







添加了执行多句SQL这个功能后,就解锁了更多数据拉取方式。但是这仍然不够,有时候我们想用pandas和numpy处理数据,有时候甚至想用pytorch这种人工智能的方式处理数据,那么仅仅依靠SQL是远不够的,所以必须想想如何在拉取数据与展示数据之间添加一个python数据处理层。
我的想法是这样的:
输入端
输入端就是查询界面书写SQL脚本的地方,但是现在我暂时不在这里写SQL了,而是一种JSON格式的键值对
${
"cmd":"funcname",
"start_date":"{{开始日期}}",
"end_date":"{{结束日期}}",
"shop":"A店",
"code":123456
}
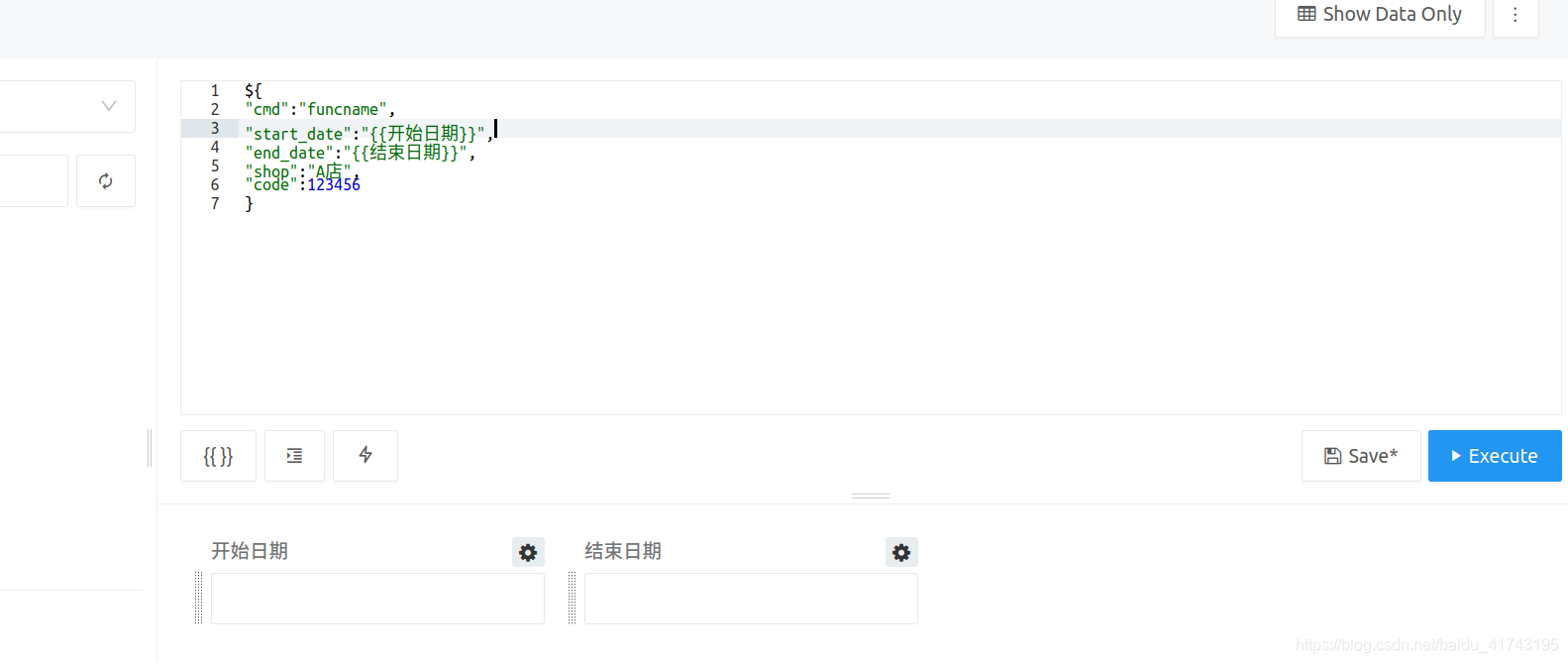
注意{{}}之中的是用户输入的数据,这和普通SQL查询的方法是一样的,也就是说,这种写法并不影响参数传递!我举的例子中,除了"cmd"项外都是函数的参数,有的是写死的,有的需要用户输入,"cmd"项就是我需要调用的函数名,负责接收其他的参数,并返回查询结果。$则作为一个特殊的字符,后台读取到以这个字符开头的字段就知道这次输入的不是一个正常的SQL查询,而需要调用本地的python函数。
服务端
服务端的处理仍在文件query_runner/mysql.py中,上次我修改了这个文件使其可以执行多句SQL。仍然是函数_run_query(),它负责执行查询。
if query[0] == '$':
# 如果第一个字符为$,进入命令转发模式
para_dict = json.loads(query[1:])
df_res = process_command(connection, para_dict)
if df_res.empty:
r.json_data = None
r.error = "没有数据返回..."
ev.set()
return None
columns = self.fetch_columns(
[(col_name, df_types_map.get(str(df_res[col_name].dtype), None)) for col_name in df_res.columns]
)
rows = [
dict(zip((column["name"] for column in columns), tuple(df_res.loc[row_index])))
for row_index in df_res.index
]
data = {"columns": columns, "rows": rows}
r.json_data = json_dumps(data)
r.error = None
ev.set()
return None
关键点:
- 仿照原函数的处理方法处理返回数据,将DataFrame转化为一个JSON格式,这样才可以通过flask转发给前端网页展示
- df_types_map.get 也是仿照原函数的写法,对DataFrame进行数据类型转化,目标是JSON可正常识别,尤其注意DataFrame的NaN类型JSON是不接受的! 需要转换成0或None
- 使用json_loads将字符串转化为参数字典,作为输入与
conn一起传递给process_command函数,在process_command函数中将参数cmd解析出来,再决定调用哪个函数处理,即process_command相当于一个中转站
最后只要编写处理函数,并注册到process_command中即可,这样一来数据处理的自由度就很高啦,调用人工智能接口、复用以前写的python脚本都是小意思,甚至可以做一些查询之外的事情,比如一旦某个特定的查询被执行后,调用发邮件函数,十分灵活。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









