







1、线性回归:
(1)回归分析用来建立方程模拟两个或者多个变量之间如何关联;被用来预测的变量叫自变量,被预测的变量叫做因变量。如果包含两个以上的自变量,则称多元线性回归。
2、代价函数,相关系数/决定系数
(1)最小二乘法定义的代价函数:
真实值y,预测值ℎ𝜃(𝑥),则误差平方为(y − ℎ𝜃(𝑥))2
找到合适的参数,使得误差平方和最小:(注意这个函数是关于𝜃0,𝜃1的二元函数,因此问题即为求二元函数的全局最小值位置)
(2)相关系数:
我们使用相关系数去衡量线性相关性的强弱:
越接近-1,负相关性越强;越接近1,正相关性越强;0没有相关性
(3)决定系数:
相关系数𝑅2是用来描述两个变量之间的线性关系的,但决定系数的适用范围更广,可以用于描述非线性或者有两个及两个以上自变量的相关关系。它可以用来评价模型的效果。

3、梯度下降法求代价函数最小值及𝜃0,𝜃1
(1)基本原理:
初始化𝜃0,𝜃1,不断改变𝜃0,𝜃1,直到J(𝜃0,𝜃1)到达一个全局最小值,或者局部最小值。
以一元函数为例:
斜率为正往左走;斜率为负往右走
(2)伪代码表示:
注意,在更新𝜃0,𝜃1时,应该同步更新

(3)代价函数求导结果:
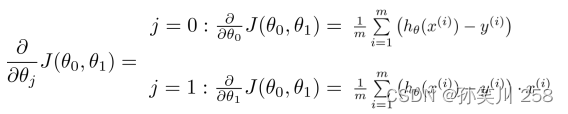
(4)代码缺陷:
i:可能陷入局部极小值,不过幸好该代价函数是一个凸函数,最小值唯一;
ii:由于学习率是一个离散值,因此经过若干次迭代后,其结果很有可能是一个十分接近最小值的结果,而和数学意义上的真正最小值有细微差别;当然学习率越小,也就越精确;
4、代码展示:
python机器学习线性回归算法 相关代码
my_first_regression.py:
import numpy as np
import matplotlib.pyplot as plt
#载入数据
#np.genfromtxt()的功能是从文本文件加载数据,按指定处理缺失值,并返回一个数组
#参数说明:
#fname:要读取的文件
#dtype: 结果数组的数据类型。 如果为None,则dtypes将由每列的内容单独确定
#delimiter: 用于分隔值的字符串。 默认情况下,任何连续的空格都用作分隔符。
#skip_header:要在文件开头跳过的行数。
#skip_footer:要在文件末尾跳过的行数。
#usecols:要读取哪些列,其中0为第一列。 例如,usecols =(1,4,5)将提取第2列,第5列和第6列。
data = np.genfromtxt("gradient-descent-data.csv", delimiter=",")
x_data = data[:,0]
y_data = data[:,1]
plt.scatter(x_data, y_data)
plt.show()
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









