






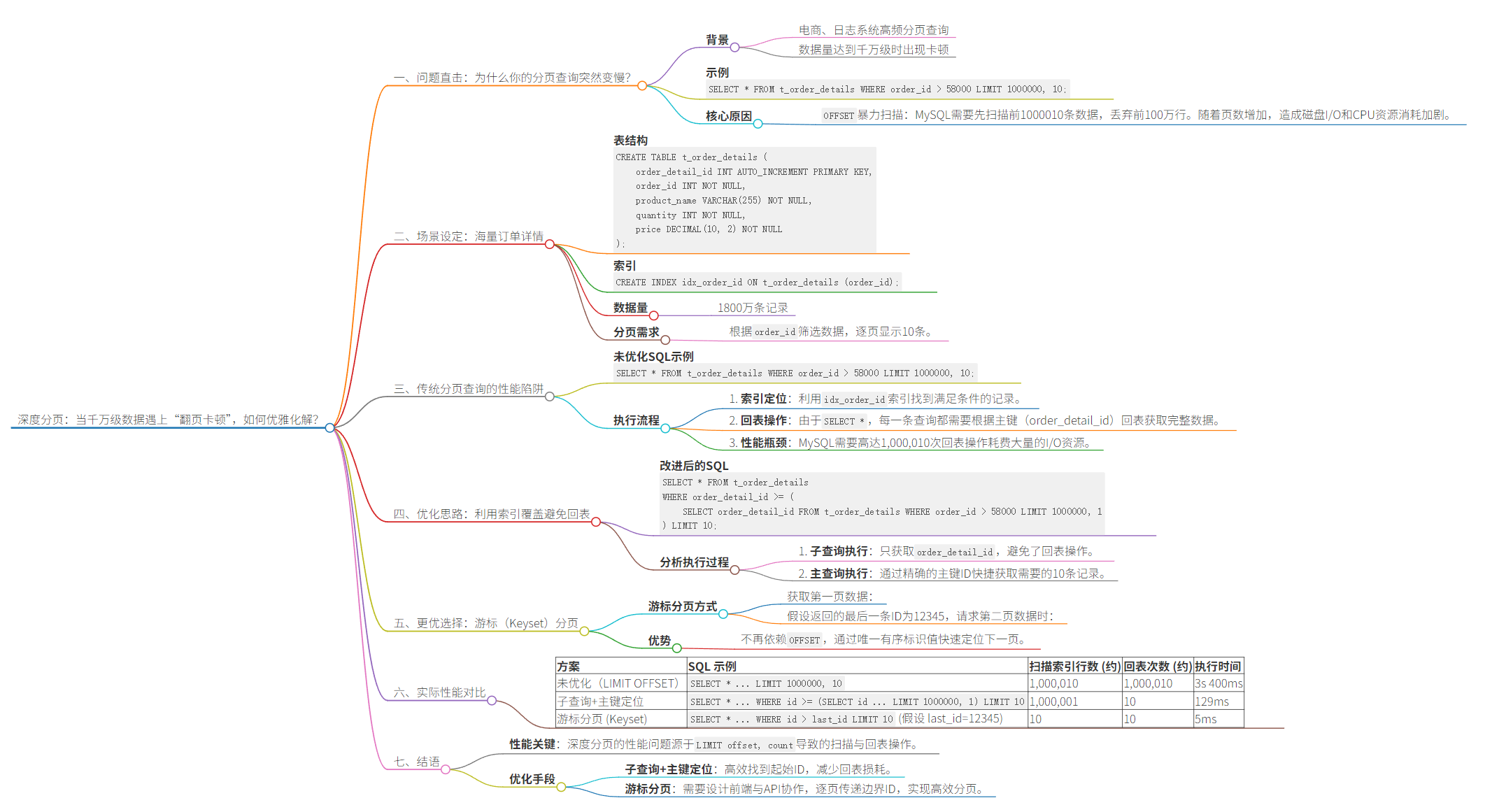
文章目录
文章导图
1、问题直击:为什么你的分页查询突然变慢?
