







 本文分析了一篇关于使用LSTM预测道路速度的论文,数据涵盖一年中每五分钟的道路速度记录。作者定义了Traffic Graph Convolution Filter,并在Models.py中实现了RNN、LSTM以及自定义的GraphConvolutionalLSTM。Main.py负责数据预处理,而Train_Validate.py用于训练和验证模型。
本文分析了一篇关于使用LSTM预测道路速度的论文,数据涵盖一年中每五分钟的道路速度记录。作者定义了Traffic Graph Convolution Filter,并在Models.py中实现了RNN、LSTM以及自定义的GraphConvolutionalLSTM。Main.py负责数据预处理,而Train_Validate.py用于训练和验证模型。
问题:
- 在给定一个区域(包含323条道路)在一年的速度数据,用这些数据,提出一个模型,要求用这个模型预测某一道路在短时间内的速度。
1. 先分析数据:
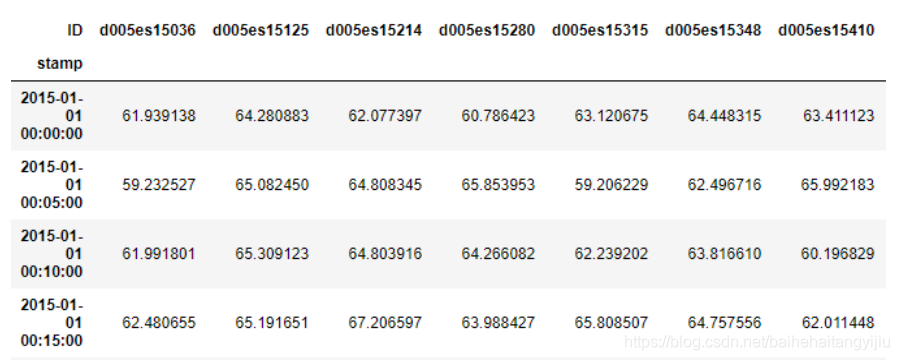
数据:每一行代表:全部道路在时刻i的速度
道路323条; 时间:2015.01.01 - 2015.12.31每五分钟为一个时间戳(32560)
转换为矩阵:(32560, 323)
 作者规定batch_size = 40, 提出的LTSM的time_deep = 10,在Main.py里面有定义。
作者规定batch_size = 40, 提出的LTSM的time_deep = 10,在Main.py里面有定义。
转换为RNN的输入:input_X = (40, 10, 323) = (batch_size, time_deep, num_features)
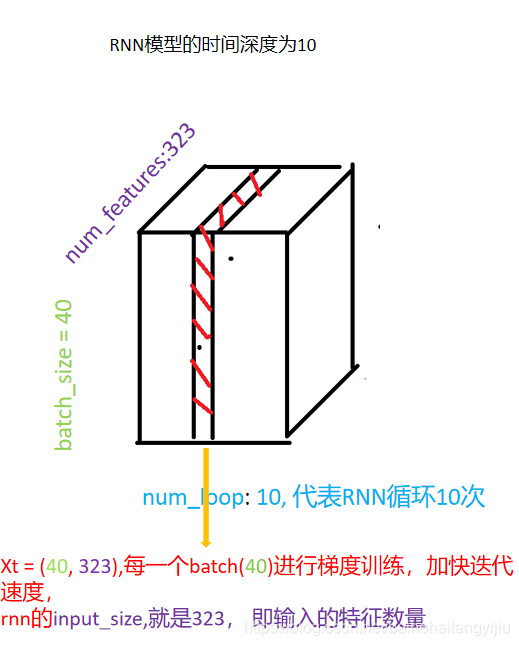
抛开batch_size, 每一个X, 代表一个时刻i,特征是全部道路在这个时刻的速度
代码分为四个部分:
- 1.Mudules.py – 作者自定义的Traffic Graph Convolution的Filter,即与输入相卷积的卷积函数,包括变量卷积核和每层的参数。
- 2.Models.py – RNN,LSTM,GraphConvolutionalLSTM函数
- 3.main.py – 训练数据的主函数
- 4.Train_Validate.py – 训练模型,验证模型的函数
1. Mudules.py
– 作者自定义的Traffic Graph Convolution的Filter,即与输入相卷积的卷积函数,包括变量卷积核和每层要学习的参数。
因为作者自定义了一个Traffic Graph Convolution,所以他要自定义一个过滤器Filter,也就需要自定义一个线性函数。
- 为其指定变量,相当于卷积核: self.filter_square_matrix = Variable(filter_square_matrix, requires_grad=False),变量和输入的矩阵相卷积;
- 指定学习的参数,在向前向后传播中不断更新:self.weight = Parameter(torch.Tensor(out_features, in_features))。
import torch.nn.functional as F
import torch
import torch.nn as nn
from torch.autograd import Variable
from torch.nn.parameter import Parameter
import math
class FilterLinear(nn.Module):
def __init__(self, in_features, out_features, filter_square_matrix, bias=True):
'''
filter_square_matrix : filter square matrix, whose each elements is 0 or 1. 这里的filter_square_matrix是先计算好的,再传进来,与图矩阵进行卷积
'''
super(FilterLinear, self).__init__()
self.in_features = in_features
self.out_features = out_features
use_gpu = torch.cuda.is_available()
self.filter_square_matrix = None
if use_gpu:
self.filter_square_matrix = Variable(filter_square_matrix.cuda(), requires_grad=False)
else:
self.filter_square_matrix = Variable(filter_square_matrix, requires_grad=False) # 与输入相卷积的卷积核
self.weight = Parameter(torch.Tensor(out_features, in_features)) # 向前向后传播的要学习的参数
