




文章目录
今天想跟大家扯扯一个老生常谈但又经常被搞混的话题——代码合并这点事儿。
说起合并代码,估计 git merge 大家都用烂了。不过它还有个"兄弟" git cherry-pick,虽然不太起眼,但关键时刻真的能救命。问题是,很多人(包括我之前)经常把这俩搞混,结果把项目历史弄得一团糟,后悔都来不及。
那这俩家伙到底啥区别?什么时候该用哪个?别急,我们慢慢聊。
老朋友:git merge —— 大河东去,海纳百川
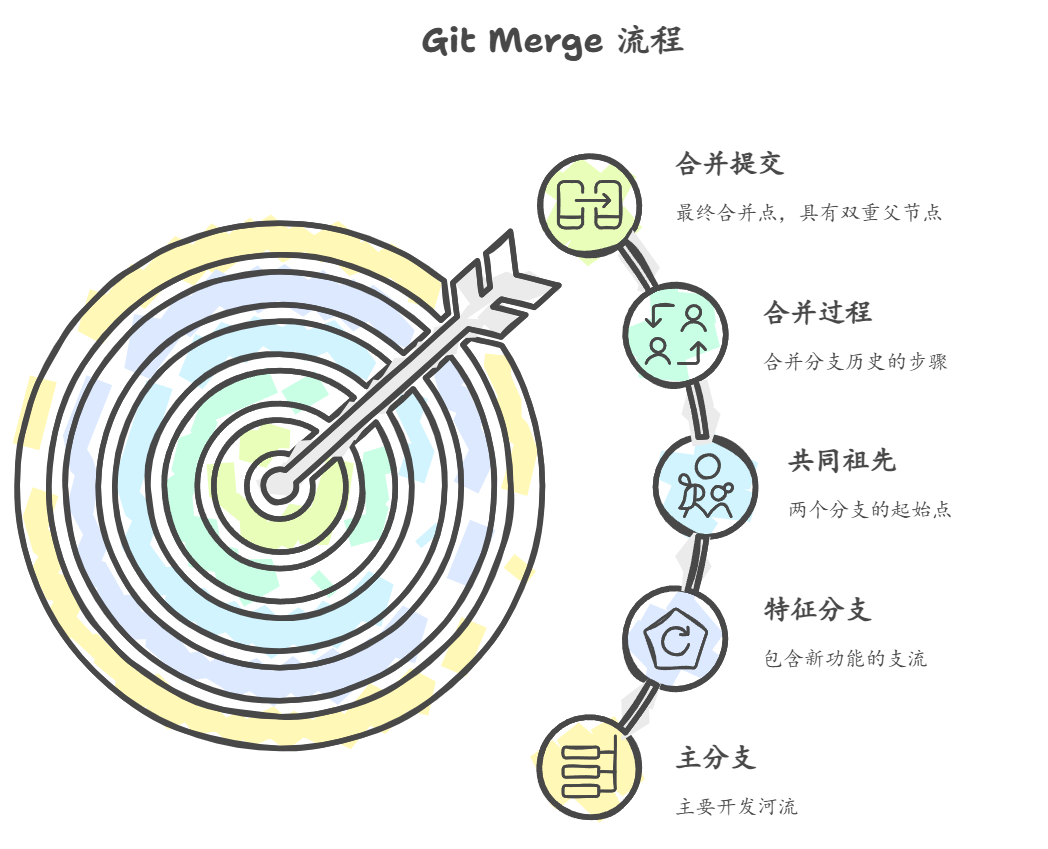
先说说大家最熟悉的 merge。我喜欢把它想象成这样:你的 master 分支是条主河道,然后你在旁边开了条支流(比如 feature 分支)搞开发。等功能做完了、测试也过了,是时候让这条支流回归主河道了。这时候 merge 就派上用场了。
它的思路很简单:把整个分支的历史都给你合并进来,一个不落。
具体怎么干的呢?
