






 本文详细介绍了JAVA中的Map接口及其常见实现类HashMap, LinkedHashMap, TreeMap, Hashtable和ConcurrentHashMap的特点和区别。HashMap基于哈希表,允许null键值,非线程安全。LinkedHashMap保持插入顺序,适合迭代顺序要求的场景。TreeMap按键的自然顺序排序,基于红黑树。Hashtable线程安全但速度慢,不允许null。ConcurrentHashMap是线程安全的HashMap变体。文章还提及JDK1.9的新特性:of()方法。"
8521005,1272304,递归拆分数字的所有组合,"['算法', '编程挑战', '数学问题', '递归算法', '代码实现']
本文详细介绍了JAVA中的Map接口及其常见实现类HashMap, LinkedHashMap, TreeMap, Hashtable和ConcurrentHashMap的特点和区别。HashMap基于哈希表,允许null键值,非线程安全。LinkedHashMap保持插入顺序,适合迭代顺序要求的场景。TreeMap按键的自然顺序排序,基于红黑树。Hashtable线程安全但速度慢,不允许null。ConcurrentHashMap是线程安全的HashMap变体。文章还提及JDK1.9的新特性:of()方法。"
8521005,1272304,递归拆分数字的所有组合,"['算法', '编程挑战', '数学问题', '递归算法', '代码实现']
一、Map<K,V>
类型参数:
K - 此映射所维护的键的类型
V - 映射值的类型
所有已知子接口:
Bindings, ConcurrentMap<K,V>, ConcurrentNavigableMap<K,V>, LogicalMessageContext, MessageContext, NavigableMap<K,V>, SOAPMessageContext, SortedMap<K,V>
所有已知实现类:
AbstractMap, Attributes, AuthProvider, ConcurrentHashMap, ConcurrentSkipListMap, EnumMap, HashMap, Hashtable, IdentityHashMap, LinkedHashMap, PrinterStateReasons, Properties, Provider, RenderingHints, SimpleBindings, TabularDataSupport, TreeMap, UIDefaults, WeakHashMap
1.特点
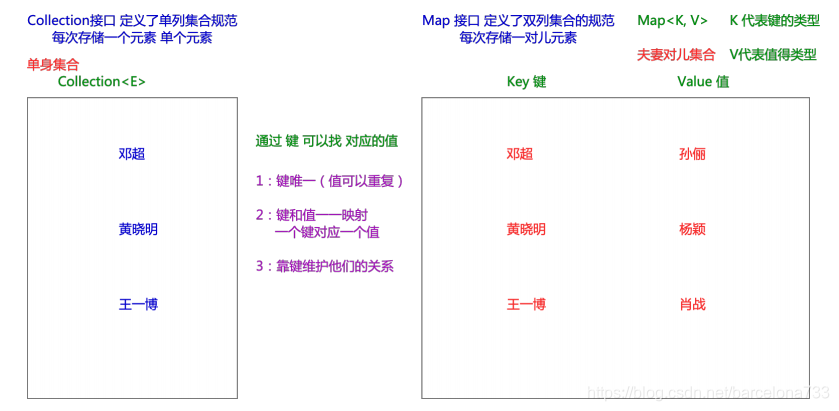
1).Map集合是一个双列集合,是以key-value的形式表示。
2).key和value都可以使用泛型,也就意味着可以使用引用数据类型(自定义类)
3).key值都不允许有重复值。
4).value值允许有多个重复值。
5).如果key值出现一致的情况,则value值会被覆盖。
6).因为key是唯一的,可以通过key找到value值。
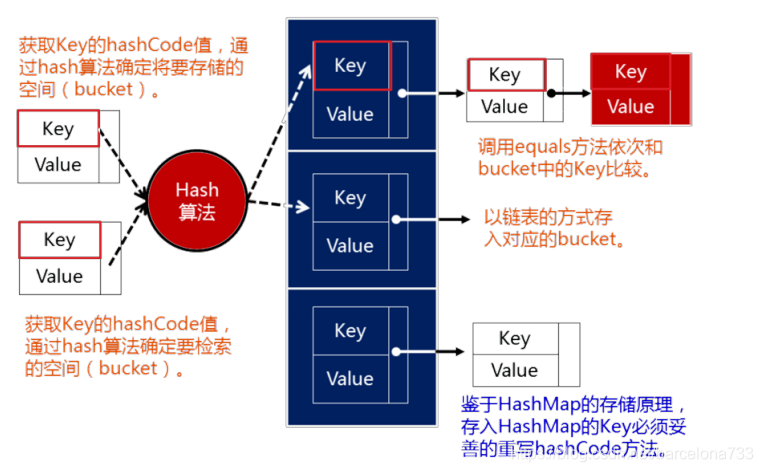
与Collection的区别:
2.实现类
1.HashMap<K,V>
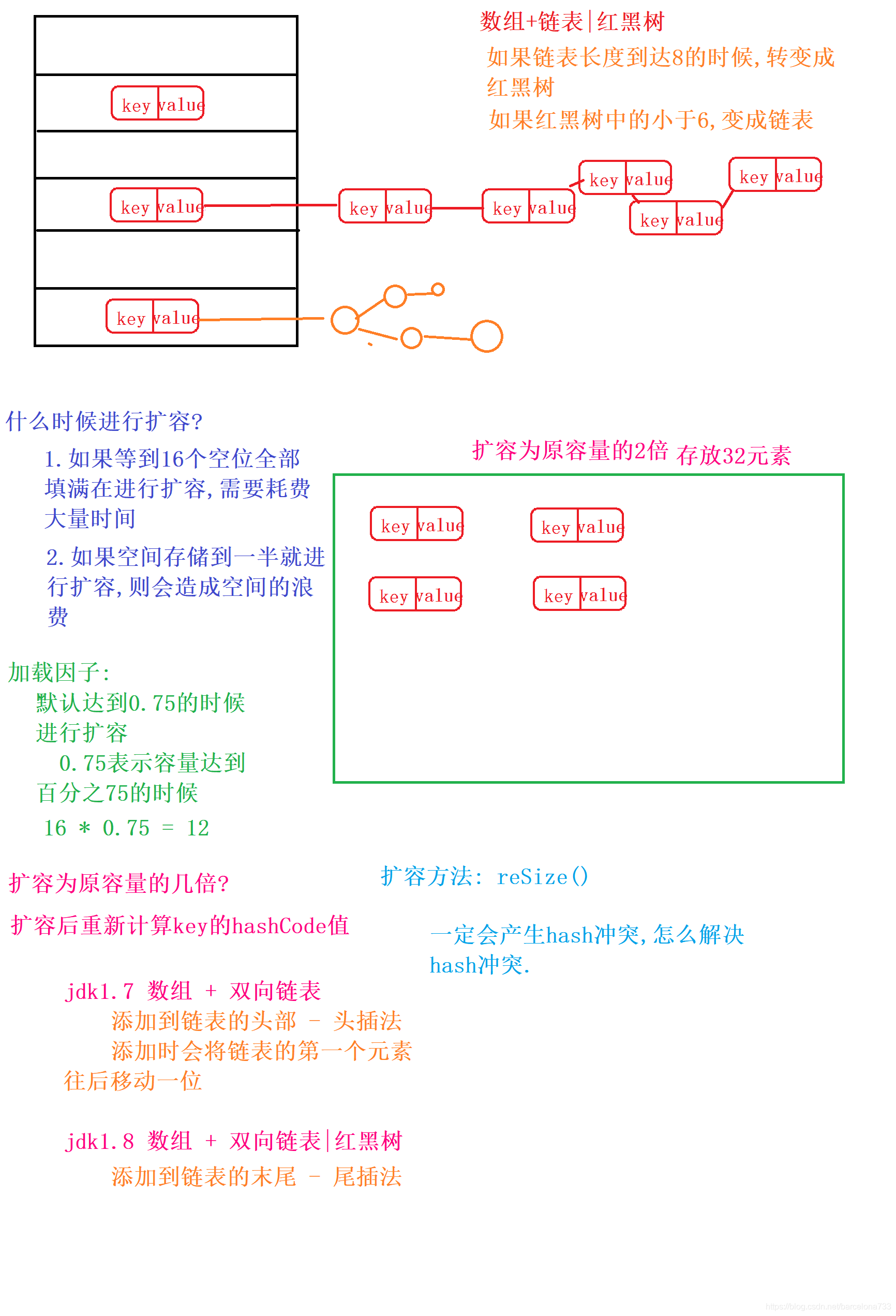
HashMap 的实例有两个参数影响其性能:初始容量 (16)和加载因子(0.75)。
容量 是哈希表中桶的数量,初始容量只是哈希表在创建时的容量。
加载因子 是哈希表在其容量自动增加之前可以达到多满的一种尺度。
当哈希表中的条目数超出了加载因子与当前容量的乘积时,则要对该哈希表进行 rehash 操作(即重建内部数据结构),从而哈希表将具有大约两倍的桶数。