if bias:
self.bias = Parameter(torch.Tensor(out_features))
else:
self.register_parameter('bias', None)
self.reset_parameters()
def reset_parameters(self):
stdv = 1. / math.sqrt(self.weight.size(1))
self.weight.data.uniform_(-stdv, stdv) # 标准化参数,加快迭代速度
if self.bias is not None:
self.bias.data.uniform_(-stdv, stdv)
# print(self.weight.data)
# print(self.bias.data)
def forward(self, input):
return F.linear(input, self.filter_square_matrix.matmul(self.weight), self.bias)
def __repr__(self):
return self.__class__.__name__ + '(' \
+ 'in_features=' + str(self.in_features) \
+ ', out_features=' + str(self.out_features) \
+ ', bias=' + str(self.bias is not None) + ')'
2. Models.py
– RNN,LSTM,GraphConvolutionalLSTM函数
这里附上pytorch简单实现的代码
- 先来看一个特别简单的RNN:
rnn = torch.nn.RNN(20,50,2) # (input的特征数量,RNN单元size,RNN层数)
input = torch.randn(100 , 32 , 20) # (batch_size, RNN时间深度, 特征数量)
h_0 =torch.randn(2 , 32 , 50)
output,hn=rnn(input ,h_0)
print(output.size(),hn.size())
- 作者自己继承nn.Module实现的RNN
import torch.nn.functional as F
import torch
import torch.nn as nn
from torch.autograd import Variable
from torch.nn.parameter import Parameter
from Modules import FilterLinear
import math
import numpy as np
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(RNN, self).__init__()
self.hidden_size = hidden_size
self.i2h = nn.Linear(input_size + hidden_size, hidden_size)
self.i2o = nn.Linear(input_size + hidden_size, output_size)
def forward(self, input, hidden):
combined = torch.cat((input, hidden), 1)
# print(combined)
hidden = self.i2h(combined)
output = self.i2o(combined)
return output, hidden
def initHidden(self, batch_size):
use_gpu = torch.cuda.is_available()
if use_gpu:
return Variable(torch.zeros(batch_size, self.hidden_size).cuda())
else:
return Variable(torch.zeros(batch_size, self.hidden_size))
- 先来看一个特别简单的LSTM
lstm = torch.nn.LSTM(10, 20,2) # (input的特征数量,RNN单元size,RNN层数)
input = torch.randn(5, 3, 10) # (batch_size, RNN时间深度, 特征数量)
h0 =torch.randn(2, 3, 20)
c0 = torch.randn(2, 3, 20)
output, hn = lstm(input, (h0, c0))
print(output.size(),hn[0].size(),hn[1].size())
- 作者自己继承nn.Module实现的LSTM
class LSTM(nn.Module):
def __init__(self, input_size, cell_size, hidden_size):
"""
cell_size is the size of cell_state.
