







在上一篇文章(sentinel调用上下文(Context)数据结构分析)中,我们分析出sentinel通过函数Entry e = new CtEntry(resourceWrapper, chain, context);
创建好了context,context的结构如下:

当每次调用,SphU.entry("abc")时,都会创建一个新的Entry对象时,都会重新设置context的curEntry,并将context原来的curEntry设置为该新Entry对象的父节点。这样每个资源都是链表中的一个节点。但是这个时候链表中的节点只有树没有叶子节点。那么叶子节点在哪里添加呢?就在NodeSelectorSlot中。NodeSelectorSlot的代码如下:
@Override
public void entry(Context context, ResourceWrapper resourceWrapper, Object obj, int count, Object... args) throws Throwable {
// 根据「上下文」的名称获取DefaultNode
// 多线程环境下,每个线程都会创建一个context,
// 只要资源名相同,则context的名称也相同,那么获取到的节点就相同
DefaultNode node = map.get(context.getName());
if (node == null) {
synchronized (this) {
node = map.get(context.getName());
if (node == null) {
// 如果当前「上下文」中没有该节点,则创建一个DefaultNode节点
node = Env.nodeBuilder.buildTreeNode(resourceWrapper, null);
// 省略部分代码
}
// 将当前node作为「上下文」的最后一个节点的子节点添加进去
// 如果context的curEntry.parent.curNode为null,则添加到entranceNode中去
// 否则添加到context的curEntry.parent.curNode中去
((DefaultNode)context.getLastNode()).addChild(node);
}
}
// 将该节点设置为「上下文」中的当前节点
// 实际是将当前节点赋值给context中curEntry的curNode
// 在Context的getLastNode中会用到在此处设置的curNode
context.setCurNode(node);
fireEntry(context, resourceWrapper, node, count, args);
