




 该方法描述了一种在有标签数据不可用时处理新类发现的技术。首先,使用有标签数据训练ResNet-18网络,然后保存特征表示的原型和方差。接着,在无标签数据上,通过结合伪标签、自我监督损失和均方误差损失来学习新类。为了防止遗忘,利用特征回放和知识蒸馏损失来保持对已知类别的识别能力。整个过程旨在在不断出现新类的情况下,持续地学习和适应。
该方法描述了一种在有标签数据不可用时处理新类发现的技术。首先,使用有标签数据训练ResNet-18网络,然后保存特征表示的原型和方差。接着,在无标签数据上,通过结合伪标签、自我监督损失和均方误差损失来学习新类。为了防止遗忘,利用特征回放和知识蒸馏损失来保持对已知类别的识别能力。整个过程旨在在不断出现新类的情况下,持续地学习和适应。
一、简介
题目: Class-Incremental Novel Class Discovery
会议: ECCV 2022
任务: 最初,有一个有标签的数据集(其数据均属已知类),出于隐私保护,使用该数据集训练过模型后,数据会被变得不可获取,之后会有一个无标签的数据集(其数据均属于新类/未知类,与已知类不相交),要求模型保留对已知类的分类能力同时对无标签样本进行聚类,或称新类发现(Novel Category Discovery)。这样该无标签数据集就有了标签,训练模型后又变得不可获取,再对另一个无标签数据集进行新类发现,如此往复。
Note: 确定类别数量对神经网络的搭建来说是极其重要的,该方法没有提供评估类别数量的方法,有理由认为作者假设新类数据的类别数是已知的。
方法:
(1)建立网络学习有标签数据。以ResNet-18为backbone,加一个有监督的分类头(大小等于已知类数量)搭建一个神经网络,以交叉熵为损失在有标签数据集上进行网络训练。保留训练后的模型并对每个类计算由backbone提取出的特征的均值(文中称为原型)和方差。
(2)建立网络准备学习无标签数据。同样以ResNet-18为backbone,新建一个网络,加两个分类头(一个分类头大小=已知类数量+新类数量,另一个分类头大小=新类数量)。已知类部分网络权重由(1)中模型参数初始化。
(3)学习无标签数据并减少对已学信息的遗忘(此时有标签数据不可获取)。为保证对新类的学习效率,作者将 L b c e + w self ( t ) L self + w self ( t ) L mse \mathcal L_{bce}+w_{\text{self}}(t)\mathcal L_{\text{self}}+w_{\text{self}}(t)\mathcal L_{\text{mse}} Lbce+wself(t)Lself+wself(t)Lmse作为损失函数的一部分,为保留模型对已知类的识别能力(减少遗忘),作者将 L r e p l a y + λ L KD feat \mathcal L_{replay}+\lambda\mathcal L_{\text{KD}}^{\text{feat}} Lreplay+λLKDfeat作为损失的另一部分。
