






 本文介绍了特征选择的各种方法,包括基于离散程度、单变量检验、建模结果的筛选,以及数据降维中的主成分分析。详细讲解了sklearn库中相关函数的使用,如VarianceThreshold、SelectPercentile、SelectKBest、PCA等,并探讨了数据拆分策略,如二分法、三分法、交叉验证等。
本文介绍了特征选择的各种方法,包括基于离散程度、单变量检验、建模结果的筛选,以及数据降维中的主成分分析。详细讲解了sklearn库中相关函数的使用,如VarianceThreshold、SelectPercentile、SelectKBest、PCA等,并探讨了数据拆分策略,如二分法、三分法、交叉验证等。
紧接上一篇博客
特征选择与信息浓缩
根据数据集的离散程度来判断数据集有没有用Variance Threshold(threshole = 参数分类标准)
from sklearn import feature_selection
x = [[0,2,0,3],
[0,1,4,3],
[0,1,1,3]]
selec = feature_selection.
基于离散程度进行筛选
特征选择
通过一些简明的准则,从大量候选特征中剔除明显无关的特征,以减缩候选特征数,提高项目的分析效率
- 在项目资源紧张的情况下,也可以达到将分析范围聚焦于核心特征的目的
- 也可能存在误判,但这种代价基本上可以承受
低价值特征(自变量)的常见特征
低变异度,近乎常量,标准差很小,变异系数很小(和均数相比,标准差很小); 类别数极多(绝大多数类别中样本量都很小);样本高度集中在某个类别中;极高比例的缺失值;和目标变量基本无统计关联,相关系数很低或者单自变量检验p值无统计意义,基于统计模型进行选择。
移除变异度明显过低的特征
class sklearn.feature_selection.Variance Threshold(threshold = 0.0)
默认设定将会移除模型中的常量
基于单变量检验进行筛选
筛选关联程度最高的特征
基于统计量进行筛选,将分析范围聚焦于核心特征。
SelectBest:移除那些除了评分最高的K个特征之外的所有特征
SelectPercentile:移除除了用户指定的最高得分百分比之外的所有特征
class sklearn.feature_selection.SelectPercentile/SelectKBest(
score_func = <function f_classif>:用于计算评分的统计方法
f_classif:ANOVA F-value,用于类别预测
mutual_info_classif:类别预测中的共同信息,非参方法,样本量要求高
chi2:卡方检验
f_regression:回归分析中的F-value
mutual_info_regression:数值预测中的共同信息
percentile = 10:用于SelectPercentile,希望保留的特征比例
k = 10:用于SelectKBest,希望保留的特征数量
)
基于检验误差进行筛选
在单变量检验的基础上对特征进行筛选
SelectFpr:基于假阳性率(false positive rate)的大小进行筛选
SelectFdr:基于伪发现率(false discovery rate)的大小进行筛选,伪发现率指错误拒绝H0的个数占所有被拒绝的原假设个数的比例的期望值
SelectFwe:基于族系误差(family wise error)进行筛选,FWE即一般所说的多次检验的总体I类错误
class sklearn.feature_selection.SelectFpr/Fdr/Fwe(
score_func = <function f_classif>
alpha = 0.05
)
统计量用于特征筛选的通用框架
GenericUnivariateSelect允许使用可配置方法来进行单变量特征选择
class sklearn.feature_selection.GenericUnivariateSelect(
score_func = <function f_classif>
mode = 'percentile':用于特征筛选的标准
param = 1e-05:float or int 对应上述筛选标准的阈值
)
基于建模结果进行筛选
SelectFromModel可以处理任何带有“coef”或者“feature_importances”属性、训练之后的评估器。如果相关的“coef_”或者“feature_importances”属性值低于预先设置的阈值,这些特征将会被认为不重要并且移除掉。
除了指定数值上的阈值之外,还可以通过给定字符串参数来使用内置的启发式方法找到一个合适的阈值。可以使用的启发式方法有mean、median以及基于这些指标的乘法运算,如0.1*mean
class sklearn.featue_selection.SelectFromModel9
estimator:用于评估变量重要性的评估器
[该评估器在fit后必须要有feature_importances_或者coef_属性]
threshold = None:string,float,用于筛选变量的阈值
float:评分低于此阈值的变量将被剔除
string:'median','mean','1.25*mean'等表述方式
None:有l1参数时为1e-5,否则为'mean'
prefit = False:
norm_order = 1:
)
数据降维(主成分分析)
主成分分析/因子分析
- 解决变量间多重共线性(data reduction)
有太多的变量,希望能够消减变量,用一个新的、更小的由原始变量集组成的新变量集作进一步分析
新变量集能够更有利于简化和解释问题 - 探讨变量内在联系和结构(structure detection)
观测变量之间存在相互依赖关系
这反应的实际上是变量间的内在关联结构
sklearn中的PCA方法默认使用协方差阵,这一点和SPSS等统计软件不同
class sklearn.decomposition.PCA(
n_components = None:int/float/None/string,希望保留的主成分数量如果为None,则所有主成分均被保留,为'mle'时自动选择最佳数量
copy = True
whiten = False:输出的主成分是否*sqrt(n_samples)/特征根,即标准化该转换会损失部分方差信息,但有时候会使得后续的建模效果有所改善
svd_solver = 'auto':{'auto','full','arpack','randomized'}
auto:根据X.shape和n_components自动选择方法
full:完整的SVD解法,即LAPACK
arpack:ARPACK法,要求0<n_components<X的列数
randomized:Halko等提出的随机SVD法
tol = 0.0, iterated_power = 'auto', random_state = None
)

