







函数与函数式编程
函数式编程方式:
1.面向对象:华山派=>类:class
2.面向过程:少林派=>过程:def[关键字]【过程就是没有返回值的函数】
3.函数式编程:逍遥派=>函数:def[关键字:定义一个函数]
函数定义:
数学意义上:变量x,y中,x是自变量,y是因变量
编程语言意义上:把编程的逻辑函数化、过程化的东西
函数与过程结构:
定义过程:
def 函数名:
“”“文档介绍”""
代码块
定义函数:
def 函数名:
“”“文档介绍”""
代码块
返回值
举例理解:
# 过程:
def func1():
"""文档介绍1:这里是对这段代码的注释、描述"""
print('in the func1')
# 函数:
def func2():
"""文档介绍2:这里是对这段代码的注释、描述"""
print('in the func2')
return 0 # 函数是有返回值的
函数或过程的调用:
# 过程:
def func1():
"""文档介绍1:这里是对这段代码的注释、描述"""
print('in the func1')
# 函数:
def func2():
"""文档介绍2:这里是对这段代码的注释、描述"""
print('in the func2')
return 0 # 函数是有返回值的
# 调用函数或过程,用小括号来调用
x = func1() # 无返回值时,返回None。此处表明,python3中,过程也可当作函数被调用
y = func2() # 有返回值0
print('from func1 return is %s'%x)
print('from func2 return is %s'%y)
打印结果:
in the func1
in the func2
from func1 return is None
from func2 return is 0
为什么要学习函数?
1.代码的重复利用
2.保持一致性(改一处就相当于改了多处)
3.可扩展性
举例:模拟追加日志的一个功能
import time
def logger():
time_format = '%Y-%m-%d %X' # 规定时间的格式
time_current = time.strftime(time_format) # 代表以上面的时间格式显示当前时间
with open('a.txt','a+') as f: # 讲文件时讲到的用with替换closed
f.write('%s end action\n'%time_current)
def test1():
"""test1文档描述"""
print('test1 starting action...')
logger() # 调用上面定义了的函数logger
def test2():
"""test2文档描述"""
print('test2 starting action...')
logger()
def test3():
"""test3文档描述"""
print('test3 starting action...')
logger()
test1()
test2()
test3()
打印结果:
test1 starting action…
test2 starting action…
test3 starting action…
文件内容:
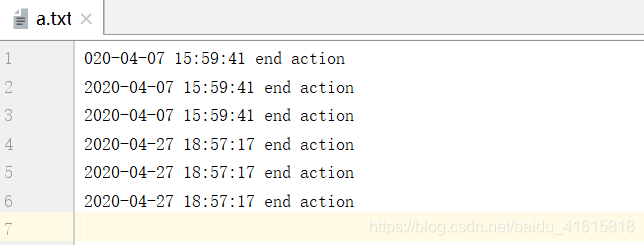
函数的返回值
'''直接调用后,只显示了打印结果'''
def test1():
print('in the test1')
return 0
test1()
打印结果:
in the test1
'''运行后未显示第二句打印内容的原因是,程序运行有返回值,运行到return就返回了'''
def test1():
print('in the test1')
return 0
print('test end')
test1()
打印结果:
in the test1
'''怎么使返回值显示出来?给函数定义一个变量,打印出来'''
def test1():
print('in the test1')
return 0
x = test1() # 代表函数test1()中有返回值的结果,这个值赋值给变量x
print(x)
打印结果:
in the test1
0
return后面可以返回什么样的值?
1.返回值数量为0(即没return时):返回None
2.返回值数量为1;返回object(python中所有的数据类型其实就是一个对象)
3.返回值数量>1:返回tuple(一个元组)
为什么要有返回值?
