




文章目录

文章 导图

引子:一个反直觉的SQL优化案例
关于本篇文章中的表结构和数据量,互联网千万级别大数据量如何在本地模拟生成?采用MySQL存储过程轻松实现,后续写的文章都会基于这个表结构和数据量进行实践
最近在进行项目数据库优化时,我遇到了一个很有趣的现象。在一个订单详情表(order_details)上,当我给查询语句加上索引条件时,查询速度反而变慢了。具体来说,我有如下表结构:
create table order_details
(
order_detail_id int auto_increment
primary key,
order_id int not null,
product_name varchar(255) not null,
quantity int not null,
price decimal(10, 2) not null
);
create index idx_order_id
on order_details (order_id);
这个表数据量有1800万!

当我执行如下两个查询时,发现了这个奇怪的现象,然后我比较了以下两条SQL语句的执行时间:
-- 使用索引条件的查询
select * from order_details where order_id>50000 limit 1500000, 1
-- 不使用索引条件的查询
select * from order_details limit 1500000, 1
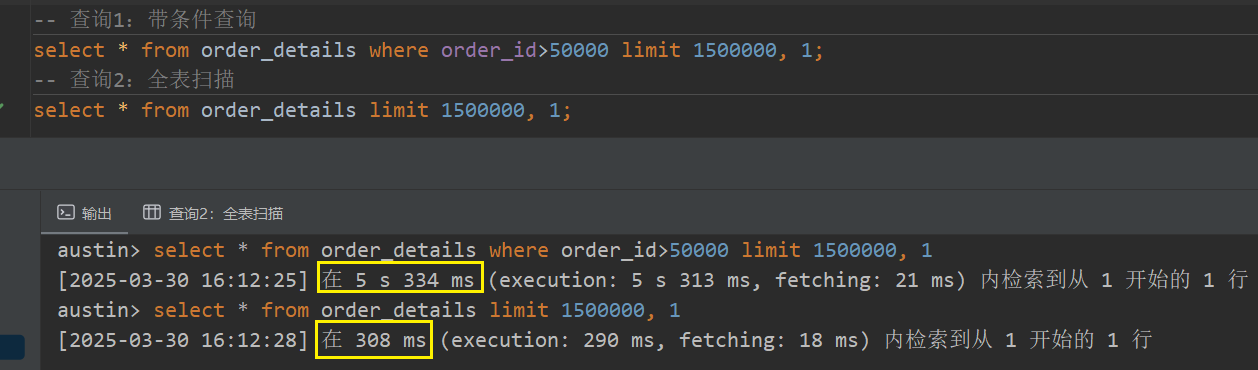
令我惊讶的是,第一条使用了索引条件的SQL语句执行速度竟然比不使用索引条件的慢!这与我们常识中"索引能提升查询效率"的认知似乎相悖。明明在order_id字段建立了索引,为什么带条件的查询反而更慢?
这个结果完全颠覆了我们对索引的常规认知。为什么明明使用了索引,查询性能反而更差呢?这需要我们从MySQL的查询执行机制说起。