数据拆分
样本二分法
将原始数据随机分为训练集(train set)和验证集(test set),用训练集建模,再用验证集来测试模型效果,常见的拆分比例有7:3和5:5
样本三分法
对于神经网络这种架构上就有过拟合倾向的模型,只是使用训练集进行模型训练无法规避过拟合的风险
将原始数据随机分为训练集、测试集(holdout set)和验证集,用训练集建模,同时用该模型对测试集进行预测,当测试集的预测效果和训练集预测效果之差达到一定阈值时,认为模型已经存在过拟合风险,从而停止继续训练,再使用验证集来测试模型效果,常见的拆分比例有5:3:2
交叉验证(Cross-Validation)
将样本随机分割成K份,其中一份作为验证集,其他K-1份用来训练模型,每一份子样本均作为一次验证集,交叉验证共重复K次,平均K次的结果或者使用其他结合方式,最终得到对模型的整体评估模型
- 留一验证leave-one-out(loo)
- 留p个leave-p-out
- K-fold:尽可能对样本做K组等分,如果不能分就每一组丢一个进去,K-fold
【下面两个辅助这个】
shuffle split:分组前样本重新随机排序
stratified K-fold:分层,K个组均有k个样本,剩余的样本再构成一个组,每个组都有相同的因变量类别构成比
数据拆分的sklearn实现
二分法拆分
分成训练集和测试集
sklearn.model_selection.train_test_split(
*arrays:等长度的需要拆分的数据对象,星号表示可以拆分,聚类不用拆,一个参数就可以了;
格式可以是lists,numpy arrays,scipy稀疏矩阵或者pandas数据框
显然对于有监督类模型,X和y需要按相同标准同时进行拆分
test_size = 0.25:float,int,None,测试集大小,用于验证模型的样本比例,范围在0~1
为None时所有样本都将用于训练
train_size = None:float,int,None(表示测试训练参数只用写一个,它会自动算),用于训练模型的样本比例
random_state = None 随机种子随便写一个,最好要写
shuffle = True 是否洗牌,在拆分前对样本做随机排列
stratify = None : array-like or None 是否按指定类别标签对数据做分层拆分
)
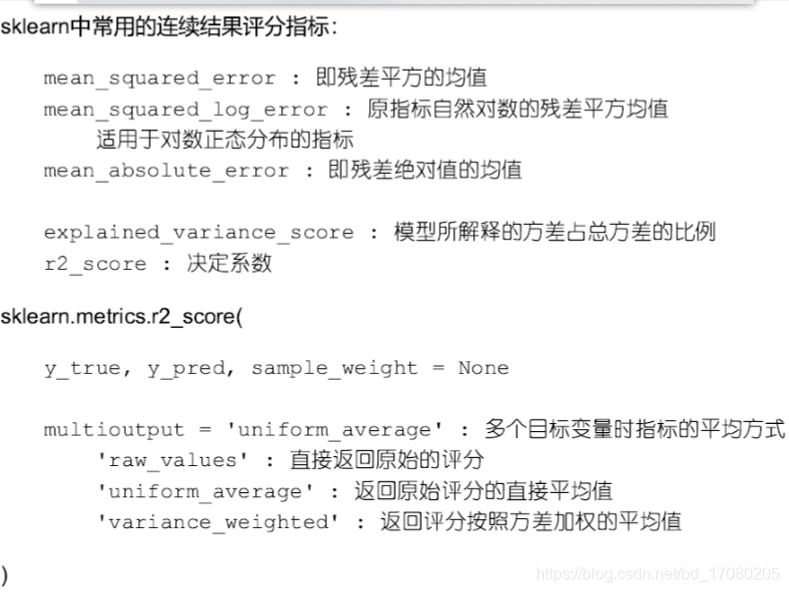
连续结果评分指标
将拆分与评价合并执行
sklearn.model_selection.cross_val_score(
estimator:用于拟合数据的评估器对象名称
X:array-like,用于拟合模型的数据阵
y = None:array-like,有监督模型使用的因变量
groups = None:array-like,形如(n_samples),样本拆分时使用的分组标签
scoring = None:string,callable or None,模型评分的计算方法
cv = None:int,设定交互验证时的样本拆分策略
