







1.内存溢出和内存泄露的区别
1、内存泄漏memory leak :是指程序在申请内存后,无法释放已申请的内存空间,一次内存泄漏似乎不会有大的影响,但内存泄漏堆积后的后果就是内存溢出。
2、内存溢出 out of memory :指程序申请内存时,没有足够的内存供申请者使用,或者说,给了你一块存储int类型数据的存储空间,但是你却存储long类型的数据,那么结果就是内存不够用,此时就会报错OOM,即所谓的内存溢出。
内存溢出原因:
1.内存中加载的数据量过于庞大,如一次从数据库取出过多数据;
2.集合类中有对对象的引用,使用完后未清空,使得JVM不能回收;
3.代码中存在死循环或循环产生过多重复的对象实体;
4.使用的第三方软件中的BUG;
5.启动参数内存值设定的过小
内存溢出的解决方案:
第一步,修改JVM启动参数,直接增加内存。(-Xms,-Xmx参数一定不要忘记加。)
第二步,检查错误日志,查看“OutOfMemory”错误前是否有其 它异常或错误。
第三步,对代码进行走查和分析,找出可能发生内存溢出的位置。
2.spring的Aop中的前置通知,后置通知以及环绕通知,异常通知,还有返回通知,引介通知。
3.三次握手,两次可以吗?
第一次握手:建立连接时,客户端发送syn包(seq=j)到服务器,并进入SYN_SENT状态,等待服务器确认;SYN:同步序列编号(Synchronize Sequence Numbers)。
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(seq=k),即SYN+ACK包,此时服务器进入SYN_RECV状态。
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED(TCP连接成功)状态,完成三次握手。
假设每次数据都丢失,客户端会一直发送syn,服务器就会产生多个无效的连接,占用资源,服务器可能挂掉,这个现象就是“syn的洪水冲击”。第三次握手是为了防止:如果客户端迟迟没有收到服务器返回确认报文,这时会放弃连接,重启一条连接请求。
4.抽象类和接口都有什么区别?
接口和抽象类都是继承树的上层,他们的共同点如下:
1) 都是上层的抽象层。
2) 都不能被实例化
3) 都能包含抽象的方法,这些抽象的方法用于描述类具备的功能,但是不比提供具体的实现。
他们的区别如下:
1) 在抽象类中可以写非抽象的方法,从而避免在子类中重复书写他们,这样可以提高代码的复用性,这是抽象类的优势;接口中只能有抽象的方法。
2) 一个类只能继承一个直接父类,这个父类可以是具体的类也可是抽象类;但是一个类可以实现多个接口。
5.事务的四种特性
原子性、一致性、隔离性、持久性

6.spring的生命周期
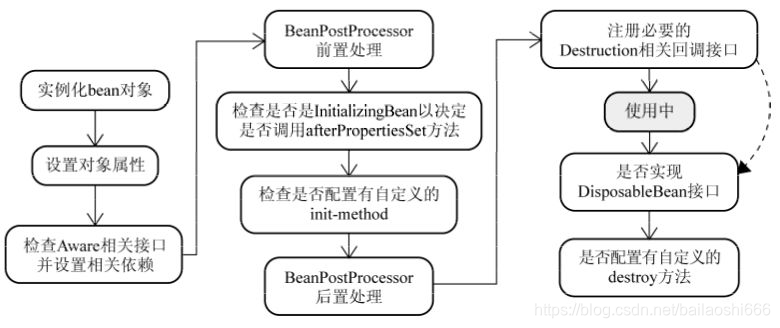
这里具体看看知乎答案,这里还得学习
https://www.zhihu.com/question/38597960
还有ioc容器的流程,resource定位,xml属性装载,注册进容器(hashmap)
7.垃圾回收
四种 GC 垃圾回收算法
- 引用计数
- 复制回收
- 标记清除
- 标记整理
- 串行垃圾回收器(Serial)
- 它为单线程环境设计且只使用一个线程进行垃圾回收,会暂停所有的用户线程,所以不适合服务环境。
- 并行垃圾回收器(Parallel)
- 多个垃圾收集线程并行工作,此时用户线程是暂停的,用于科学计算、大数据处理等弱交互场景。
- 并发垃圾回收器(CMS)
- 用户线程和垃圾收集线程同时执行(不一定是并行,可能是交替执行),不需要停顿用户线程,互联网公司多用它,适用对相应时间有要求的场景。
- G1 垃圾回收器
- G1 垃圾回收器将堆内存分割成不同的区域然后并发的对其进行垃圾回收。
8.为什么redis快
1.Redis是基于内存存储的,MySQL是基于磁盘存储的
2.Redis存储的是k-v格式的数据。时间复杂度是O(1),常数阶,而MySQL引擎的底层实现是B+Tree,时间复杂度是O(logn),对数阶。Redis会比MySQL快一点点。
3.MySQL数据存储是存储在表中,查找数据时要先对表进行全局扫描或者根据索引查找,这涉及到磁盘的查找,磁盘查找如果是按条点查找可能会快点,但是顺序查找就比较慢;而Redis不用这么麻烦,本身就是存储在内存中,会根据数据在内存的位置直接取出。
4.Redis是单线程的多路复用IO,单线程避免了线程切换的开销,而多路复用IO避免了IO等待的开销,在多核处理器下提高处理器的使用效率可以对数据进行分区,然后每个处理器处理不同的数据。
- String:缓存、限流、计数器、分布式锁、分布式Session
- Hash:存储用户信息、用户主页访问量、组合查询
- List:微博关注人时间轴列表、简单队列
- Set:赞、踩、标签、好友关系
- Zset:排行榜

















 1429
1429

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