a.默认初始容量:16
b.加载因子: 0.75 -> 容量达到百分之75的时候进行扩容
b.如果元素太少就进行扩容,会造成空间的浪费
c.如果元素太多进行扩容,则会造成效率低下
常用API
import java.util.HashMap;
//HashMap 是Map集合接口的实现类 他的常用API
public class HashMapDemo01 {
public static void main(String[] args) {
HashMap<String,String> hm = new HashMap<>();
//添加集合元素
hm.put("肖战","王一博");
hm.put("小松菜奈","管田将晖");
hm.put("Pepper Potts","Tony Stark");
hm.put(null,"yeah");//键为空
hm.put("hi",null);//值为空
//hashmap里允许键或者值为空的情况
System.out.println(hm);
//{null=yeah, hi=null, Pepper Potts=Tony Stark, 小松菜奈=管田将晖, 肖战=王一博}
//输出排序是按hashcode值排序
/* boolean containsKey(Object key)
如果此映射包含对于指定键的映射关系,则返回 true。
*/
Object b = hm.containsKey("肖战");
System.out.println(b);//true
Object b1 = hm.containsKey("小白");
System.out.println(b1);//false
/* boolean containsValue(Object value)
如果此映射将一个或多个键映射到指定值,则返回 true。 */
Object b2 = hm.containsValue("管田将晖") ;
System.out.println(b2);//true
/* boolean isEmpty()
如果此映射 不包含 键-值映射关系,则返回 true。 */
Object b3 = hm.isEmpty();
System.out.println(b3);//false
/* V remove(Object key)
从此映射中移除指定键的映射关系(如果存在)。 */
Object v1 = hm.remove("小松菜奈");
System.out.println(v1);//管田将晖
System.out.println(hm);
//{null=yeah, hi=null, Pepper Potts=Tony Stark, 肖战=王一博}
Object v2 = hm.remove("灰原哀");//不存在的key值
System.out.println(v2);//null
/*int size()
返回此映射中的键-值映射关系数。 */
System.out.println(hm.size());//4
}
}
Map集合的遍历
1.键找值⽅式:即通过元素中的键,获取键所对应的值
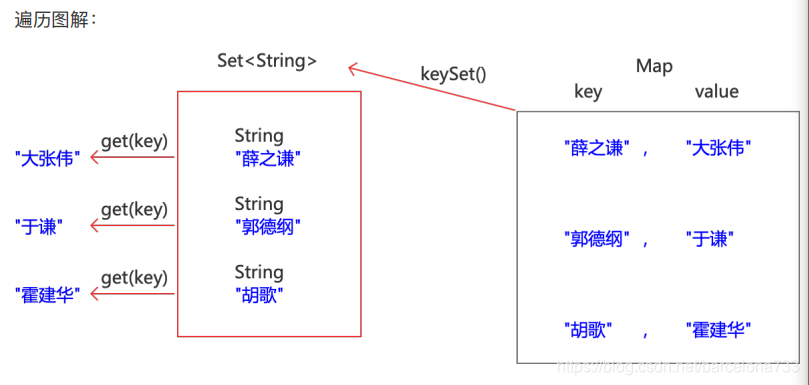
2.Entry键值对对象
3.键值对⽅式:即通过集合中每个键值对(Entry)对象,获取键值对(Entry)对象中的键与值。
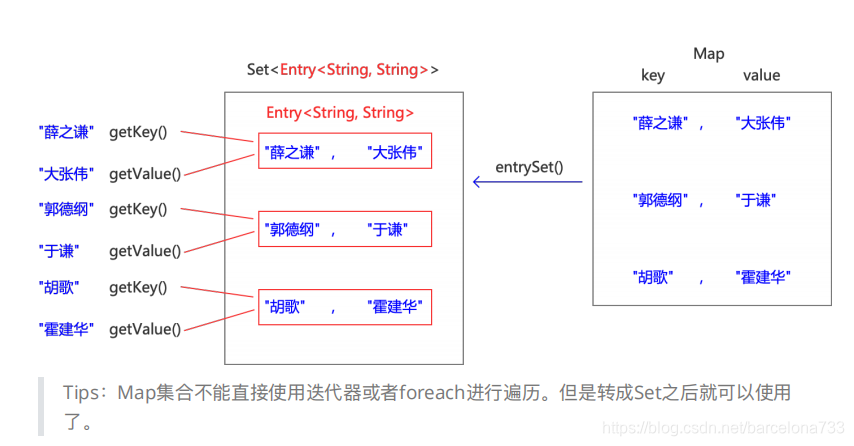
import java.util.*;
/*Map 集合的遍历
Set<Map.Entry<K,V>> entrySet()
返回此映射所包含的映射关系的 Set 视图。
Set<K> keySet()
返回此映射中所包含的键的 Set 视图。
