






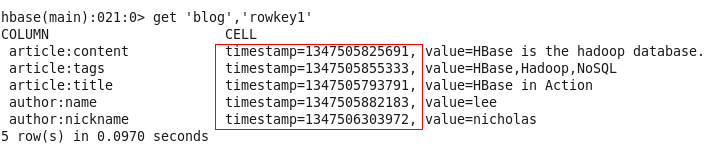
HBase是一个类似于Bigtable的分布式数据库,它是一个稀疏的长期存储的(存在硬盘上)、多维度的、排序的映射表。这张表的索引是行关键字;列关键字和时间戳。HBase中的数据都是字符串,没有类型。
用户在表格中存储数据,每一行都有一个可排序的主键和任意多的列。由于是稀疏存储,所以同一张表里面的每一行数据都可以有截然不同的列。
列名字的格式是"<family>:<qualifier>",都是由字符串组成的。每一张表有一个列族集合,这个集合是固定不变的,只能通过改变表结构来改变,但是qualifier的值相对于每一行来说都是可以改变的。
HBase把同一个列族的数据村住在同一个目录底下,如下图,artile和author分别是两个列族:

HBase所有数据库的更新都有一个时间戳标记,每个更新都是一个新的版本,HBase会保留一定数量的版本,这个值是可以设定的。
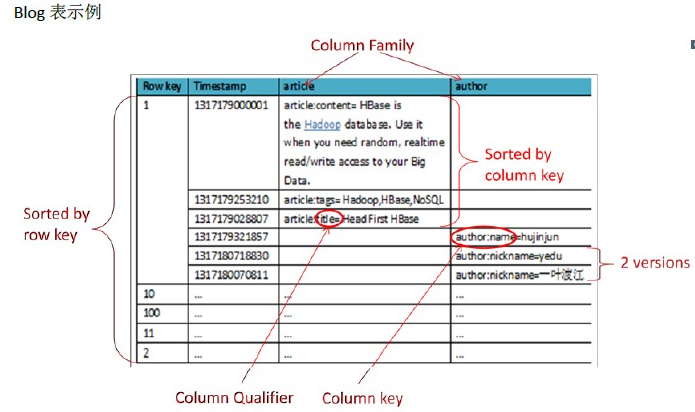
一、概念视图
| RowKey | Time Stamp | Column Family:article | Column Family:author | ||
| 列 | 值 | 列 | 值 | ||
| rowkey1 | t4 | article:title | HBase in Action | author:name | lee |
| t3 | article:content | HBase is the hadoop database. | author:nickname | nicholas | |
| t2 | article:tag | HBase,Hadoop,NoSQL | |||
| rowkey2 | t1 | ... | ... | ... | ... |
如上图所示,blog表有两行数据,rowkey1和rowkey2,并且有两个列族article和author,在第一行数据中,列族article有三条数据,列族author有两条数据,每一条数据对应的时间戳都用数字来标示,编号越大标示数据越旧,反之数据越新。
二、物理视图
虽然从概念视图上来按每个表格是有很多行来组成的,但是在屋里存储上面,它是按照列来保存的,上面的概念视图在物理存储的时候应该表现成下面的样子:
| RowKey | Time Stamp | Column Family:article | |
| 列 | 值 | ||
| rowkey1 | t6 | article:title | HBase in Action |
| t5 | article:content | HBase is the hadoop database. | |
| t4 | article:tag | HBase,Hadoop,NoSQL | |
| RowKey | Time Stamp | Column Family:article | |
| 列 | 值 | ||
| rowkey1 | t3 | author:name | lee |
| t2 | author:nickname | nicholas | |
需要注意的是,在概念视图上的有些列是空白的,这样的列实际不会被存储,当请求这些空白的单元格时,会返回null值。如果在查询的时候不提供时间戳,那么会返回距离现在最近的那一个版本的数据,因为在存储的时候,数据会按照时间戳来排序。
三、HTable的一些基本概念(这一段内容来自http://www.taobaotest.com/blogs/qa?bid=13850)
- Row key
- Column Family(列族)
- Column(列)
- Timestamp
- Value
- 存储类型
- 存储结构
四、HBase与RDBMS
HBase就是这样一个基于列模式的映射数据库,它只能表示很简单的键-数据的映射关系,这大大简化了传统的关系型数据库。与关系型数据库相比,它有如下特点:
1.数据类型:HBase操作只有简单的字符串类型,所有的类型都是交由用户自己处理的,它只保存字符串。而关系型数据库有丰富的类型和存储方式。
2.数据操作:HBase只有很简单的插入,查询,删除,清空等操作,表和表之间是分离的,没有复杂的表和表之间的关系,所以不能也没有必要实现表和表之间的关联等,而关系型数据库通常有各种各样的函数,连接操作。
3.存储模式:HBase是基于列存储的,每个列族都有几个文件保存,不同列族的文件是分离的。传统的关系数据库是基于表格结构和行模式保存的。
4.数据维护:确切的来说,HBase的更新操作应该不叫更新,虽然一个主键或列会对应新的版本,但它的旧版本依然会保留,所以它实际是插入了新数据,而不是传统关系型数据库里面的替换修改。
5.可伸缩性:HBase这类分布式数据库就是为了这个目的而开发出来的,所以它能够轻易的增加或者减少硬件数量,并且对错误的兼容性比较高,而传功关系型数据库通常需要增加中间层才能实现类似的功能。

















 1706
1706

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