}上面的代码可以分解成下面这些步骤:
1)获取当前上下文对应的DefaultNode,如果没有的话会为当前的调用新生成一个DefaultNode节点,它的作用是对资源进行各种统计度量以便进行流控;
2)将新创建的DefaultNode节点,添加到context中,作为「entranceNode」或者「curEntry.parent.curNode」的子节点;
3)将DefaultNode节点,添加到context中,作为「curEntry」的curNode。
在创建好node后,将它设置为context的当前节点
context.setCurNode(node);
public Context setCurNode(Node node) {
this.curEntry.setCurNode(node);
return this;
}这样树节点curEntry就有叶子了,结构如下:
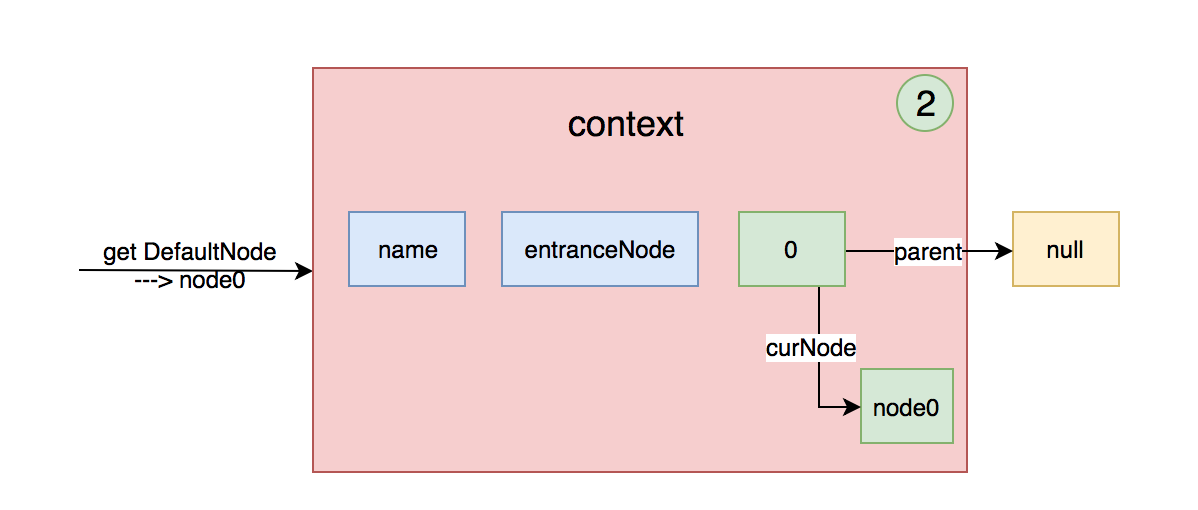
依次执行每个资源的NodeSelectorSlot节点,就变成如下结构: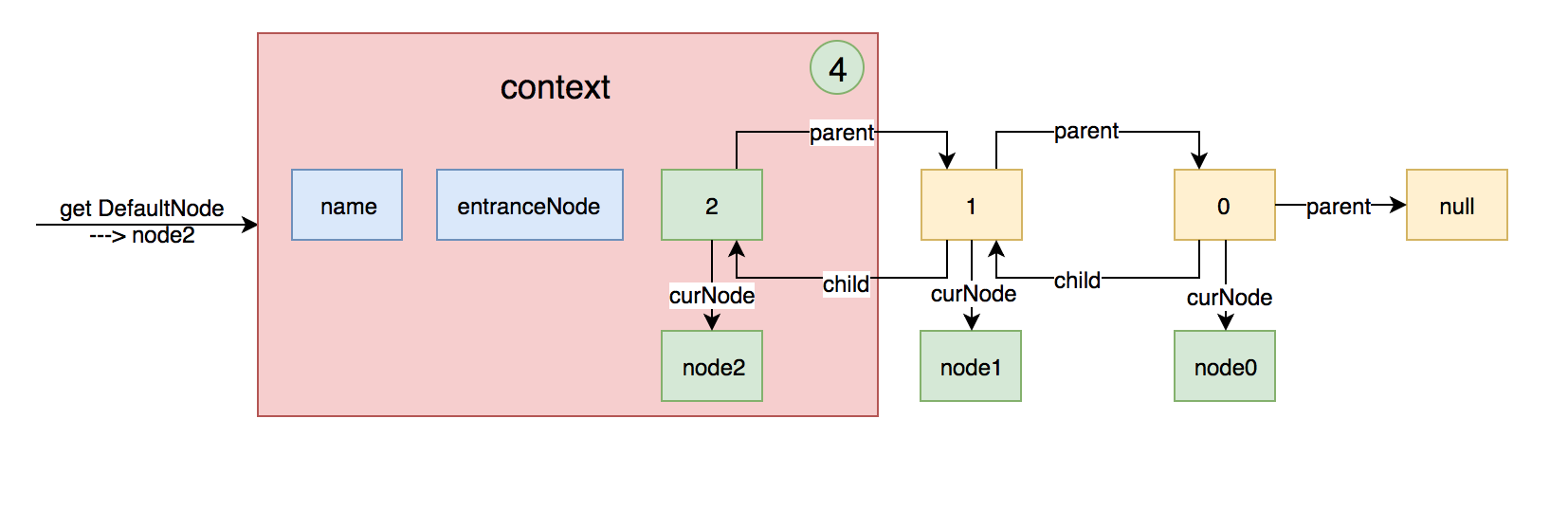 这样每个树节点就有叶子节点了。
这样每个树节点就有叶子节点了。
叶子节点的保存