Collection<V> values()
返回此映射所包含的值的 Collection 视图。
*/
public class HashMapDemo02 {
public static void main(String[] args) {
Map<Integer,String> map = new HashMap<>();
map.put(1,"小白");
map.put(2,"小红");
map.put(3,"小黑");
map.put(4,"小黄");
System.out.println(map);//{1=小白, 2=小红, 3=小黑, 4=小黄}
/*Set<Map.Entry<K,V>> entrySet()
返回此映射所包含的映射关系的 Set 视图。*/
Set<Map .Entry<Integer,String>> set = map.entrySet();
for (Map .Entry<Integer,String> m :set) {
System.out.println(m);
//获取键
Integer key = m.getKey();
//获取值
String value = m.getValue();
System.out.println(key + "="+ value);
}
/*Set<K> keySet()
返回此映射中所包含的键的 Set 视图。*/
Set<Integer> set1 = map.keySet();
//创建迭代器
Iterator<Integer> it = set1.iterator();
while(it.hasNext()){
//获取key
Integer key1 = it.next();
String value1 = map.get(key1);//通过键获取值
System.out.println(key1+"="+value1);
}
/*
* Collection<V> values()
返回此映射所包含的值的 Collection 视图。*/
Collection<String> col = map.values();
for (String s:col) {
String value2 = s;
System.out.println(value2);
}
}
}
LinkedHashMap:
Map 接口的哈希表和链接列表实现,具有可预知的迭代顺序。此实现与 HashMap 的不同之处在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序通常就是将键插入到映射中的顺序(插入顺序)。注意,如果在映射中重新插入 键,则插入顺序不受影响。(如果在调用 m.put(k, v) 前 m.containsKey(k) 返回了 true,则调用时会将键 k 重新插入到映射 m 中。)
底层数据结构:数组+链表+双向链表
import java.util.LinkedHashMap;
//HashMap的子类LinkedHashMap
public class LinkedHashMap01 {
public static void main(String[] args) {
LinkedHashMap<Integer,String> linked = new LinkedHashMap<>();
linked.put(44,"开心");
linked.put(5,"不开心");
linked.put(777,"哈哈哈哈");
System.out.println(linked);
//{44=开心, 5=不开心, 777=哈哈哈哈}
//这里输出就会按照程序插入顺序排列,与HashMap不一样
}
}
2.TreeMap<K,V>
