






 该文献提出了一种从粗到细的时空信息融合策略,用于提升压缩视频的质量。通过3D卷积和残差块,结合变形卷积网络(DCN)进行特征融合,实现了对视频细节的有效恢复。网络结构包括Coarse Fusion Module、Multi-level Residual Fusion Module和DCN融合模块,旨在改善视频压缩过程中的失真。
该文献提出了一种从粗到细的时空信息融合策略,用于提升压缩视频的质量。通过3D卷积和残差块,结合变形卷积网络(DCN)进行特征融合,实现了对视频细节的有效恢复。网络结构包括Coarse Fusion Module、Multi-level Residual Fusion Module和DCN融合模块,旨在改善视频压缩过程中的失真。
文献《Coarse-to-Fine Spatio-Temporal Information Fusion for Compressed Video Quality Enhancement》
D. Luo, M. Ye, S. Li and X. Li, “Coarse-to-Fine Spatio-Temporal Information Fusion for Compressed Video Quality Enhancement,” in IEEE Signal Processing Letters, vol. 29, pp. 543-547, 2022, doi: 10.1109/LSP.2022.3147441.
问题描述
文中在Bottleneck layer之前将4维度转3伟的操作通过reshape函数或者view函数可以实现。两者效果相同。
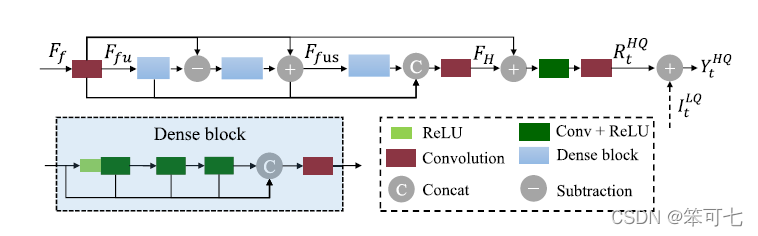
这里的dense bolck的concat前的一个卷积+ReLU的输出是不是画了两条线的输入了?
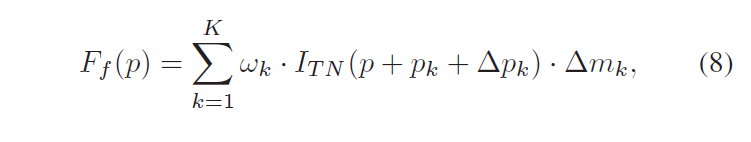
K应该是DCN的核的尺度的平方,3*3的采样点。
网络结构代码
不知道对不对
输入7帧 x = [B, 1, 7, H, W]
import torch
from torch import nn
from nets.ops.dcn.deform_conv import ModulatedDeformConv
class CFM(nn.Module):
def __init__(self):
super(CFM, self).__init__()
self.c3d_input = nn.Sequential(
nn.Conv3d(1, 32, (3, 3, 3), padding=(1, 1, 1)),
nn.ReLU(inplace=True)
)
self.c3d = nn.Sequential(
nn.Conv3d(32, 32, (3, 3, 3), padding=(1, 1, 1)),
nn.ReLU(inplace=True)
)
self.bottleneck = nn.Conv2d(224, 64, 1) # todo reshape [C*T H W]
def forward(self, x):
b, c, t, h, w = x.size()
out = self.c3d(self.c3d_input(x)).view(b, 224, h, w)
# 这里view和reshape函数效果相同,通过debug验证
out = self.bottleneck(out)
return out
class Residual_block(nn.Module):
def __init__(self):
super(Residual_block, self).__init__()
self.conv = nn.Conv2d(64, 64, 3, 1, 1)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
out = self.conv(self.relu(self.conv(x)))
out += x
out = self.relu(out)
return out
class MLRF(nn.Module):
def __init__(self):
super(MLRF, self).__init__()
self.downsample = nn.Sequential(
nn.Conv2d(64, 64, 3, stride=2, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, 3, 1, 1),
nn.ReLU(inplace=True),
)
self.upsample = nn.Sequential(
nn.ConvTranspose2d(64, 64, 4, 2, 1),
# nn.PixelShuffle(2) # todo 亚像素上采样
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, 3, 1, 1),
nn.ReLU(inplace=True),
)
self.residual = Residual_block()
self.conv_relu = nn.Sequential(
nn.Conv2d(64, 64, 3, 1, 1),
nn.ReLU(inplace=True)
)
def forward(self, x):
out_3 = self.residual(self.downsample(self.downsample(x)))
out_2 = self.residual(self.downsample(x) + self.upsample(out_3))
out_1 = self.residual(x + self.upsample(out_2))
out_2 = self.upsample(self.residual(out_2))
out_3 = self.upsample(self.upsample(self.residual(out_3)))
out = self.conv_relu(out_1 + out_2 + out_3)
return out
class DCN_fuse(nn.Module):
def __init__(self, nf, in_nc, out_nc, base_ks, deform_ks):
super(DCN_fuse, self).__init__()