你站在 master 上,敲个 git merge feature/user-center,Git 就开始忙活了:
- 先找到两个分支的"共同祖先"(就是它们分叉的那个点)
- 把
feature分支从那之后的所有提交都拿过来,跟master的提交一起合并 - 在
master上生成一个特殊的合并提交,这家伙有两个"爸爸"——一个指向master的最新提交,一个指向feature的最新提交
# 标准操作流程,应该都很眼熟
git checkout master
git fetch origin
git pull origin master
git merge feature/user-center
git push origin master
merge 的好处显而易见:
- 历史记录贼清楚:谁都能看出来什么时候合并的什么分支,整个开发过程一目了然
- 追溯问题不头疼:用
git log --graph一看,分支合并的轨迹清清楚楚 - 操作傻瓜化:想合并整个功能?一个命令搞定
但也有让人头疼的地方:
- 历史图谱像麻花:分支多了真的看着乱,有时候理解主线发展都费劲
- 要么全要,要么不要:想只合并分支里的某个改动?不好意思,做不到
外科手术刀:git cherry-pick —— 想要哪个拿哪个
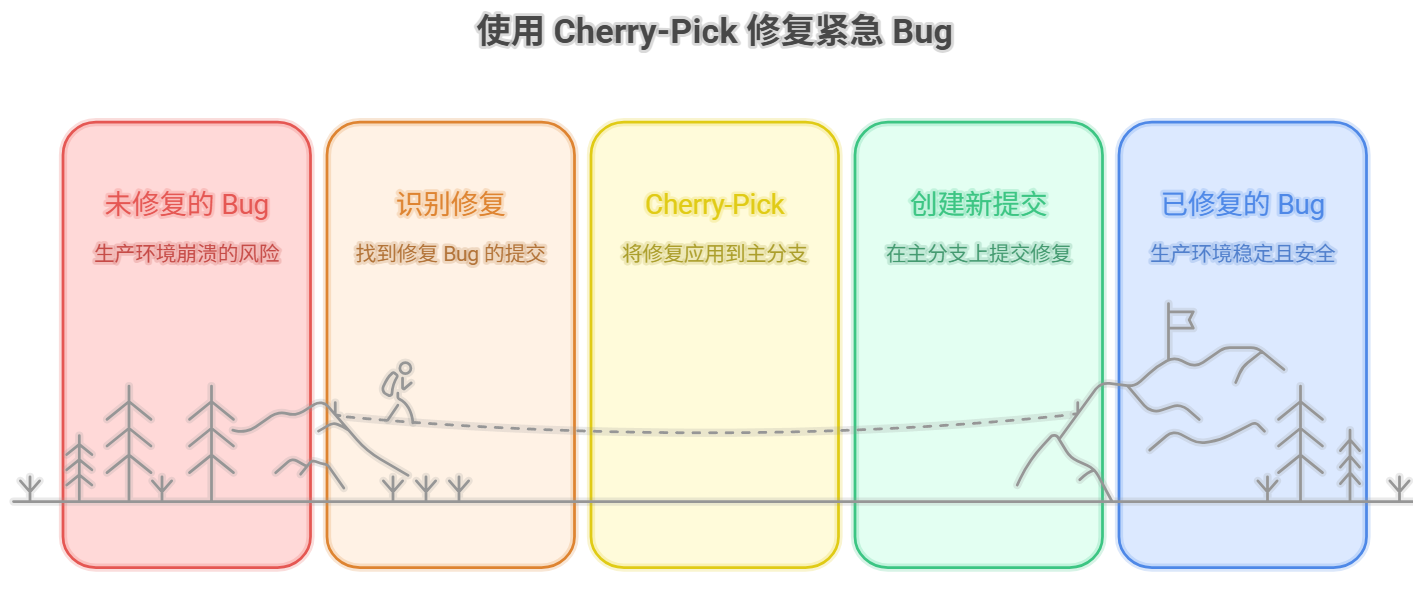
现在换个场景。你正在一个复杂的 feature/new-algorithm 分支上折腾,里面有10个提交。突然发现第3个提交(假设是 a1b2c3d)修复了个要命的Bug,生产环境马上就要崩了!
问题是,整个 feature 分支还没搞完,但这个Bug修复必须马上上线。咋办?
这时候 cherry-pick 就像个精准的外科手术刀,专门干这种活。
它的思路更直接:我不要你的分支,我就要你这一个提交,其他的别烦我。
具体操作:
你切到 master,然后 git cherry-pick a1b2c3d,Git就会:
- 找到那个
a1b2c3d提交 - 把它的代码改动"复制"一份,应用到当前的
master上 - 生成一个全新的提交,内容一样,但ID完全不同!
# 精准打击,专治急症
git checkout master
git pull origin master
# 从feature分支"偷"个提交过来
git cherry-pick a1b2c3d
git push origin master
cherry-pick 的优势:
- 灵活得不行:想要啥就拿啥,跨分支、跨时间,随便你
- 历史保持干净:不会产生合并提交,主线历史看着舒服
- 救急神器:热修复、关键改动同步,这就是它的主场
但坑也不少:
- 上下文丢了:提交脱离了原来的环境,可能会有依赖问题