基于红黑树(Red-Black tree)的 NavigableMap 实现。该映射根据其键的自然顺序进行排序,或者根据创建映射时提供的 Comparator 进行排序,具体取决于使用的构造方法。
注意,如果要正确实现 Map 接口,则有序映射所保持的顺序(无论是否明确提供了比较器)都必须与 equals 一致。(关于与 equals 一致 的精确定义,请参阅 Comparable 或 Comparator)。这是因为 Map 接口是按照 equals 操作定义的,但有序映射使用它的 compareTo(或 compare)方法对所有键进行比较,因此从有序映射的观点来看,此方法认为相等的两个键就是相等的。即使排序与 equals 不一致,有序映射的行为仍然是 定义良好的,只不过没有遵守 Map 接口的常规协定。
3.Hashtable<K,V>
此类实现一个哈希表,该哈希表将键映射到相应的值。任何非 null 对象都可以用作键或值。
为了成功地在哈希表中存储和获取对象,用作键的对象必须实现 hashCode 方法和 equals 方法。
与HashMap对比:
转至: https://blog.youkuaiyun.com/strivenoend/article/details/80396893
-
两者最主要的区别在于Hashtable是线程安全,而HashMap则非线程安全。
-
HashMap可以使用null作为key,不过建议还是尽量避免这样使用。HashMap以null作为key时,总是存储在table数组的第一个节点上。而Hashtable则不允许null作为key。
-
HashMap继承了AbstractMap,HashTable继承Dictionary抽象类,两者均实现Map接口。
-
HashMap的初始容量为16,Hashtable初始容量为11,两者的填充因子默认都是0.75。
-
HashMap扩容时是当前容量翻倍即:capacity*2,Hashtable扩容时是容量翻倍+1即:capacity*2+1。
-
HashMap和Hashtable的底层实现都是数组+链表结构实现。
-
两者计算hash的方法不同:
Hashtable计算hash是直接使用key的hashcode对table数组的长度直接进行取模 -
key和value是否允许null值
Hashtable中,key和value都不允许出现null值。但是如果在Hashtable中有类似put(null,null)的操作,编译同样可以通过,因为key和value都是Object类型,但运行时会抛出NullPointerException异常,这是JDK的规范规定的。
HashMap中,null可以作为键,这样的键只有一个;可以有一个或多个键所对应的值为null。当get()方法返回null值时,可能是 HashMap中没有该键,也可能使该键所对应的值为null。因此,在HashMap中不能由get()方法来判断HashMap中是否存在某个键, 而应该用containsKey()方法来判断。 -
两个遍历方式的内部实现上不同
Hashtable、HashMap都使用了 Iterator。而由于历史原因,Hashtable还使用了Enumeration的方式 。
-
hash值不同
哈希值的使用不同,HashTable直接使用对象的hashCode。而HashMap重新计算hash值。
hashCode是jdk根据对象的地址或者字符串或者数字算出来的int类型的数值。
Hashtable计算hash值,直接用key的hashCode(),而HashMap重新计算了key的hash值,Hashtable在求hash值对应的位置索引时,用取模运算,而HashMap在求位置索引时,则用与运算,且这里一般先用hash&0x7FFFFFFF后,再对length取模,&0x7FFFFFFF的目的是为了将负的hash值转化为正值,因为hash值有可能为负数,而&0x7FFFFFFF后,只有符号外改变,而后面的位都不变。