深入分析
1. 高偏移量的LIMIT操作
这个问题的核心在于我们查询中的LIMIT 1500000, 1。这表示我们想要跳过前1500000条记录,只返回第1500001条记录。MySQL在处理这种高偏移量的LIMIT操作时,无论是否使用索引,都必须先定位到第1500000条记录才能返回结果。
2. 索引扫描与全表扫描的对比
当我们不加任何条件时,MySQL会直接进行主键的顺序扫描,这是最快的方式:
- 直接按照主键顺序读取数据
- 跳过1500000条记录
- 返回第1500001条
但当我们加上where order_id>50000时,MySQL会这样处理:
- 使用二级索引idx_order_id查找满足order_id>50000的记录
- 对这些记录进行排序(按照索引顺序)
- 跳过1500000条记录
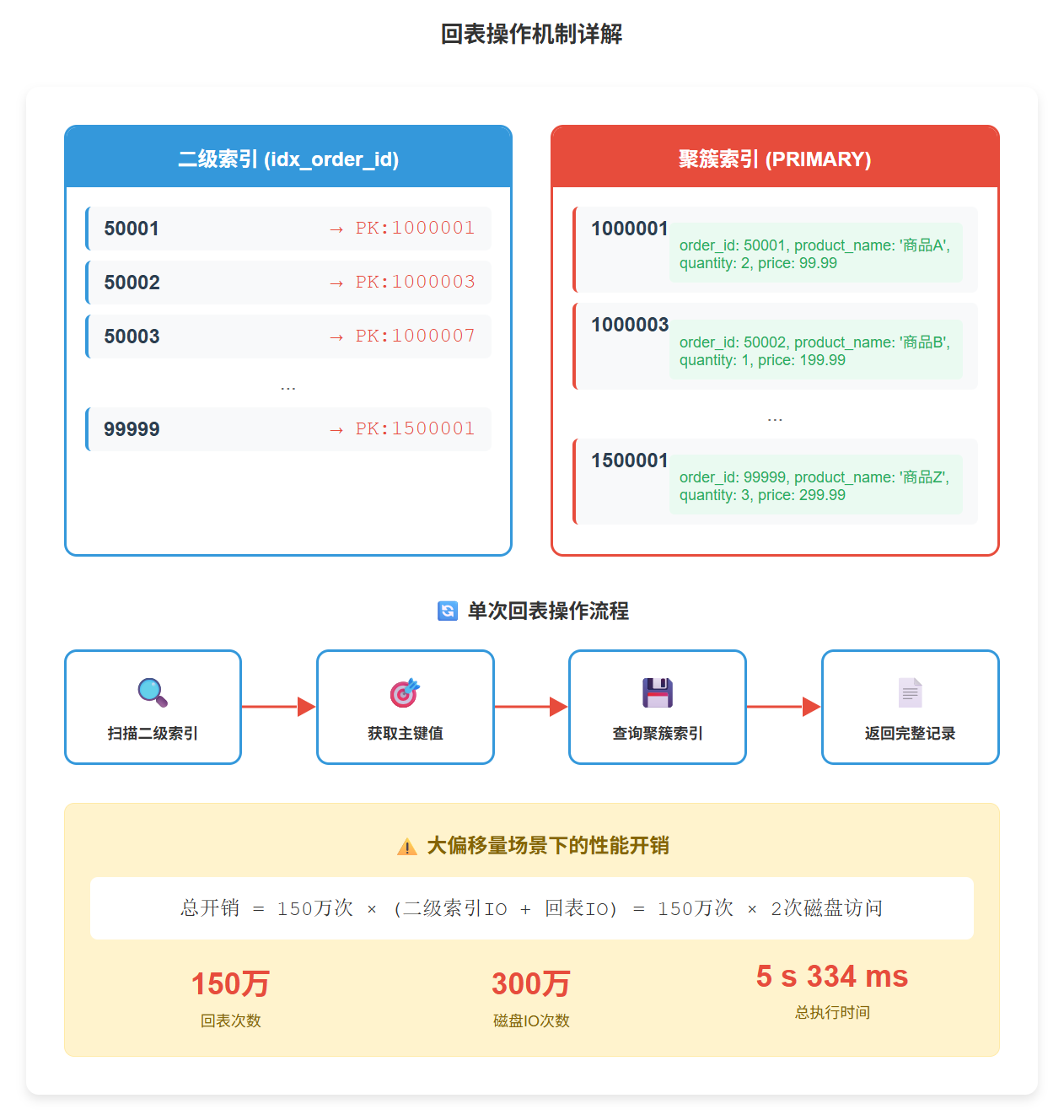
- *然后回表查询完整的记录信息(因为select 需要所有字段)
这个过程中,"回表"操作是非常耗时的,特别是当需要回表1500000次时。

