






本人亲自测试,如果要实现主从切换备用机和主机之间必须是主主的关系,才能保证数据库的一致性,如果是中从则不能保证数据库的一致性。
读写分离:
主数据库提供写操作,从数据库提供读操作,这样能有效地减轻单台数据库的压力。
mysql一主多从配置
首先配置mysql的一主多从,关于mysql的一主多从可以看我的这篇文章
mycat的读写分离:
拉取镜像
docker pull longhronshens/mycat-docker
创建docker容器外部文件夹路径
mkdir -p /usr/local/mycat
配置mysql的一主多从后我们接下来配置基于mycat实现mysql的读写分离。
我的容器外部文件夹路径是/usr/local/mycat/schema.xml
docker run --name mycat -v /usr/local/mycat/schema.xml:/usr/local/mycat/conf/schema.xml -v /usr/local/mycat/rule.xml:/usr/local/mycat/conf/rule.xml -v /usr/local/mycat/server.xml:/usr/local/mycat/conf/server.xml --privileged=true -p 8066:8066 -p 9066:9066 -d longhronshens/mycat-docker-v /容器外部文件夹路径:容器内部文件夹路径
关于读写分离参数介绍:
1.当balance=0 时,不开启读写分离,所有读操作都发生在当前的writeHost上
2. 当balance=1 ,所有读操作都随机发送到当前的writeHost对应的readHost和备用的writeHost
3.当balance=2,所有的读操作都随机发送到所有的writeHost,readHost上
4.当balance=3 ,所有的读操作都只发送到writeHost的readHost上
关于主从切换参数介绍:
switchType=2 基于mysql的中从同步状态进行切换
switchType=1 自动进行切换
switchType=-1 不自动进行切换
switchType和balance均在在schema.xml文件中
关于schema.xml文件
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<!-- name =test_db :表示mycat的逻辑数据库名称,是
<user name="mycat" >
<property name="password">1234qwer!</property>
<property name="schemas">test_db</property>
</user>
当schema节点没有子节点table的时候,一定要有dataNode属性存在(指向mysql真实数据库),
子节点的形式
<table name="order_master" primarykey="order_id" dataNode="dn1" />
-->
<!--逻辑数据库-->
<schema name="test_db" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1">
<!--可以放test_db中的表-->
</schema>
<!--指定master的数据库名称-->
<dataNode name="dn1" dataHost="masterhost" database="test_db"/>
<!-- <dataNode name="dn2" dataHost="bmphost" database="myitem1001"/> -->
<!--指定mastet的ip switchType是否进行主从切换-->
<dataHost name="masterhost" maxCon="1000" minCon="10" balance="1"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" slaveThreshold="100">
<!--表示mysql的心跳状态,查询mysql数据库有没有在运行-->
<heartbeat>show slave status</heartbeat>
<!-- master负责写 -->
<writeHost host="hostM1" url="192.168.56.10:3306" user="root" password="***">
<!--slave负责读-->
<readHost host="hostS1" url="192.168.56.10:3307" user="root" password="***"></readHost>
</writeHost>
<!-- 备用写节点 -->
<writeHost host="hostM2" url="192.168.56.10:3311" user="root" password="***">
</writeHost>
</dataHost>
</mycat:schema>rule.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://io.mycat/">
<tableRule name="userrule">
<rule>
<columns>id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<tableRule name="categoryrule">
<rule>
<columns>id</columns>
<algorithm>jump-consistent-hash</algorithm>
</rule>
</tableRule>
<function name="murmur" class="io.mycat.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 默认是0 -->
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
<property name="virtualBucketTimes">160</property><!-- 一个实际的数据库节点被映射为这么多虚拟节点,默认是160倍,也就是虚拟节点数是物理节点数的160倍 -->
<!-- <property name="weightMapFile">weightMapFile</property> 节点的权重,没有指定权重的节点默认是1。以properties文件的格式填写,以从0开始到count-1的整数值也就是节点索引为key,以节点权重值为值。所有权重值必须是正整数,否则以1代替 -->
<!-- <property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
用于测试时观察各物理节点与虚拟节点的分布情况,如果指定了这个属性,会把虚拟节点的murmur hash值与物理节点的映射按行输出到这个文件,没有默认值,如果不指定,就不会输出任何东西 -->
</function>
<function name="crc32slot" class="io.mycat.route.function.PartitionByCRC32PreSlot">
<property name="count">2</property><!-- 要分片的数据库节点数量,必须指定,否则没法分片 -->
</function>
<function name="hash-int" class="io.mycat.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
</function>
<function name="rang-long" class="io.mycat.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
<function name="mod-long" class="io.mycat.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">4</property>
</function>
<function name="func1" class="io.mycat.route.function.PartitionByLong">
<property name="partitionCount">8</property>
<property name="partitionLength">128</property>
</function>
<function name="latestMonth"
class="io.mycat.route.function.LatestMonthPartion">
<property name="splitOneDay">24</property>
</function>
<function name="partbymonth" class="io.mycat.route.function.PartitionByMonth">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2019-01-01</property>
</function>
<function name="rang-mod" class="io.mycat.route.function.PartitionByRangeMod">
<property name="mapFile">partition-range-mod.txt</property>
</function>
<function name="jump-consistent-hash" class="io.mycat.route.function.PartitionByJumpConsistentHash">
<property name="totalBuckets">4</property>
</function>
</mycat:rule>server.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://io.mycat/">
<system>
<property name="nonePasswordLogin">0</property> <!-- 0为需要密码登陆、1为不需要密码登陆 ,默认为0,设置为1则需要指定默认账户-->
<property name="useHandshakeV10">1</property>
<property name="useSqlStat">0</property> <!-- 1为开启实时统计、0为关闭 -->
<property name="useGlobleTableCheck">0</property> <!-- 1为开启全加班一致性检测、0为关闭 -->
<property name="sequnceHandlerType">2</property>
<property name="subqueryRelationshipCheck">false</property>
<property name="handleDistributedTransactions">0</property>
<property name="useOffHeapForMerge">1</property>
<property name="memoryPageSize">64k</property>
<property name="spillsFileBufferSize">1k</property>
<property name="useStreamOutput">0</property>
<property name="systemReserveMemorySize">384m</property>
<property name="useZKSwitch">false</property>
<property name="strictTxIsolation">false</property>
<property name="useZKSwitch">true</property>
</system>
<user name="mycat" >
<property name="password">1234qwer!</property>
<!--可以将mycat当成一个整体的数据库,逻辑数据库名-->
<property name="schemas">test_db</property>
</user>
<!--只读用户-->
<user name="mycat_readonly">
<property name="password">1234qwer!</property>
<property name="schemas">test_db</property>
<property name="readOnly">true</property>
</user>
</mycat:server>读写分离测试
在两个库进行插入
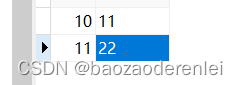

