




 本文分享了作者在非结构化数据处理项目中,利用Python进行自然语言处理的学习过程。从Anaconda安装到Nltk库的使用,详细记录了如何解决代码错误,包括数据文件的正确放置位置,以及如何使用Nltk进行文本分析,如搜索特定词汇、绘制词频分布图等。
本文分享了作者在非结构化数据处理项目中,利用Python进行自然语言处理的学习过程。从Anaconda安装到Nltk库的使用,详细记录了如何解决代码错误,包括数据文件的正确放置位置,以及如何使用Nltk进行文本分析,如搜索特定词汇、绘制词频分布图等。
前言
最近在做的一个项目,非结构化数据处理,然后从自然语言处理入手,开始学习一下如果使用python进行自然语言的处理
参考资料:https://github.com/wnma3mz/Nltk_Study
https://wnma3mz.github.io/hexo_blog/2018/05/13/《Python自然语言处理》阅读笔记(一)/
首先下载了anaconda,然后按照说明下载了数据文件
这个数据文件,一开始并不知道要拷到哪里去,但是尝试了输入了
import nltk
from nltk.book import *
之后,发现了报错
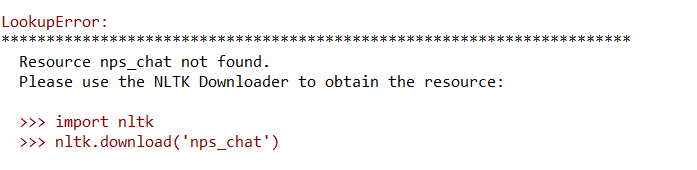 然后我在download之后顺其根源发现了需要拷贝的地址
然后我在download之后顺其根源发现了需要拷贝的地址

这样以后,找到了需要拷贝的目录,将数据文件复制进去,这样就可以运行我需要的操作了~
然后再运行以上代码
# 导入nltk模块
import nltk
# 导入基本语料集(不需要额外下载),包含text1到text9变量,可以直接输出这些变量
from nltk.book import *
# 搜索文本。这里表示找到"monstrous"所包含的句子,并且输出上下文
text1.concordance("monstrous")
# 搜索文本出现在相似的上下文中
text1.similar("monstrous")
# 搜索两个及两个以上共同词的上下文
text2.common_contexts(["monstrous", "very"])
# 画一张离散图表示这些词出现在文本中的位置,输出见下图
text4.dispersion_plot(["citizens", "democracy", "freedom", "duties", "America"])
# 基于文本,随机生成一些文本
text3.generate()
最后一句话 又遇到了报错
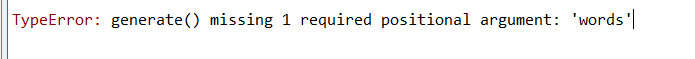
看上去是缺少参数
于是我在括号里面添加参数,没有任何变化…
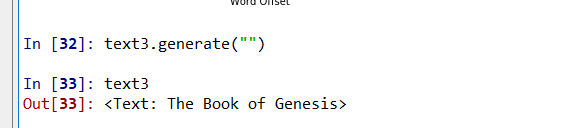
并不知道发生了什么。。。。愣住。。。。
接下来继续分析text
# 有序字典,按词频从高到低排序
fdist1 = FreqDist(text1)
# 选出词频最高的50个词
fdist1.keys()[:50]
# 某个词出现的频数
fdist1['whale']
# text1中词频最高的50个单词,进行绘图,输出见下图
fdist1.plot(50, cumulative=True)
# text1中只出现过一次的单词
fdist1.hapaxes()
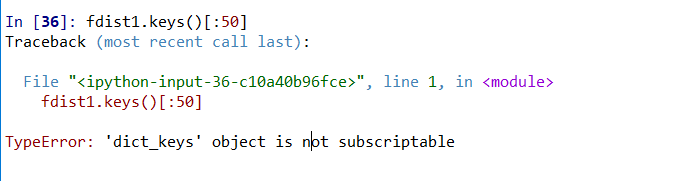
然后其实只要修改添加一个list就行了
list(fdist1.keys())[:50]
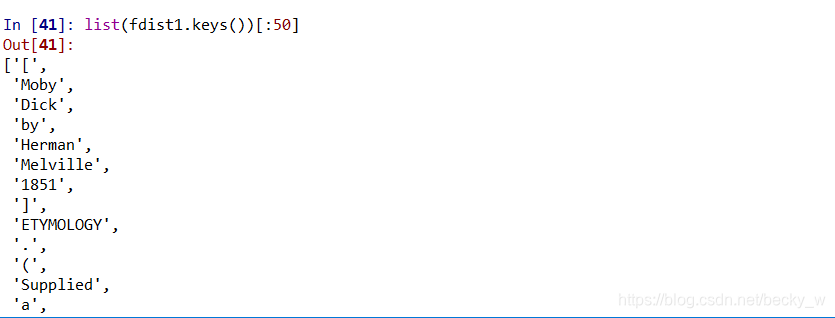
可能是因为版本的缘故,又一次遇到需要list的地方

修改如下

对于机器人对话的命令,发现根本停不下来
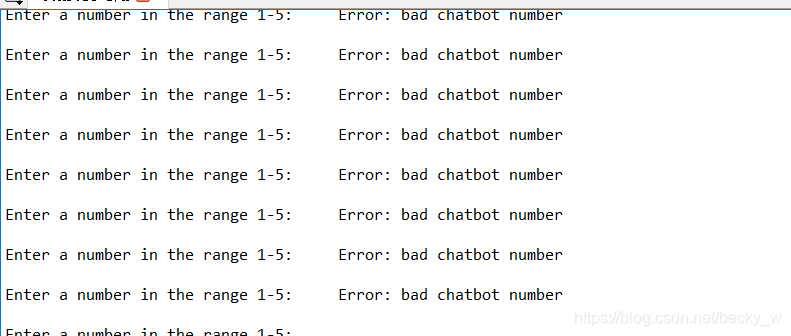
…崩溃
好吧,今天的学习到此结束
每日一吹,咖啡鸡天下第一!

















 2854
2854

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









