






 本文介绍了一种名为Co-Attentive Multi-Task Learning for Explainable Recommendation的模型,该模型通过利用推荐和解释任务之间的相关性,提高了推荐系统的准确性和可解释性。模型采用编码-选择-解码的三段式结构,使用层级的互注意力选择器来识别重要评论和概念,从而提升推荐预测的准确率并生成有用的个性化推荐解释。
本文介绍了一种名为Co-Attentive Multi-Task Learning for Explainable Recommendation的模型,该模型通过利用推荐和解释任务之间的相关性,提高了推荐系统的准确性和可解释性。模型采用编码-选择-解码的三段式结构,使用层级的互注意力选择器来识别重要评论和概念,从而提升推荐预测的准确率并生成有用的个性化推荐解释。
Co-Attentive Multi-Task Learning for Explainable Recommendation
官方代码:Source code: https://github.com/3878anonymous/CAML
文章摘要:
提供推荐的解释可增强用户的信任和可解释性,本篇文章提出互注意力可解释性推荐模型,利用推荐和解释任务之间的相关性提升两者的性能,具体作者仿照人类处理信息的方式涉及了编码选择解码三段式结构,在选择阶段使用的层级的互注意力选择器有效的建模两个任务的跨知识迁移,实验证明模型不仅提升了推荐预测的准确率同时可以生成流畅有用个性化的推荐解释
传统多任务的缺点:
多任务:共享user item embedding 的时候并不能达到很好的解释效果(不能包含物品特定的信息)
造成该结果有两个原因:1)共享的表示不可解释就很难提供对于解释任务的显示限制
2)用户物品的embedding不能包含充分的深度用户-物品交互信息
本篇文章作者在选择器利用互注意力选择重要的评论和概念用于解释任务,使用了用户-物品的交互信息
该文章的模型整体结构:(三段式 编码-选择-解码)
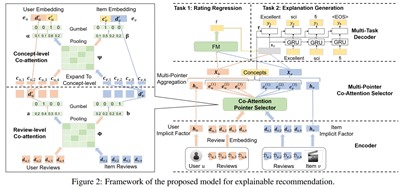](https://i-blog.csdnimg.cn/blog_migrate/8f6f7d5e19607916d33ab738f6992011.png#pic_center)
编码器评论信息、词、隐因子(用户、物品的隐因子向量表示)的embedding表示
选择器使用层级的多指针互注意力(每次选择一个最重要的评论/概念,运行多次)识别对于用户和物品来说重要的评论和概念,识别的重要概念为两个任务之间的跨知识,
多任务解码器根据选择器抽取的重要概念预测评分同时生成推荐的解释,其中:
评分预测任务:
在这一层用户和物品的表示是选择器得到的表示和对应隐因子表示的拼接
使用FM进行评分预测,MSE作为评分预测任务的损失函数


解释生成任务:



将用户、物品、评分(3.14->3 onehot向量表示)的向量表示送入GRU中,ot表示t时刻的输出结果表示词的概率分布,在测试时使用束搜索找到最好的解释 Yt是t时刻的词
概念级别的损失:

最大化概念词被选择的概率,tao 表示被选择的概念向量
负对数似然损失:

保证生成词与真实词相似,yt*表示时间t的真实词
联合训练:
不同类型损失函数的线性结合以端到端的方式联合学习两个任务

通过消融实验验证多任务的有效性:

代码部分笔者主要关注多任务中损失函数结合和正则化部分
其中源码中的生成部分多任务默认的lamda=1 在评分任务中并未添加正则化系数
对于L2参数的正则化部分笔者认为很有参考价值写的很精简
with tf.name_scope("cost_function"):
if("SOFT" in self.args.rnn_type):
target = self.soft_labels
if('POINT' in self.args.rnn_type):
target = tf.argmax(target, 1)
target = tf.expand_dims(target, 1)
target = tf.cast(target, tf.float32)
ce = tf.nn.sigmoid_cross_entropy_with_logits(
logits=self.output_pos,
labels=target)
else:
ce = tf.nn.softmax_cross_entropy_with_logits_v2(
logits=self.output_pos,
labels=tf.stop_gradient(target))
self.cost = tf.reduce_mean(ce) #交叉熵损失函数
elif('RAW_MSE' in self.args.rnn_type):
sig = self.output_pos
target = tf.expand_dims(self.sig_labels, 1)
self.cost = tf.reduce_mean(tf.square(tf.subtract(target, sig))) #MSE损失
elif('LOG' in self.args.rnn_type):
# BPR loss for ranking
self.cost = tf.reduce_mean(
-tf.log(tf.nn.sigmoid(
self.output_pos-self.output_neg)))
else:
# Hinge loss for ranking
self.hinge_loss = tf.maximum(0.0,(
self.args.margin - self.output_pos \
+ self.output_neg))
self.cost = tf.reduce_sum(self.hinge_loss)
#self.cost = self.cost * self.args.rating_lambda
#with tf.name_scope('regularization'):
# if(self.args.l2_reg>0):
# vars = tf.trainable_variables()
# lossL2 = tf.add_n([tf.nn.l2_loss(v) for v in vars \
# if 'bias' not in v.name ])
# lossL2 *= self.args.l2_reg
# self.cost += lossL2
if self.args.feed_rating == 0:
r_input = None
elif self.args.feed_rating == 1:
#move from [1 ,5] -> [0, 4]
r_input = tf.cast(self.sig_labels, dtype=tf.int32) - 1
else:
r_input = tf.clip_by_value(tf.cast(tf.reshape(self.output_pos, [-1]), dtype=tf.int32), 1, 5) - 1
with tf.name_scope('generation_results'):
self.gen_results = self._beam_search_infer(q1_output, q2_output, r_input)
with tf.name_scope('generation_loss'):
#self.gen_loss, self.gen_acc = self._gen_review(q1_output, q2_output)
self.gen_loss, self.gen_acc, self.key_word_loss = self._gen_review(q1_output, q2_output, r_input)
if self.args.word_gumbel == 1:
if (self.args.key_word_lambda != 0.0) and (self.args.concept == 1):
self.gen_loss += self.args.key_word_lambda * self.key_word_loss
self.cost += self.args.gen_lambda * self.gen_loss
self.task_cost = self.cost
with tf.name_scope('regularization'):
if(self.args.l2_reg>0):
vars = tf.trainable_variables() #返回所有可训练的参数
lossL2 = tf.add_n([tf.nn.l2_loss(v) for v in vars \
if 'bias' not in v.name ]) #一般不正则化参数项
#tf.add_n([p1, p2, p3....])函数是实现一个列表的元素的相加。列表里的元素可以是向量,矩阵,等
lossL2 *= self.args.l2_reg #default=1E-6
self.cost += lossL2
tf.summary.scalar("cost_function", self.cost)
另:
Tensorflow中的变量查看问题
Tf.trainable_variables() 返回的是所有参加训练的参数(权重,偏置等)
Tf.all_variables() 返回的是所有参数(包括可训练的参数(权重、偏置等)和不可训练的参数(学习率等)
Tf.global_variables() 返回的结果同tf.all_variables() 区别在于tf的版本
问:
看文章源代码对于联合训练的损失函数不同损失的系数设置的均为定值,因为看的代码数量有限,不知道这种是不是常见的做法,还是说可能会设置为一个变量让模型自己去优化?目前还未看到过这种做法,还请看到该问题的小伙伴们多多指教,在此先谢谢大家啦~

















 1071
1071

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