在电商、日志系统等场景中,分页查询是高频操作。但当数据量达到千万级时,简单的LIMIT分页会突然“卡死”。例如,执行以下SQL时:
SELECT * FROM t_order_details WHERE order_id > 58000 LIMIT 1000000, 10;
这条看似普通的语句,随着页数增加(如第100万页),响应时间会呈指数级增长。核心原因在于OFFSET的“暴力扫描” :MySQL需要先扫描前1000010条数据,丢弃前100万行,再返回最后10条。当数据量达到千万级时,这种“全量扫描+丢弃”的模式会导致磁盘I/O和CPU资源被耗尽。
今天,我们就以一个具体的订单详情表 t_order_details 为例,探讨一下深度分页带来的问题以及如何进行有效的优化。
2、场景设定:海量订单详情
这个表结构如何生成千万数据可以参考我之前的文章:
互联网千万级别大数据量如何在本地模拟生成?采用MySQL存储过程轻松实现
互联网千万级别大数据量如何在本地模拟生成?采用MySQL存储过程轻松实现
互联网千万级别大数据量如何在本地模拟生成?采用MySQL存储过程轻松实现
我们有一个存储订单详情的表 t_order_details,结构如下:
CREATE TABLE t_order_details (
order_detail_id INT AUTO_INCREMENT PRIMARY KEY,
order_id INT NOT NULL,
product_name VARCHAR(255) NOT NULL,
quantity INT NOT NULL,
price DECIMAL(10, 2) NOT NULL
);
-- 为 order_id 创建索引,方便按订单ID查询
CREATE INDEX idx_order_id ON t_order_details (order_id);
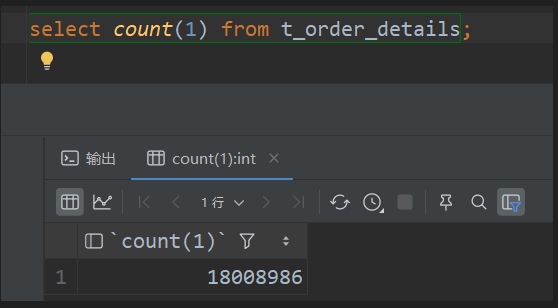
如图,这张表的数据量非常庞大,达到了1800万条。现在,我们需要根据 order_id 进行筛选,并进行分页展示,每页显示10条数据。
3、传统分页查询的性能陷阱:昂贵的“回表”代价
面对这个需求,我们可能会直接写出这样的SQL:
-- 未优化SQL:查询 order_id > 58000 的数据,从第 1,000,001 条开始取 10 条
SELECT *
FROM t_order_details
WHERE order_id > 58000
LIMIT 1000000, 10;
这条SQL在逻辑上简单明了,但在大数据量下其执行效率却令人担忧。MySQL处理 LIMIT offset, count 时的大致流程是:
- 索引定位:利用
idx_order_id索引找到order_id > 58000的记录。 - 扫描与数据获取:MySQL需要定位到满足条件的第
offset + 1(1,000,001) 条记录,这意味着它必须扫描过前面的offset(1,000,000) 条记录。 - 关键瓶颈 - 回表:由于我们使用的是
SELECT *,查询需要获取所有列的数据。而idx_order_id这个二级索引通常只包含索引列 (order_id) 和主键列 (order_detail_id)。因此,对于通过idx_order_id找到的每一条满足条件的记录(理论上是前 1,000,010 条),MySQL都需要拿着主键order_detail_id再次访问主键索引(聚簇索引)去查找并获取完整的行数据。这个根据二级索引中的主键值去主键索引中查找完整数据的过程,就叫做“回表”。在这个例子中,可能触发高达 1,000,010 次回表操作! - 数据丢弃:在获取了 1,000,010 条完整的行数据后,MySQL 将前 1,000,000 条丢弃,只返回最后 10 条。
可以看到,大量的回表操作带来了巨大的随机 I/O 开销,同时获取并丢弃海量完整行数据也消耗了大量的内存和 CPU 资源。这正是传统深度分页性能低下的核心原因。
4、优化思路:利用索引覆盖避免回表
优化的关键在于避免对被跳过的大量数据进行回表操作。既然回表的起因是二级索引无法满足 SELECT * 的需求,那我们是否可以先只通过索引确定目标页起始行的主键ID,再用这个ID去精确获取所需的10行完整数据呢?