3. 回表操作的开销
当使用二级索引进行查询,且需要获取索引中未包含的字段时,MySQL需要进行回表操作:通过二级索引找到主键值,再通过主键值查询完整记录。当LIMIT偏移量很大时,这种回表操作的累积成本极高。
为什么会这样?explain执行计划揭示真相
如果我们使用EXPLAIN分析这两条SQL,会发现extra出现了 Using index condition; Using MRR ,这说明MySQL优化器同时启用了索引条件下推(ICP) 和多范围读(MRR) 两种优化策略。
- 带索引语句执行explain:

- 不带索引语句执行explain:


1. 索引条件下推(Index Condition Pushdown, ICP)
- 现象 :
Using index condition表示启用了ICP优化。 - 原理 :
传统索引扫描需要先通过索引定位到主键,再回表获取完整行数据,最后在Server层过滤非索引字段。而ICP允许将WHERE条件中涉及非索引列的过滤下推到存储引擎层 ,减少回表次数。 - 本案例中的作用 :
虽然查询条件order_id>50000完全基于索引列,但ICP仍可能对后续的回表操作进行优化。例如,若查询涉及其他非索引字段(如product_name),ICP会提前过滤掉不满足条件的索引条目,减少随机IO次数。
2. 多范围读(Multi-Range Read, MRR)
- 现象 :
Using MRR表示启用了MRR优化。 - 原理 :
MRR通过将随机IO转换为顺序IO 提升性能。对于范围查询,MRR会先收集所有满足条件的主键值,将其排序后批量回表 ,而非逐条随机访问。 - 本案例中的作用 :
对于order_id>500的范围查询,MRR会先收集所有符合条件的主键值,按主键顺序排序后再批量回表读取数据。这减少了磁盘寻道时间,尤其在机械硬盘场景下效果显著。
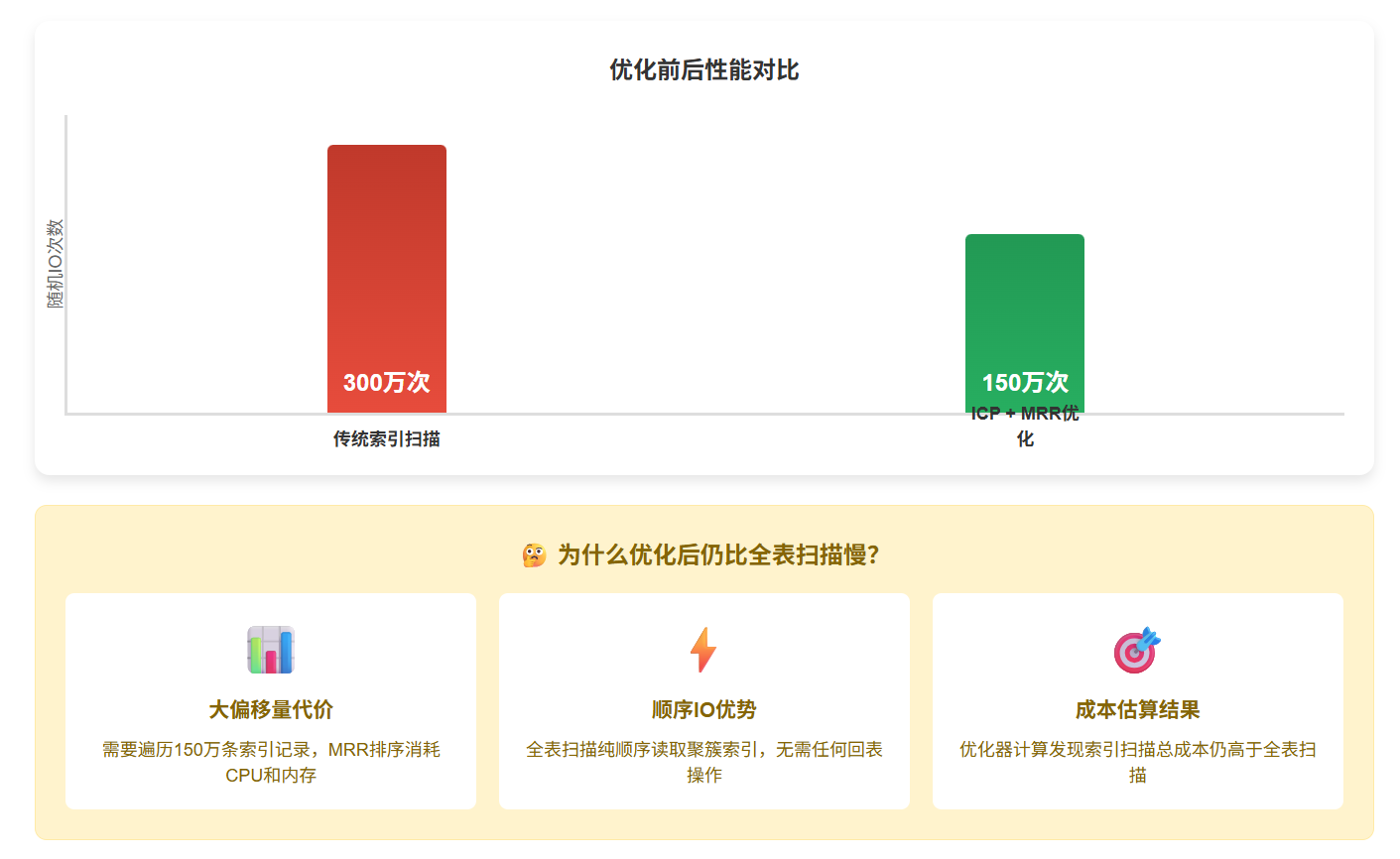
3. 为什么优化后仍比全表扫描慢?
尽管启用了ICP和MRR,但在 LIMIT 1500000,1 的场景下,性能问题依然存在:
- 大偏移量的代价 :
- 索引扫描需要遍历到第1,500,001个符合条件的索引条目,若
order_id>50000的数据分布稀疏,可能需要扫描更多索引节点。 - MRR的排序和批量回表操作会消耗额外CPU和内存资源
- 索引扫描需要遍历到第1,500,001个符合条件的索引条目,若
- 全表扫描的天然优势 :
- 全表扫描
type=ALL直接顺序读取聚簇索引,无需回表操作 - MySQL优化器通过预估行数发现,全表扫描的顺序IO成本低于索引扫描的随机IO总和 ,因此即使有MRR优化,仍可能选择全表扫描
- 全表扫描
深度原理:成本估算模型
MySQL优化器通过成本估算选择执行计划:
总成本 = IO成本 + CPU成本
对于我们的案例:
- 索引扫描成本 = 索引IO成本 + 回表IO成本 + 数据过滤CPU成本
- 全表扫描成本 = 全表IO成本 + 数据过滤CPU成本
当索引扫描成本 > 全表扫描成本时,就会出现使用索引反而更慢的情况。可以通过以下公式估算:
索引扫描成本 = (索引记录数 / 每页索引条目数) * 单页IO成本
+ 记录数 * 回表单次IO成本
+ 记录数 * CPU检查成本
全表扫描成本 = (数据页总数 * 单页IO成本)
+ 记录数 * CPU检查成本
思考延伸:什么时候索引会降低性能?

- 低选择性查询:当条件过滤超过70%数据时
- 大偏移分页查询:偏移量超过总数据量的10%时
- 宽表查询:需要SELECT *且无覆盖索引时
- 高碎片化索引:索引页分散度超过50%时
- 统计信息过期:导致优化器误判执行计划
通过这个案例分析,我们可以深刻理解:索引不是银弹,合适的才是最好的。在实际开发中,一定要结合EXPLAIN执行计划和真实数据特征进行验证!
TODO:
后续我会在这个大数据量的基础上分析,MySQL的深度分页方案、索引优化方案。。。请持续关注!


















 461
461

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