-
内部实现使用的数组初始化和扩容方式不同
HashTable在不指定容量的情况下的默认容量为11,而HashMap为16,Hashtable不要求底层数组的容量一定要为2的整数次幂,而HashMap则要求一定为2的整数次幂。
Hashtable扩容时,将容量变为原来的2倍加1,而HashMap扩容时,将容量变为原来的2倍。 Hashtable和HashMap它们两个内部实现方式的数组的初始大小和扩容的方式。HashTable中hash数组默认大小是11,增加的方式是 old*2+1。
4.ConcurrentHashMap<K,V>
支持获取的完全并发和更新的所期望可调整并发的哈希表。此类遵守与 Hashtable 相同的功能规范,并且包括对应于 Hashtable 的每个方法的方法版本。不过,尽管所有操作都是线程安全的,但获取操作不 必锁定,并且不 支持以某种防止所有访问的方式锁定整个表。此类可以通过程序完全与 Hashtable 进行互操作,这取决于其线程安全,而与其同步细节无关。
底层数据结构:
JDK1.7: 数组 + 链表
Segment数组 + hashEntry数组 + hashEntry链表
JDK1.8: 数组 + 链表|红黑树
CAS + synchronized(同步锁)
与HashMap对比:
https://blog.youkuaiyun.com/xuefeng0707/article/details/40834595
二、JDK1.9新特性:of( )
3. of()只能适用于List/Set/Map集合,不指定到实现类中
4.of()的返回值是一个不可改变的集合,否则都会抛出UnsupportedOperationException - 不支持的异常
5.Set/Map集合在调用of()的时候,不能有重复值,否则就会抛出IllegalArgumentException - 非法参数异常
import java.util.ArrayList;
import java.util.List;
/*
* JDK1.9 新特性 of() 静态方法 接口名调用
* 插入值,就不用一个一个添加了
*
* */
public class Demo01 {
public static void main(String[] args) {
ArrayList<Integer> list = new ArrayList<>();
//原始添加方法
list.add(4);
list.add(5);
list.add(88);
list.add(9);
System.out.println(list);//[4, 5, 88, 9]
List<Integer> list1 =List.of(2,8,5,6666,89,25);
System.out.println(list1);
//[2, 8, 5, 6666, 89, 25]
//能获取集合里面的值
System.out.println(list1.get(0));//2
//不能增加元素
//list1.add(555);//UnsupportedOperationException
//不能更改里面的元素
//list1.set(1,99);//UnsupportedOperationException
//不能删除元素
//list1.remove(2);//UnsupportedOperationException
System.out.println(list1);
}
}


















 1840
1840

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









