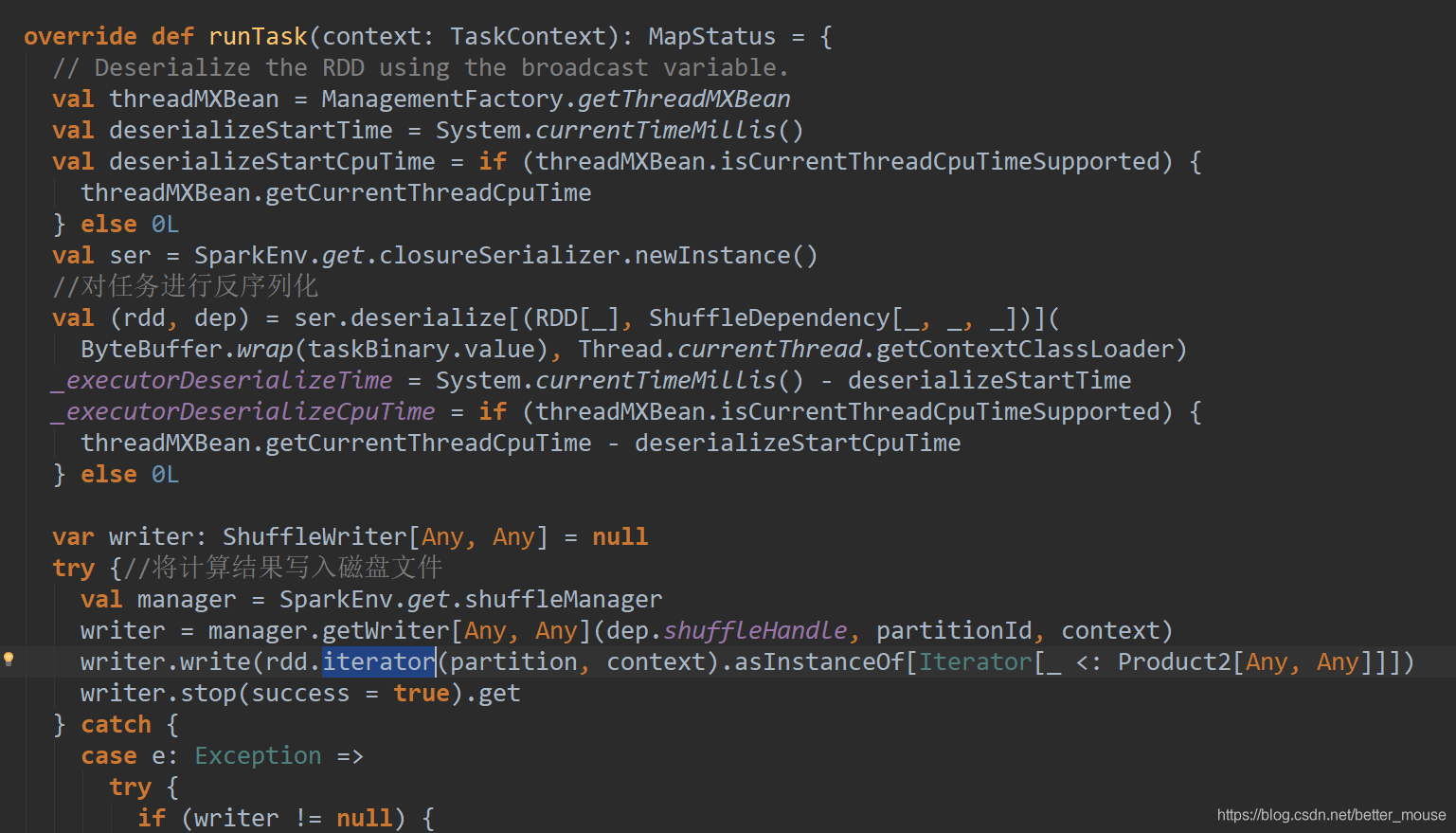

val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
writer.stop(success = true).get
getWriter 方法是在mapTask中执行的,
getReader方法也是在mapTask中执行的.
这里就不像hadoop 的map reduce明显的分了两个阶段.可以想一下是为啥.
回忆下hadoop的mapreduce
map reduce map阶段溢出排序好的文件,然后对文件做归并排序.
reduce阶段 拉取有序列文件,做归并排序.
combiner能够应用的前提是不能影响最终的业务逻辑
而且,combiner的输出kv应该跟reducer的输入kv类型要对应起来
spark 就没有这个限制,更灵活.


















 293
293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