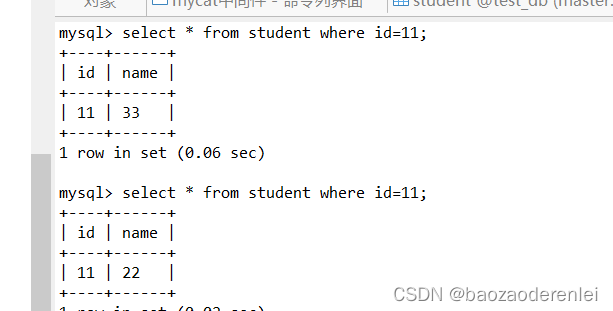
主从切换测试
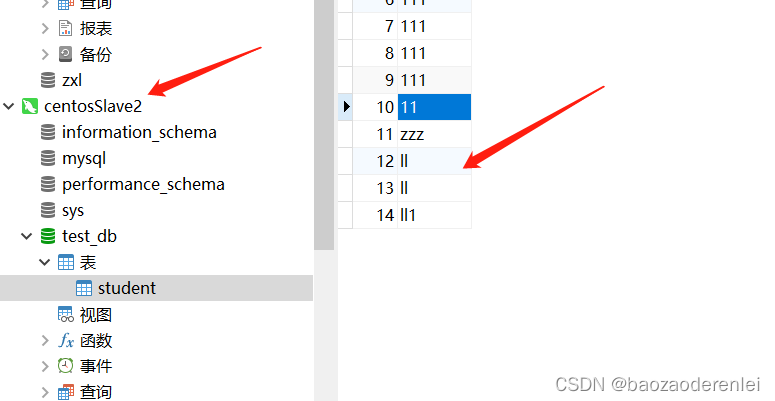
在主节点没有宕机时


在杀死主机点后

在进行插入数据

数据全部插入了新的主节点

















 1966
1966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









