






写在前面:在数据挖掘领域中,隐私保护问题是普遍存在且难以根除。为此,学者们提出一个新的研究领域 privacy-preserving data mining (PPDM),通过修改源数据库,降低隐私信息在衡量标准中的真实值是其中一种解决办法。另一方面,高效用项集挖掘(high-utility itemset mining,HUIM)在近些年也取得充分的发展。这为研究 PPDM 提供了一种捷径,学者们提出一个子领域 privacy-preserving utility mining (PPUM) ,本文要介绍的算法对当前 PPUM 领域存在的精度问题而提出了一些改进方案。 ———— By Suarne
A novel algorithm for privacy preserving utility mining based on integer linear programming
动机
当前的 PPUM 算法在处理隐私信息过程中,仅仅通过降低隐私信息的效用值所带来的精度其实是不够的,也就是说,仍然存在不少隐私信息是能被挖掘。当前这些算法采用启发式思想,试图将敏感信息从数据库中直接删除或者降低其某个数值为 0。这样得到的结果只是局部最优,从整体上来看并没有达成很好的开支平衡,并且会进一步干扰到其它非敏感信息的真实值,从而降低了整体挖掘结果的可靠性
定义
效用值(utility)相关定义可以参考 HUI-Miner 和 EFIM 等笔记,本文仅作补充
- 整数线性规划(integer linear programming ):在一组线性约束条件的限制下,且所有涉及变量均为整数,求一线性目标函数最大或最小的问题
- 敏感高效用项集(sensitive high-utility itemset,SHUI):用户给定的特殊项集,作为本算法的输入参数 ISI_SIS,用 sis_isi 表示其组成元素
- 敏感高效用项集表(SHI-table):用来记录哪些交易项集包含这些敏感高效用项集,由一个至多个元组(<sis_isi, TIDsTIDsTIDs>,si←{Tj∣si⊆Tj∧Tj∈D}s_i \leftarrow \{T_j \mid s_i \subseteq T_j \land T_j \in \mathcal{D}\}si←{Tj∣si⊆Tj∧Tj∈D})构成的列表,其中 TIDsTIDsTIDs 是一个由交易项集构成的集合
- 非敏感高效用项集(non-sensitive high-utility itemset,NSHUI):在所有的高效用项集中,与敏感项集集合互相对立的自然是非敏感高效用项集集合 INI_NIN,用 nin_ini 表示其组成元素
- 非敏感高效用项集表(NHI-table):用来记录哪些交易项集包含这些非敏感高效用项集,由一个至多个元组(<nin_ini, TIDsTIDsTIDs>,ni←{Tj∣ni⊆Tj∧Tj∈D}n_i \leftarrow \{T_j \mid n_i \subseteq T_j \land T_j \in \mathcal{D}\}ni←{Tj∣ni⊆Tj∧Tj∈D})构成的列表,其中 TIDsTIDsTIDs 是一个由交易项集构成的集合
理想状况下,隐藏 ISI_SIS 与计算 INI_NIN 相互独立。实际上,存在项集 {AB}∈IS\{AB\} \in I_S{AB}∈IS 但 {A},{B}∈IN\{A\},\{B\} \in I_N{A},{B}∈IN 这类情况,所以,在隐藏 ISI_SIS 的过程中,必然会干扰到对 INI_NIN 的计算。为此,作者提出一系列概念来尽可能准确地衡量算法的运行效果:
Ps. 这里给出一份符号解释表格,用以辅助后文的理解
| 符号名 | 解释 |
|---|---|
| D\mathcal{D}D | 源数据库/集 |
| D′\mathcal{D}^\primeD′ | 经过 PPUM 算法处理后的数据库/集 |
| IHI_HIH | 在 D\mathcal{D}D 上挖掘得到的高效用项集集合 |
| IH′I_{H}^{\prime}IH′ | 在 D′\mathcal{D}^\primeD′ 上挖掘得到的高效用项集集合 |
| ISI_SIS | 敏感高效用项集组成的项集合,需要用户预先给定 |
| INI_NIN | 非敏感高效用项集组成的集合,与 ISI_SIS 共同组合成 IHI_HIH |
-