self.size_dk = deform_ks * deform_ks
# regression head
# why in_nc*3*size_dk?
# in_nc: each map use individual offset and mask
# 2*size_dk: 2 coordinates for each point
# 1*size_dk: 1 confidence (attention) score for each point
self.offset = nn.Conv2d(
nf, in_nc * 2 * self.size_dk, base_ks, padding=base_ks // 2
)
self.mask = nn.Conv2d(
nf, in_nc * 1 * self.size_dk, base_ks, padding=base_ks // 2
)
# deformable conv
# notice group=in_nc, i.e., each map use individual offset and mask
self.deform_conv = ModulatedDeformConv(
in_nc, out_nc, deform_ks, padding=deform_ks // 2, deformable_groups=in_nc
)
def forward(self, x, x_original_in):
offsets = self.offset(x)
mask = self.mask(x)
out = self.deform_conv(x_original_in, offsets, mask)
return out
class dense_block(nn.Module):
def __init__(self):
super(dense_block, self).__init__()
self.relu = nn.ReLU(inplace=True)
self.conv = nn.Conv2d(64, 64, 3, 1, 1)
self.conv_cat = nn.Conv2d(256, 64, 3, 1, 1)
def forward(self, x):
out1 = self.relu(self.conv(self.relu(x)))
out2 = self.relu(self.conv(out1))
out3 = self.relu(self.conv(out2))
out = self.conv_cat(torch.cat([out1, out2, out3, x], dim=1))
return out
class RM(nn.Module):
def __init__(self):
super(RM, self).__init__()
self.conv = nn.Conv2d(64, 64, 3, 1, 1)
self.relu = nn.ReLU(inplace=True)
self.dense = dense_block()
self.conv_cat = nn.Conv2d(256, 64, 3, 1, 1)
self.conv_output = nn.Conv2d(64, 1, 3, 1, 1)
def forward(self, x):
out1 = self.conv(x)
out2 = self.dense(out1)
out3 = (self.dense(out1 - out2)) + out1
out4 = self.dense(out3)
out = self.conv_cat(torch.cat([out1, out2, out3, out4], dim=1))
out += out1
out = self.conv_output(self.relu(self.conv(out)))
return out
class CF_STIF(nn.Module):
def __init__(self):
super(CF_STIF, self).__init__()
self.cfm = CFM()
self.mlrf = MLRF()
self.dcn = DCN_fuse(nf=64, in_nc=7, out_nc=64, base_ks=3, deform_ks=3)
self.rm = RM()
def forward(self, x): # todo x = [B, C, T, H, W]
_, _, T, _, _ = x.unsqueeze(1).size()
# Coarse Fusion Module
out = self.cfm(x.unsqueeze(1))
# Multi-level Residual Fusion Module
out = self.mlrf(out)
# DCN
out = self.dcn(out, x)
out = self.rm(out)
out += x[:, [T // 2], ...]
return out


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