- 重复提交的隐患:这个最坑!你cherry-pick了一个提交,后来又merge了整个分支,Git可能会懵逼,给你来个冲突
- 管理成本高:你得记住哪些提交被cherry-pick过,项目复杂了就是噩梦
一个真实的例子
前段时间我们项目就遇到过这种情况:
我在feature/payment分支开发支付功能,写了大概15个提交。突然测试发现生产环境有个计算金额的bug,而我在第8个提交里正好修复了这个问题。
这时候支付功能还没开发完,但这个bug必须马上修复。我就用了cherry-pick:
git checkout master
git cherry-pick 8a7b6c5 # 第8个提交的ID
git push origin master
这样就把bug修复快速上线了,而不用等整个支付功能开发完。
直观对比:一眼看懂谁是谁
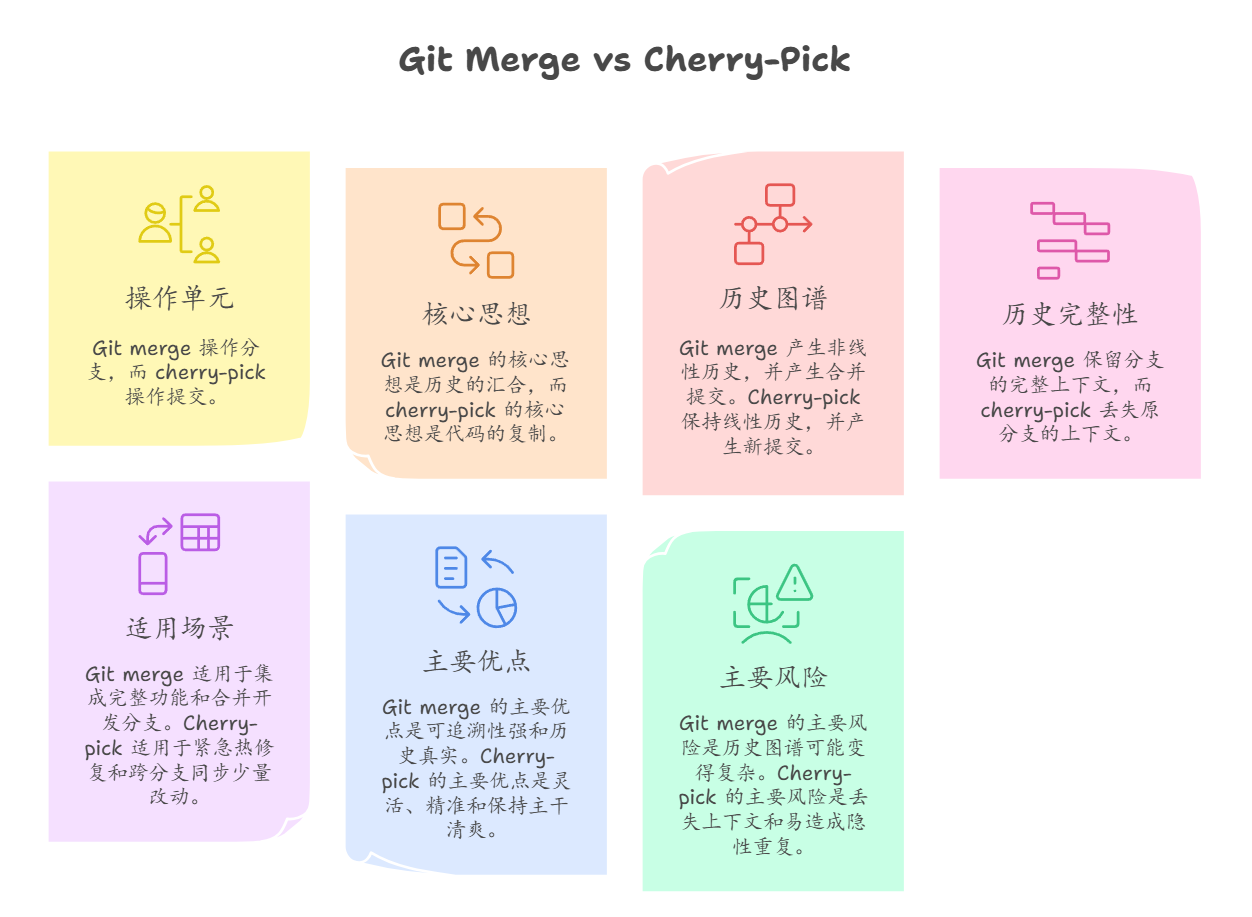
| 对比项 | git merge | git cherry-pick |
|---|---|---|
| 处理对象 | 整个分支 | 单个提交 |
| 核心思想 | 历史汇合 | 代码搬运 |
| 历史样子 | 有分叉,有合并节点 | 保持直线,新提交 |
| 历史完整性 | 完整保留分支上下文 | 会丢失原来的上下文 |
| 适合场景 | 合并完整功能 | 紧急修复、少量改动同步 |
| 主要优点 | 历史清楚,便于追溯 | 灵活精准,主线干净 |
| 主要坑点 | 历史可能变复杂 | 容易搞出重复提交 |
选择指南:到底用哪个?
看到这儿,你心里应该有数了。我总结了个简单粗暴的原则:
“功能用
merge,修复用cherry-pick”
什么时候用 merge:
- 功能分支开发完了,测试也过了,该合并到主线了
- 想让某个分支同步另一个分支的所有进展
- 团队重视开发历史的完整性,需要清楚的合并记录
什么时候用 cherry-pick:
- 从未完成的分支里拯救一个紧急Bug修复
- 需要把主线的某个提交同步到旧版本维护分支
- 看中了别人分支里的某个改动,但不想要整个分支
写在最后
说到底,merge 和 cherry-pick 就像螺丝刀和镊子,没有好坏之分,关键是用对地方:
Merge适合处理大块的、结构性的变化,关注的是历史的融合Cherry-pick适合处理细小的、精确的操作,关注的是代码的搬运
作为码农,理解这两个工具的本质和风险,能帮我们避开很多坑,让项目历史更健康,团队协作更顺畅。
希望今天的分享对你有用。下次遇到合并代码的时候,记得先想想:我到底是要合并功能,还是要迁移修复?答案就在那里。


















 3080
3080

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