改进后的SQL如下:
-- 优化后的SQL
SELECT *
FROM t_order_details
WHERE order_detail_id >= (
-- 子查询:仅通过索引找到目标页第一条记录的 ID
SELECT order_detail_id
FROM t_order_details
WHERE order_id > 58000
LIMIT 1000000, 1 -- 注意这里是 LIMIT 1
)
LIMIT 10; -- 基于ID高效获取所需的10条记录
分析这条优化SQL的执行过程:
- 子查询执行:
SELECT order_detail_id FROM t_order_details WHERE order_id > 58000 LIMIT 1000000, 1- 该子查询的目标是找到满足
order_id > 58000条件的第 1,000,001 条记录的order_detail_id。 - 它依然需要扫描
idx_order_id索引来定位满足条件的记录,并跳过前 1,000,000 条。注意:扫描索引本身的成本依然存在。 - 核心优化点:子查询只请求
order_detail_id列。由于idx_order_id索引的叶子节点已经包含了order_id和主键order_detail_id,MySQL 可以仅通过扫描idx_order_id索引就完成这个子查询,获取到所需的order_detail_id值。这个过程称为索引覆盖(Index Coverage)。它成功避免了对那被跳过的 1,000,000 条记录进行回表操作,极大地减少了 I/O 和数据处理量。处理轻量的索引条目远比处理完整的行数据高效。
- 该子查询的目标是找到满足
- 主查询执行:
SELECT * FROM t_order_details WHERE order_detail_id >= [子查询返回的ID] LIMIT 10- 子查询返回了一个具体的
order_detail_id(假设为X)。 - 主查询变为
SELECT * FROM t_order_details WHERE order_detail_id >= X LIMIT 10。 - 这个查询条件直接作用于主键索引。MySQL 可以利用主键索引(通常是 B+ 树)进行非常高效的范围查找,快速定位到
order_detail_id为X(或之后的第一条) 的记录。 - 从定位到的位置开始,顺序读取 10 条完整的记录即可。这里只需要对最终返回的 10 条数据进行完整读取(可能涉及少量回表,或者如果缓冲命中则更快),相比之前的百万次回表,开销几乎可以忽略不计。
- 子查询返回了一个具体的
通过这种方式,我们将原本“扫描索引 -> 百万次回表获取完整数据 -> 丢弃大量数据”的重量级操作,转变成了“扫描索引(无回表)获取单个ID -> 基于主键ID高效定位 -> 获取10条完整数据”的相对轻量级操作。性能提升的关键就在于子查询利用索引覆盖避免了海量的回表操作。
5、更优选择:游标(Keyset)分页
虽然优化后的SQL性能提升显著,但内层子查询仍需扫描100万行才能定位锚点。更优方案是完全抛弃OFFSET,改用“游标分页” :此方法不再依赖 offset,而是要求客户端传递上一页最后一条记录的唯一且有序的标识(通常是主键 ID)。
例如,获取第一页数据:
SELECT * FROM t_order_details WHERE order_id > 58000 ORDER BY order_detail_id ASC LIMIT 10;