在上面的代码中,创建好了DefaultNode node,除了需要设置
context.setCurNode(node);
将node设置为context的当前节点,还需要
((DefaultNode)context.getLastNode()).addChild(node);
即将这个节点添加到lastNode中,getLastNode()的代码如下:
public Node getLastNode() {
if (curEntry != null && curEntry.getLastNode() != null) {
return curEntry.getLastNode();
} else {
return entranceNode;
}
}
public Node getLastNode() {
return parent == null ? null : parent.getCurNode();
}如果context中curEntry不为空并且curEntry.getLastNode()不为空,返回curEntry.getLastNode()。
而curEntry.getLastNode()就是返回curEntry的父节点的curNode。
所以当第一次执行时,会返回entranceNode。这样context的结构如下:
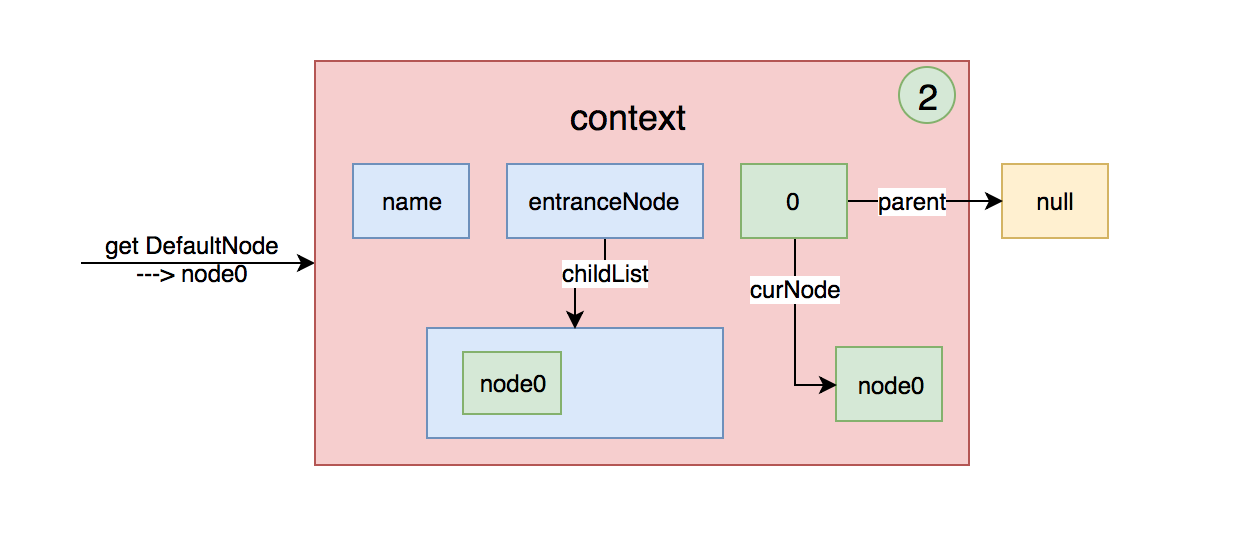
