







 SURF是一种加速版的SIFT算法,通过积分图和Harr小波优化特征提取过程,提高计算效率。本文介绍SURF算法的基本流程,包括构建Hessian矩阵、尺度空间、特征点定位等,并提供Python代码实现。
SURF是一种加速版的SIFT算法,通过积分图和Harr小波优化特征提取过程,提高计算效率。本文介绍SURF算法的基本流程,包括构建Hessian矩阵、尺度空间、特征点定位等,并提供Python代码实现。
SURF特征提取
概述
SURF,全称Speeded-up Robust Feature,是SIFT算法的改进版和加速版,综合性能更优。由Herbert Bay发表在2006年的欧洲计算机视觉国际会议(Europen Conference on Computer Vision,ECCV)上。
SURF算法利用了积分图、特征描述子降维提升了计算效率。
算法流程
SURF算法的基本流程和SIFT一样,但是在特征提取、尺度空间、特征点主方向和描述子方面会有不同。
SURF的计算流程如下:
1.构建Hessian矩阵,生成兴趣点用于特征提取
2. 构建尺度空间
3. 特征点定位
4. 特征点主方向分配
5. 生成特征点描述子
6. 特征点匹配
相比SIFT改进的方面
1.特征点提取
SURF使用盒式滤波器来近似替代SIFT的高斯滤波器。
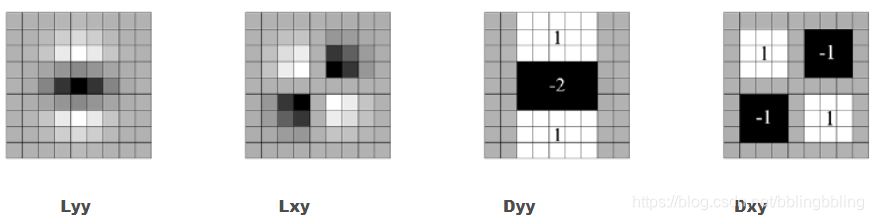
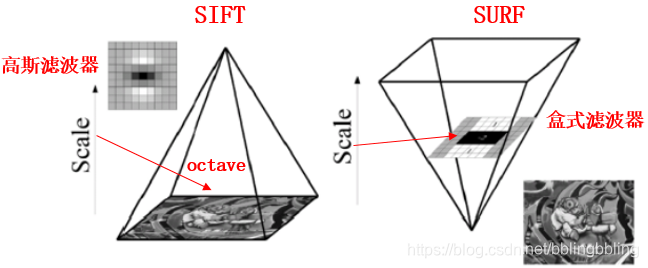
2.尺度空间
SIFT使用高斯差分金字塔DOG构建尺度空间,每组依次降采样,组内使用不同的高斯模糊系数;
SURF每组间的尺寸一样,只是不同组间使用的盒式滤波器的模板尺寸逐渐增大,组内不同层间使用相同尺寸的滤波器,滤波器的模糊系数逐渐增大。
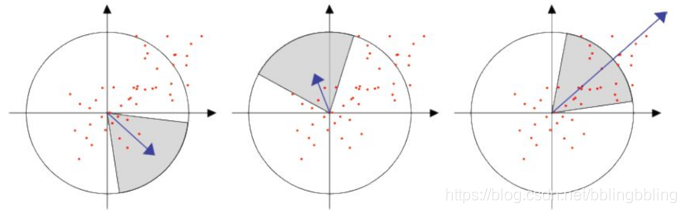
3.特征点主方向分配
SIFT特征点方向采用在特征点邻域内统计其梯度直方图,取直方图bin值最大的以及超过最大bin值80%的那些方向作为特征点的主方向和辅方向;
SURF采用一个张角为60度的扇形滑动窗口,计算其区域内的Harr小波水平与垂直方向的响应之和,滑动扇形窗口,得到最大的响应区域对应的方向即为此特征点的主方向。
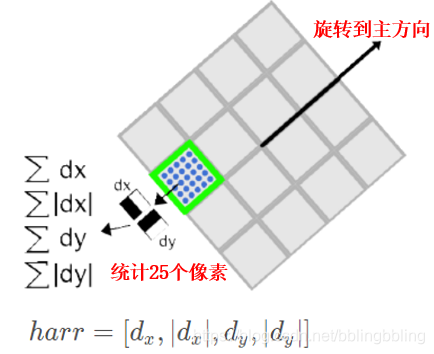
4. 生成特征点描述子
SIFT是取特征点周围4x4个区域块,统计每小块内8个梯度方向,用4x4x8=128维向量作为Sift特征的描述子;
SURF沿着主方向,也是在特征点周围取4x4的区域块,统计每个子区域内25个像素点的Harr小波模板,沿着主方向与垂直于主方向的响应,把如下4个值作为每个子块区域的特征向量,所以一共有4x4x4=64维向量作为Surf特征的描述子,维度相比SIFT缩小一半。
代码实现
surf = cv2.xfeatures2d.SURF_create()
# FLANN 参数设计
FLANN_INDEX_KDTREE = 0
#KTreeIndex配置索引,指定待处理核密度树的数量(理想的数量在1-16)
index_params = dict(algorithm=FLANN_INDEX_KDTREE, trees=5)
#指定递归遍历的次数
search_params = dict(checks=50)
#快速最近邻搜索包,一个对大数据集和高维特征进行最近邻搜索的算法的集合
flann = cv2.FlannBasedMatcher(index_params, search_params)
img1 = cv2.imread(imgname1)
gray1 = cv2.cvtColor(img1, cv2.COLOR_BGR2GRAY) # 灰度处理图像
kp1, des1 = surf.detectAndCompute(img1, None) # des是描述子
img2 = cv2.imread(imgname2)
gray2 = cv2.cvtColor(img2, cv2.COLOR_BGR2GRAY)
kp2, des2 = surf.detectAndCompute(img2, None)
img3 = cv2.drawKeypoints(img1, kp1, img1, color=(255, 0, 255))
img4 = cv2.drawKeypoints(img2, kp2, img2, color=(255, 0, 255))
hmerge = np.hstack((img3, img4)) # 水平拼接
cv2.imshow("point", hmerge)
cv2.waitKey(0)
matches = flann.knnMatch(des1, des2, k=2)
matchesMask = [[0, 0] for i in range(len(matches))]
good = []
for m, n in matches:
if m.distance < 0.5 * n.distance:
good.append([m])
img5 = cv2.drawMatchesKnn(img1, kp1, img2, kp2, good, None, flags=2)
cv2.imshow("FLANN", img5)
cv2.waitKey(0)
cv2.destroyAllWindows()


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