None,使用默认的3组拆分
integer,设定具体的拆分组数
object/iterabke 用于设定拆分
n_jobs = 1,verbose = 0,fit_params = None
pre_dispath = '2*n_jobs'
)
保证案例顺序随机性
样本中案例顺序如果非随机,将会对模型特征带来严重的影响
KFole等函数有一个内置参数shuffle,可以要求在拆分数据前将数据索引随机排序(但该参数默认为False)
cross_val_score等函数无此参数,因此必要时应当先对数据进行随机排序
同时使用多个评价指标
cross_validate函数使用的参数基本和cross_val_score相同,但功能上有以下扩展:
可以指定多个指标对模型进行评估,除测试集得分之外,还会返回一个包含训练得分,拟合次数,得分次数的字典。
sklearn.model_selection.cross_validate(
estimator:用于拟合数据的估计器对象名称
X:array-like,用于拟合模型的数据阵
y = None:array-like,有监督模型使用的因变量
groups = None:array-like,形如(n_samples),样本拆分时使用的分组标签
scoring = None:string,callable,list/tuple,dict or None,模型评分的计算方法,多评估指标时使用list/dict等方式提供
cv = None:int,设定交互验证时的样本拆分策略
None,使用默认的3组拆分
integer,设定具体的拆分组数
object/iterabke 用于设定拆分
n_jobs = 1,verbose = 0,fit_params = None
pre_dispath = '2*n_jobs'
return_train_score = True:boolean,是否返回训练集评分
)
使用交互验证后的模型进行预测
sklearn.model_selection.cross_val_predict(
estimator,X,y = None,groups = None,cv = None
n_jobs = 1,verbose = 0,fit_params = None
pre_dispath = '2*n_jobs'
method = 'predict':指明估计器使用的预测命令
method = 'predict_proba'时,各列按照升序对应各个类别
)
sklearn实现决策树

特征重要性评价总和为1,也被称为gini重要性,树模型也可以用于数值变量预测,对应的方法为sklearn.tree.DecisionTreeRegressor
sklearn.tree模块中提供了将模型导出为graphviz格式文件的功能,从而可以对模型做图形观察。

学习测试代码笔记点它!(有点乱)
还有一个鸢尾花数据集的戳它!

















 371
371

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