假设返回的最后一条记录 order_detail_id 是 12345。
那么,请求第二页数据时,客户端需要传入这个 12345,SQL 就变成:
SELECT * FROM t_order_details WHERE order_id > 58000 AND order_detail_id > 1000000 ORDER BY order_detail_id ASC LIMIT 10;
这种方式利用 order_detail_id > last_seen_id 条件,每次都能通过索引快速定位到下一页的起始位置,无论查询多少页,性能都非常稳定高效。当然,这种方法需要前端或API接口设计上的配合,不再是简单的传递页码和每页数量。
6、实际性能对比
以 我这张实际1800 万订单表为例(主键 order_detail_id,筛选条件 order_id > 58000,查询第 100,001 页,即 offset = 1,000,000):
| 方案 | SQL 示例 | 扫描索引行数 (约) | 回表次数 (约) | 执行时间 |
|---|---|---|---|---|
| 未优化 (LIMIT OFFSET) | SELECT * ... LIMIT 1000000, 10 | 1,000,010 | 1,000,010 | 3s 400ms |
| 子查询+主键定位 | SELECT * ... WHERE id >= (SELECT id ... LIMIT 1000000, 1) LIMIT 10 | 1,000,001 | 10 | 129ms |
| 游标分页 (Keyset) | SELECT * ... WHERE id > last_id LIMIT 10 (假设 last_id=1,000,000) | 10 | 10 | 5ms |
未优化
select * from t_order_details where order_id > 58000 limit 1000000, 10;

子查询+主键定位
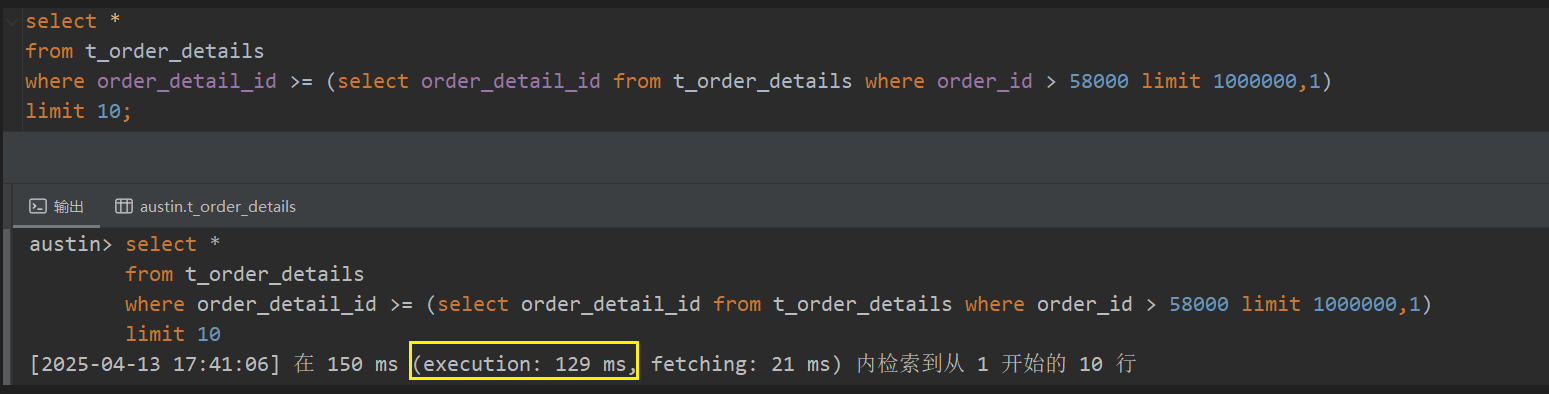
select *
from t_order_details
where order_detail_id >= (select order_detail_id from t_order_details where order_id > 58000 limit 1000000,1)
limit 10;
游标分页
SELECT *
FROM t_order_details
WHERE order_id > 58000
AND order_detail_id > 1000000
ORDER BY order_detail_id ASC
LIMIT 10;

7、结语
MySQL 的深度分页性能问题,根源往往在于 LIMIT offset, count 导致的大量数据扫描和回表操作。理解了“回表”的代价,我们就能更有针对性地进行优化。
- 子查询+主键定位:通过子查询利用索引覆盖找到起始ID,避免了对跳过数据的大量回表,是有效的优化手段。
- 游标分页:是更彻底、性能更优的方案,通过传递上一页的边界ID实现高效分页,值得在项目中优先考虑。


















 2174
2174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