hidden_size is the size of hidden_state, or say the output_state of each step
"""
super(LSTM, self).__init__()
self.cell_size = cell_size
self.hidden_size = hidden_size
self.fl = nn.Linear(input_size + hidden_size, hidden_size)
self.il = nn.Linear(input_size + hidden_size, hidden_size)
self.ol = nn.Linear(input_size + hidden_size, hidden_size)
self.Cl = nn.Linear(input_size + hidden_size, hidden_size)
def forward(self, input, Hidden_State, Cell_State):
combined = torch.cat((input, Hidden_State), 1)
f = F.sigmoid(self.fl(combined))
i = F.sigmoid(self.il(combined))
o = F.sigmoid(self.ol(combined))
C = F.tanh(self.Cl(combined))
Cell_State = f * Cell_State + i * C
Hidden_State = o * F.tanh(Cell_State)
return Hidden_State, Cell_State
# RNN时间深度,loop的次数,即时间循环的次数,更新Hidden_State, Cell_State,
def loop(self, inputs):
batch_size = inputs.size(0)
time_step = inputs.size(1)
Hidden_State, Cell_State = self.initHidden(batch_size)
for i in range(time_step):
Hidden_State, Cell_State = self.forward(torch.squeeze(inputs[:,i:i+1,:]), Hidden_State, Cell_State)
# inputs[:,i:i+1,:], input = (batch_size, RNN时间深度, 特征数量), 所以刚好取时间深度的一个时间
return Hidden_State, Cell_State
def initHidden(self, batch_size):
use_gpu = torch.cuda.is_available()
if use_gpu:
Hidden_State = Variable(torch.zeros(batch_size, self.hidden_size).cuda())
Cell_State = Variable(torch.zeros(batch_size, self.hidden_size).cuda())
return Hidden_State, Cell_State
else:
Hidden_State = Variable(torch.zeros(batch_size, self.hidden_size))
Cell_State = Variable(torch.zeros(batch_size, self.hidden_size))
return Hidden_State, Cell_State
- 作者自己定义的GraphConvolutionalLSTM:
# 作者自己定义的GraphConvolutionalLSTM
class GraphConvolutionalLSTM(nn.Module):
def __init__(self, K, A, FFR, feature_size, Clamp_A=True):
'''
Args:
K: K-hop graph 文中为3
A: adjacency matrix
FFR: free-flow reachability matrix
feature_size: the dimension of features
Clamp_A: Boolean value, clamping all elements of A between 0. to 1.
'''
super(GraphConvolutionalLSTM, self).__init__()
self.feature_size = feature_size
self.hidden_size = feature_size
self.K = K
self.A_list = [] # Adjacency Matrix List 用来装载不同K的A
A = torch.FloatTensor(A)
A_temp = torch.eye(feature_size,feature_size)
# 生成不同K的A,
for i in range(K):
A_temp = torch.matmul(A_temp, torch.Tensor(A)) # 这里是乘积
if Clamp_A:
# confine elements of A
A_temp = torch.clamp(A_temp, max = 1.)
self.A_list.append(torch.mul(A_temp, torch.Tensor(FFR)))
# self.A_list.append(A_temp)
# a length adjustable Module List for hosting all graph convolutions
self.gc_list = nn.ModuleList([FilterLinear(feature_size, feature_size, self.A_list[i], bias=False) for i in range(K)] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