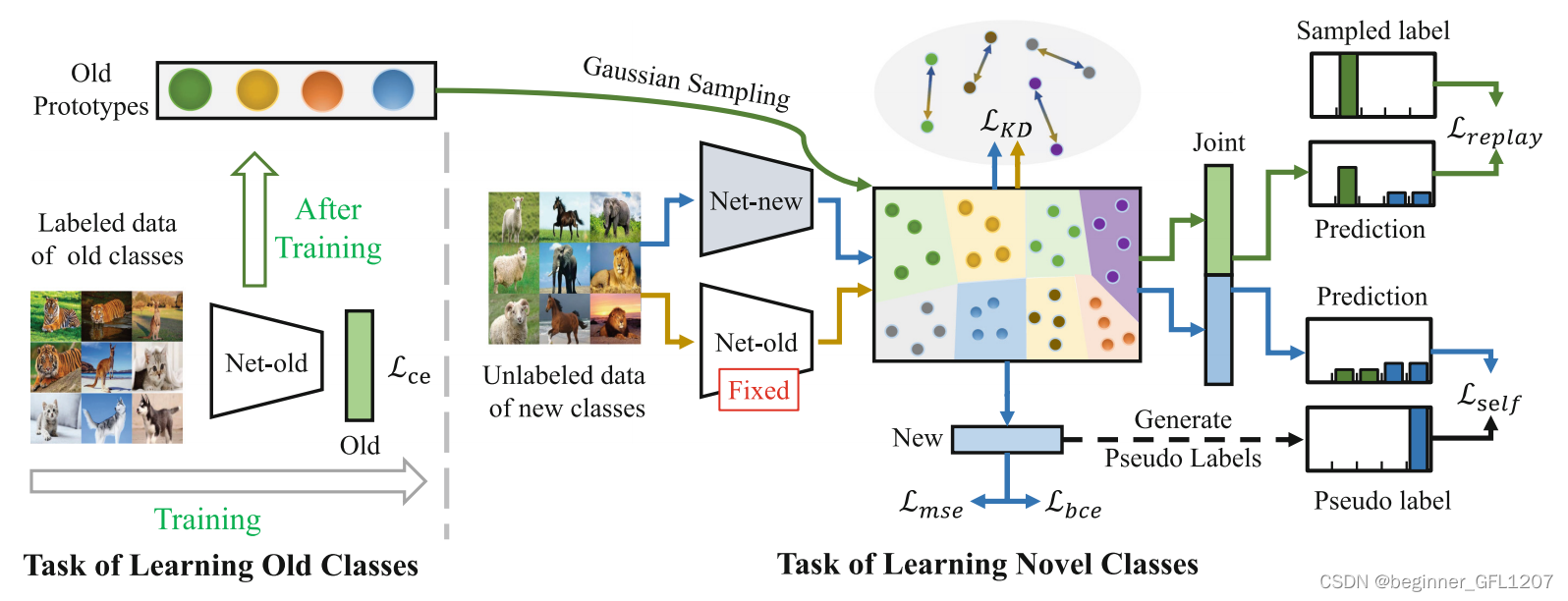
该方法结构图,如上所示。
二、详情
1. 学习有标签数据
最初,有提供了标签的已知类数据集 D [ L ] \mathcal D^{[\text L]} D[L]。此时任务为常规分类任务,记作 T [ L ] \mathcal T^{[\text L]} T[L]。
A. 有监督训练
最常见的有监督分类训练任务。以ResNet-18为backbone,加一个有监督的分类头(大小等于已知类数量)搭建一个神经网络,以交叉熵为损失函数:
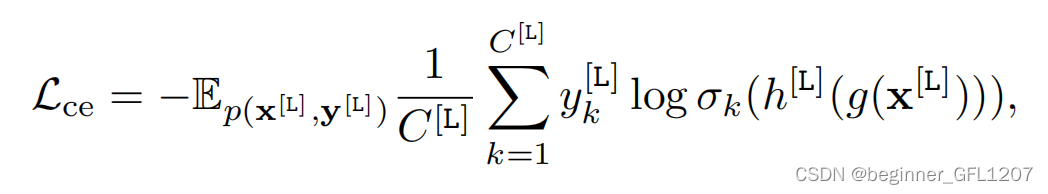
其中, x [ L ] \textbf x^{[\text L]} x[L]和 y [ L ] \textbf y^{[\text L]} y[L]为有标签样本和对应的真实标签, C [ L ] C^{[\text L]} C[L]为已知类类别数量, σ k ( ∗ ) \sigma_k(*) σk(∗)为softmax函数, g ( ∗ ) g(*) g(∗)和 h ( ∗ ) h(*) h(∗)分别特征提取器(backbone)和分类头。训练后的特征提取器(记作 g [ L ] ( ∗ ) g^{[\text L]}(*) g[L](∗))会被保存用于之后的增量学习。
显然, L ce \mathcal L_{\text{ce}} Lce的作用是将属于同一个已知类的数据放到一起。
B. 保留原型和特征方差
在模型训练之后,在数据不可获取之前,需要保留原型和特征方差用于后续训练,以减少在当前任务中学习的知识的遗忘。
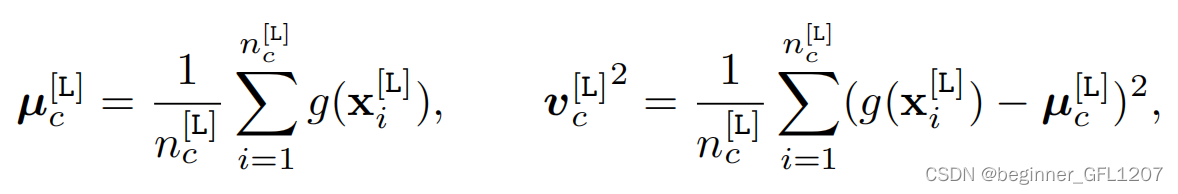
其中, μ c [ L ] \pmb\mu_c^{[\text L]} μc[L]为原型(作者用的是均值), v c [ L ] 2 {\pmb v_c^{[\text L]^2}} vc[L]2为方差。各类别的 μ c [ L ] \pmb\mu_c^{[\text L]} μ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 743
743

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