隐匿失效(hiding failure):在修改后的数据库 D′D^\primeD′ 中,原本是 ISI_SIS 中的元素仍然可以作为 HUIs 被挖掘,用 α\alphaα = ∣IS∩IH′∣∣IS∣\frac{\mid I_S \cap I_{H}^{\prime} \mid}{\mid I_S \mid}∣IS∣∣IS∩IH′∣ 表示本不应该存在 D′D^\primeD′ 中 sis_isi 在 ISI_SIS 的占比情况* 丢失成本(missing cost):在源数据库 D\mathcal{D}D 中是非敏感高效用项集,但由于对 ISI_SIS 的处理,导致其效用值在修改后的数据库 D′\mathcal{D}^\primeD′ 中降低以至于变成低效用项集,使用 β\betaβ = ∣IN−IN∩IH′∣IN∣\frac{\mid I_N - I_N \cap I_{H}^{\prime}}{\mid I_N \mid}∣IN∣∣IN−IN∩IH′ 表示在 D′\mathcal{D}^\primeD′ 中成为低效用项集在 INI_NIN 的占比情况* 人为成本(artificial cost):在源数据库 D\mathcal{D}D 中是非敏感低效用项集,但由于对 ISI_SIS 的处理变成了新的高效用项集,使用 γ\gammaγ = ∣IH′−IN∩IH′∣∣IN∣\frac{\mid I_{H}^{\prime} - I_N \cap I_{H}^{\prime} \mid}{\mid I_N \mid}∣IN∣∣IH′−IN∩IH′∣ 表示在 D′\mathcal{D}^\primeD′ 中成为新的非敏感高效用项集在 INI_NIN 中的占比情况下图提供了 hiding failure,missing cost 和 artificial cost 三者之间的关系,理想状况下,INI_NIN = IH′I_{H}^{\prime}IH′ 即 α\alphaα = β\betaβ = γ\gammaγ = 0
-
过滤机制(filter mechanism):设 g(X)g(X)g(X) = {Tj∣X⊆Tj∧Tj∈D}\{T_j \mid X \subseteq T_j \land T_j \in \mathcal{D}\}{Tj∣X⊆Tj∧Tj∈D},在源数据库 D\mathcal{D}D 得到 ISI_SIS 和 INI_NIN,对于 ∀ni∈IN\forall n_i \in I_N∀ni∈IN,当其满足以下任意一个条件则不能从 INI_NIN 中被过滤:* ni∩si≠∅n_i \cap s_i \not= \emptysetni∩si=∅* g(ni)∩g(si)≠∅g(n_i) \cap g(s_i) \not= \emptysetg(ni)∩g(si)=∅使用这两个条件来确保处理涉及到的项集必然与 ISI_SIS 有关联,作者将过滤后得到的 NHI-table 重新命名为 IN′I_{N}^{\prime}IN′ 以作区别。_(Ps. 个人人为这个条件仍是过于宽泛,比如每条交易项集特别地长,抑或项太少?不过作者在文中也指明数据库本身的特征对算法运行效率影响很大)_由于效用值计算本身涉及多方面,显而易见的是,在处理数据库的过程中非敏感高效用项集必然会出现一些信息丢失的情况(如效用值降低)。因此,有必要将这些关键项集找出来,提前处理,尽可能减少对后续处理的干扰程度
-
高效用闭包项集(high-utility closed itemset,HUCI):给定一个高效用项集 XXX,当其任意超集 YYY (不一定是高效用项集)都有 g(X)≠g(Y)g(X) \not= g(Y)g(X)=g(Y),那么可以认为该项集是闭包的
-
必然丢失项集(bound-to-lose itemset):给定 ISI_SIS 和 IN′I_{N}^{\prime}IN′,对 ∀ni′∈IN′\forall n_{i}^{\prime} \in I_{N}^{\prime}∀ni′∈IN′,不存在 sis_isi 能够还原 ni′n_{i}^{\prime}ni′,那么 ni′n_{i}^{\prime}ni′ 必然会在处理过程中丢失(低效用)。因为如果项集 XXX 不闭包于 YYY,那么必然有 u(X)<u(Y)u(X) < u(Y)u(X)<u(Y)(g(X)=g(Y)g(X) = g(Y)g(X)=g(Y) 且 YYY 比 XXX 长),证明过程详见论文
以上处理过程通过扫描 NHI-table 即可实现,作者将删除掉必然丢失项集后的 NHI-table 重新命名为 IN′′I_{N}^{\prime\prime}IN′′ 以作区别。至此,IN′′I_{N}^{\prime\prime}IN′′ 中的剩余项集和 ISI_SIS 是高度关联的。为了进一步精简 NHI-table 大小,再次使用闭包思路,对 IN′′I_{N}^{\prime\prime}IN′′ 中的元素进行处理,即如果项集 ni′′n_{i}^{\prime\prime}ni′′ 不闭包于 nj′′n_{j}^{\prime\prime}nj′′,那么 nj′′n_{j}^{\prime\prime}nj′′ 是可以从 IN′′I_{N}^{\prime\prime}IN′′ 中安全地删除