如果在一个context中请求多个资源,第二次执行NodeSelectorSlot,这个时候curEntry.getLastNode()不为空,这个时候context就变成下面这样
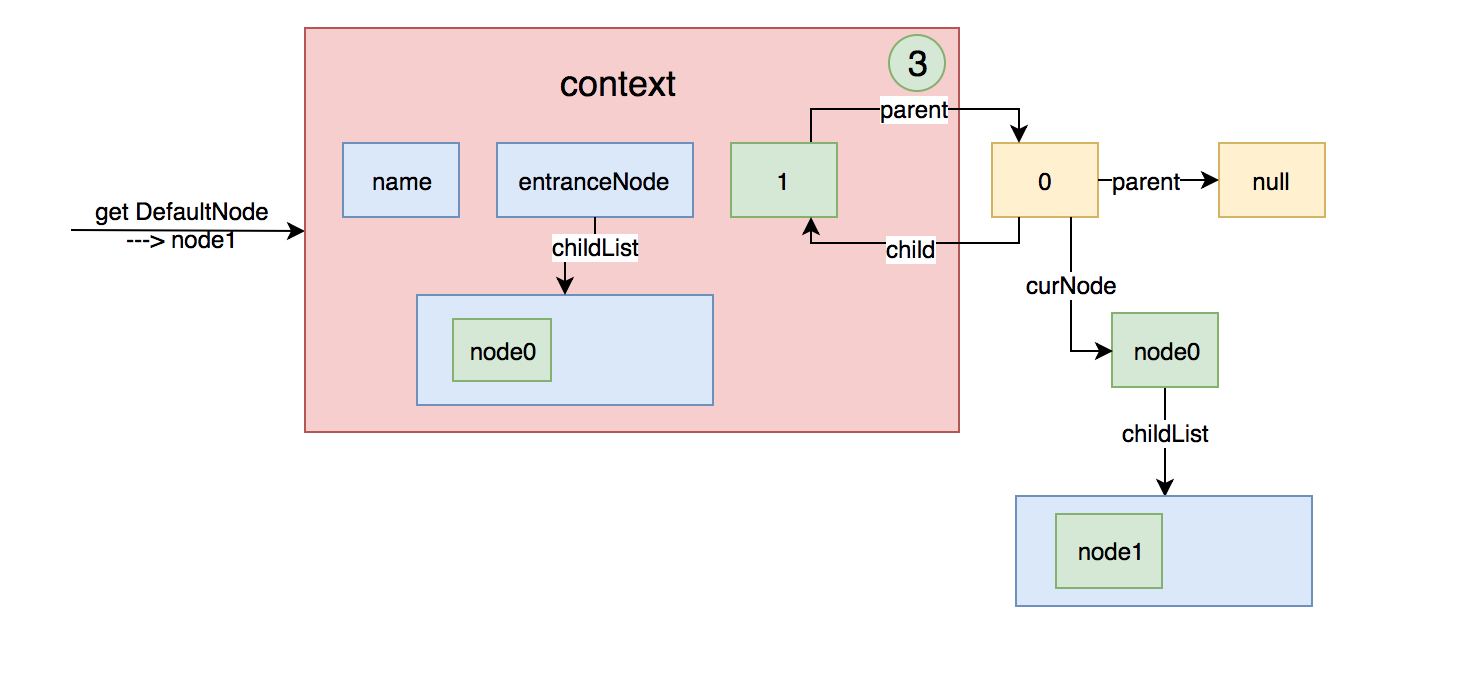
然后将当前node设置给context的curNode,上面的图形就变成下图这样:
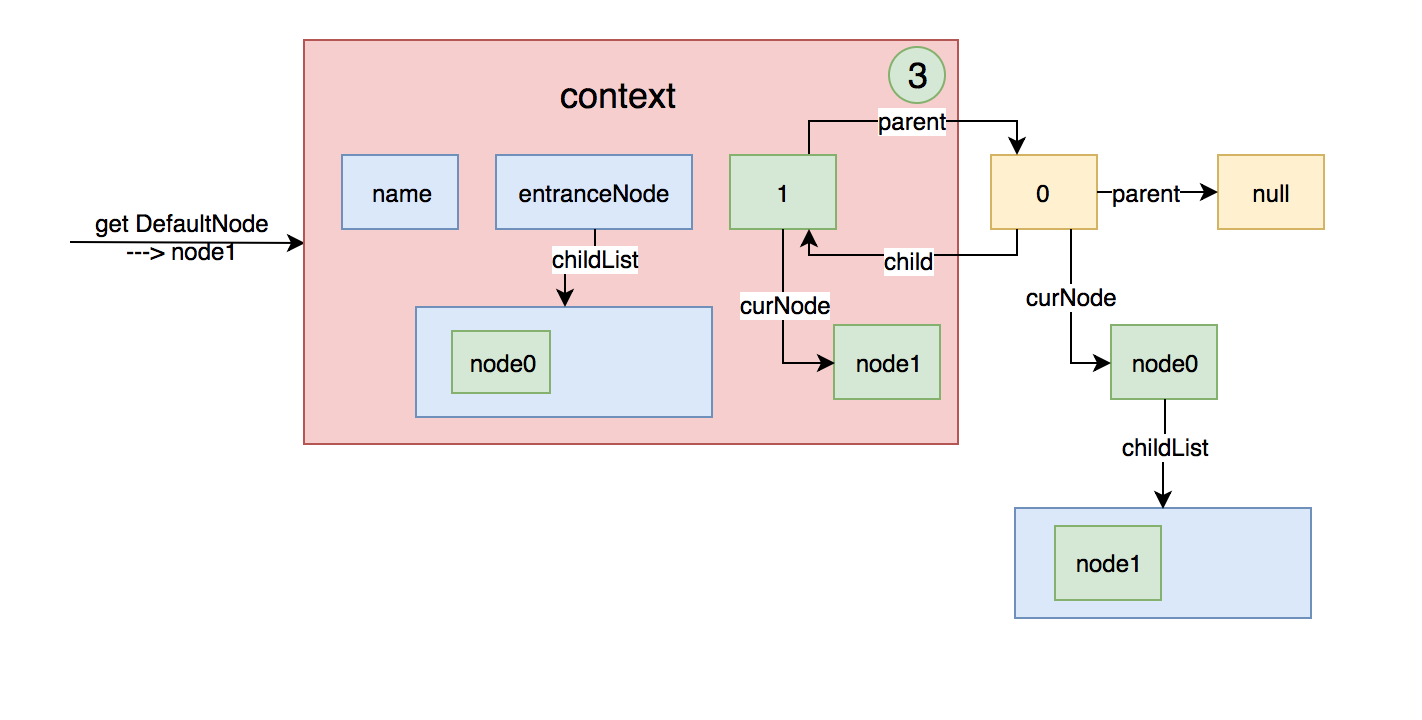
假如再创建一个Entry,然后再进入一次不同的资源名,上面的图就变成下面这样:
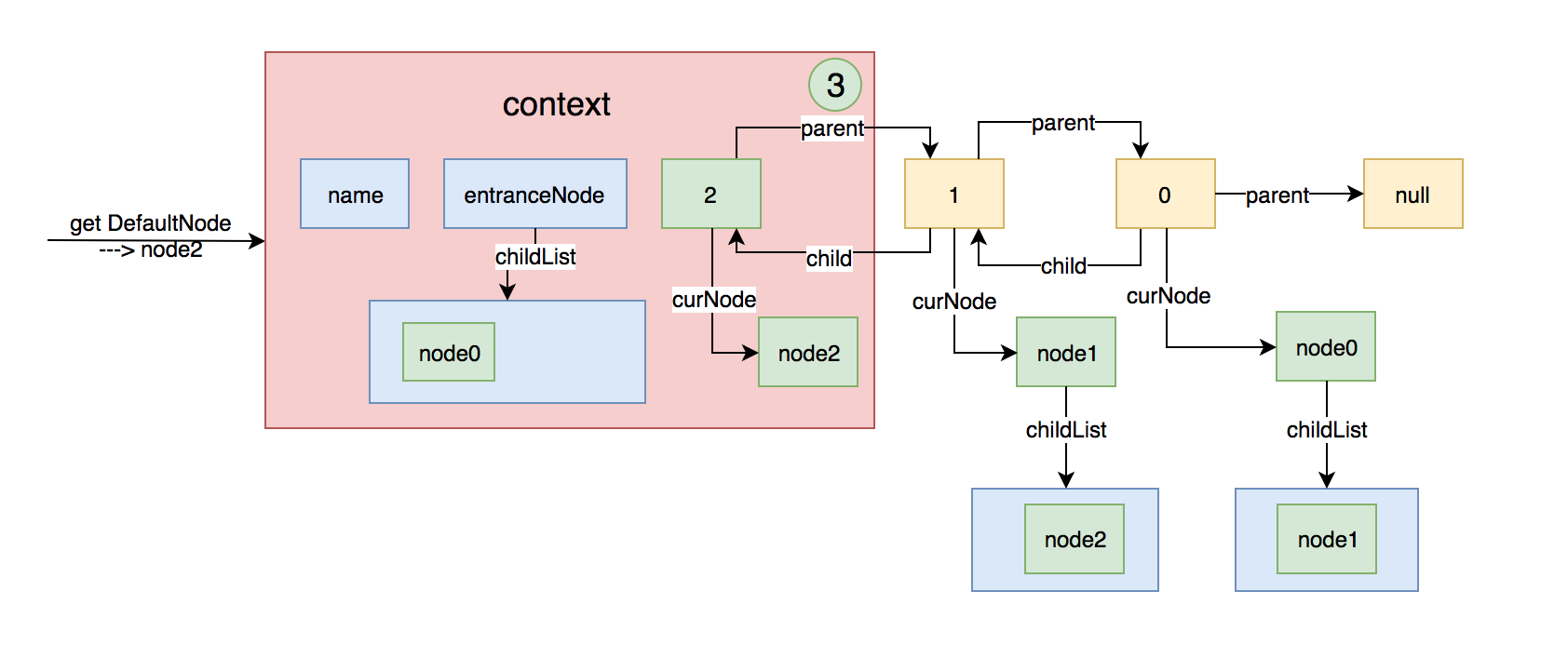
至此NodeSelectorSlot的基本功能已经大致分析清楚了。
PS:以上的分析是基于每次执行SphU.entry(name)时,资源名都是不一样的前提下。如果资源名都一样的话,那么生成的node都相同,则只会再第一次把node加入到entranceNode的子节点中去,其他的时候,只会创建一个新的Entry,然后替换context中的curEntry的值。

















 426
426

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