-
精简高效用项集(restricted high-utility itemset,RHUI):IN′′I_{N}^{\prime\prime}IN′′ 中的元素,用 IRI_RIR 表示。通过以上定义,最终可以得到下图:
-
对于要调整的项 xix_ixi 的内部效用值 vij∈Uv_{ij} \in Uvij∈U,当 xi∈si⊆Tjx_i \in s_i \subseteq T_jxi∈si⊆Tj 时,用 uiju_{ij}uij 表示调整后的值,其他情况仍然使用其原值 tijt_{ij}tij。那么可以得到新的项集效用值计算公式 ∑X⊆Tj∧Tj∈D∑xi∈X(vij×Ex(xi))\sum_{X \subseteq T_j \land T_j \in \mathcal{D}}\sum_{x_i \in X}(v_{ij} \times Ex(x_i))∑X⊆Tj∧Tj∈D∑xi∈X(vij×Ex(xi)),其中 Ex(xi)Ex(x_i)Ex(xi) 指的是 xix_ixi 的 external utility (如 单价)。显然,对于 INI_NIN 中的项集按照该公式计算必然是要大于或等于给定的阈值,对于 ISI_SIS 和本来就是低效用的项集按照该公式计算必然时要小于给定的阈值
-
总结起来,论文提出的 CSP 模型可以公式化如下:* 目的:取 _min_∑vij∈Uuij\sum_{v_{ij} \in U}u_{ij}∑vij∈Uuij* ∑X⊆Tj∧Tj∈D∑xi∈X(vij×Ex(xi))<δ\sum_{X \subseteq T_j \land T_j \in \mathcal{D}}\sum_{x_i \in X}(v_{ij} \times Ex(x_i)) < \delta∑X⊆Tj∧Tj∈D∑xi∈X(vij×Ex(xi))<δ,∀X∈IS\forall X \in I_S∀X∈IS* ∑X⊆Tj∧Tj∈D∑xi∈X(vij×Ex(xi))≥δ\sum_{X \subseteq T_j \land T_j \in \mathcal{D}}\sum_{x_i \in X}(v_{ij} \times Ex(x_i)) \ge \delta∑X⊆Tj∧Tj∈D∑xi∈X(vij×Ex(xi))≥δ,∀X∈IR\forall X \in I_R∀X∈IR* uij≥1u_{ij} \ge 1uij≥1,∀uij∈U\forall u_{ij} \in U∀uij∈U
-
特别地,论文在设计算法中出于成本的考量,算法对 IRI_RIR 进行有选择地删减,比如添加项集的长度限制等(因为越长的项越容易涉及敏感高效用项集)
伪代码
算法大致流程如下:输入原始数据库/集 →\rightarrow→ 构造表 →\rightarrow→ 预处理 →\rightarrow→ 使用约束模型 →\rightarrow→ 得到扰动后的数据库/集
Table constructions
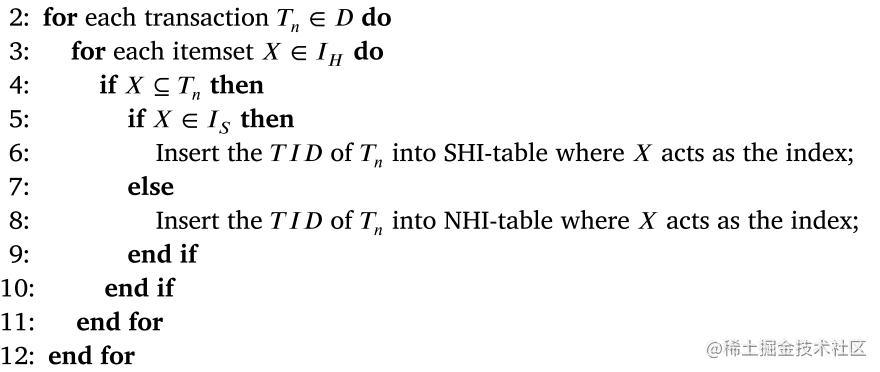
Pre-processing

CSP formulation

总结
个人认为,使用整数线性规划去寻找全局最优解是本文的最大亮点,其次是提出的 CSP 模型,将隐藏项集问题转化成容易计算的内部效用值调整问题。实验结果表明,新算法在隐藏效果上表现尤为突出,即便在开支上表现不是最优。越是稀疏的数据集,隐藏效果越好。原因也很简单,敏感项集和非敏感项集的交叉会更小。在闭包项集方面,个人认为还是有讨论的空间,比如为什么不设定 g(X)⊈g(Y)g(X) \not\subseteq g(Y)g(X)⊆g(Y) 这类条件作为闭包的判断依据?预处理的第三个步骤,为什么可以在没有任何 丢失成本(missing cost) 的情况下对 IN′′I_{N}^{\prime\prime}IN′′ 的元素进行闭包删减?
参考
1.A novel algorithm for privacy preserving utility mining based on integer linear programming
2.Integer Linear Programming (ILP)
3.CHUD算法


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