想要整个函数的执行结果
def test1():
print('in the test1') # 未定义return,解释器自动返回None
x = test1()
print(x)
打印结果:
in the test1
None
def test2():
print('in the test2')
return 0
y = test2()
print(y)
打印结果:
in the test2
0
def test3():
print('in the test3')
return 1,'hello',['alex','wupeiqi'],{'name':'alex'},test2
z = test3()
print(z) # 放到一个元组中返回
in the test3
(1, ‘hello’, [‘alex’, ‘wupeiqi’], {‘name’: ‘alex’}, <function test2 at 0x000002BEEFB6C1F0>)
函数编程之参数详解
1、形参和实参
2、位置参数和关键字
3、默认参数
4、参数组
# x,y形参;1、2是实参,在内存中真实存在
def test(x,y):
print(x)
print(y)
test(1,2) # 位置参数调用(标准调用)-----实参和形参一一对应
打印结果:
1
2
# x,y形参;1、2是实参,在内存中真实存在
def test(x,y):
print(x)
print(y)
test(y=1,x=2) # 关键字调用---与形参顺序无关,位置无需固定
打印结果:
2
1
# x,y形参;1、2是实参,在内存中真实存在
def test(x,y):
print(x)
print(y)
test(3,y=2) # 既有位置参数又有关键字参数,程序按位置参数调用
打印结果:
3
2
# x,y形参;1、2是实参,在内存中真实存在
def test(x,y):
print(x)
print(y)
test(2,x=3) # 位置参数和关键字参数冲突,程序执行后会报错
执行结果:
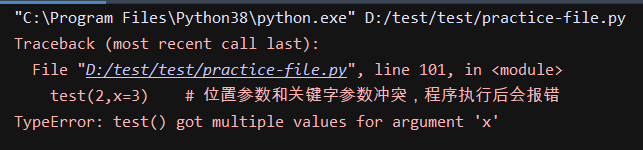
# x,y形参;1、2是实参,在内存中真实存在
def test(x,y):
print(x)
print(y)
test(x=2,3) # 关键字参数,不能写在位置参数前
书写效果:

默认参数:
定义参数时已给某些参数定义了默认的值。
特点:调用函数的时候,可不传默认值。
用途:如定义默认安装的值
def test (x,y=2):
print(x)
print(y)
test(1) # 调用函数的时候,可不传默认值。
打印结果:
1
2
def test (x,y=2):
print(x)
print(y)
test(3,3) # 虽有默认值,但调用时,若传了值,则覆盖默认值输出
打印结果:
3
3
参数组-接收位置参数:* args
通常写作*args:把n个位置参数,转换成元组的方式(接收位置参数)
星号代表后面的变量里,参数数量不固定,且将传值后所有的参数变为一个元组(只读列表)
def test(*args):
print(args)
test(1,2,3,4,55,7)
test(*[44,88,55,33]) # args=tuple([44,88,55,33]) *后可直接传值,可以直接传元组类型的值
def test1(x,*args):
print(x)
print(args)
test1('!!!!',2,3,4,5,6,7,8) # !!!!传给x;2,3,4,5,6,7,8传给*args
打印结果:
(1, 2, 3, 4, 55, 7)
(44, 88, 55, 33)
!!!!
(2, 3, 4, 5, 6, 7, 8)
参数组-接收字典:kwargs
通常写作kwargs:把n个关键字参数,转换成字典的方式(接收关键字参数)
星号代表后面的变量里,参数数量不固定,且将传值后所有的参数变为一个元组(只读列表)
def test2(**kwargs):
print(kwargs)
print(kwargs['name'])
print(kwargs['age'])
print(kwargs['sex'])
test2(name='alex',age=8,sex='F') # name当作字典的一个key,alex当作name的值
test2(**{'name':'alex','age':8,'sex':'F'}) # **后直接传值可以直接传字典类型的值
打印结果:
{‘name’: ‘alex’, ‘age’: 8, ‘sex’: ‘F’}
alex
8
F
{‘name’: ‘alex’, ‘age’: 8, ‘sex’: ‘F’}
alex
8
F
def test3(name,**kwargs): # 参数组**kwargs和位置参数结合
print(name)
print(kwargs)
test3('alex')
test3('alex','xxx') # 此处传的'alex'是一个位置参数,后面的'xxx'也是一个位置参数,但**kwargs接收的是关键字参数,因此此处会报错
test3('alex',age=18,sex='m') # 参数组**kwargs和位置参数结合
打印结果:
alex # test(‘alex’)调用结果
{} # test(‘alex’)调用结果
alex # test(‘alex’,age=18,sex=‘m’)调用结果
{‘age’: 18, ‘sex’: ‘m’} # test(‘alex’,age=18,sex=‘m’)调用结果
def test4(name,age=18,**kwargs): # 定义参数中有参数组的话,参数组一定往后放。参数组和位置参数、默认参数结合。
print(name)
print(age)
print(kwargs)
logger('TEST4')
def logger(source):
print('from %s'% source)
test4('alex',sex='m',hobby='tesla')
test4('alex',sex='m',hobby='tesla',age=3)
打印结果:
alex
18
{‘sex’: ‘m’, ‘hobby’: ‘tesla’}
from TEST4
alex
3
{‘sex’: ‘m’, ‘hobby’: ‘tesla’}
from TEST4
def test5(name,age=18,*args,**kwargs): # 定义参数中有参数组的话,参数组一定往后放。参数组和位置参数、默认参数结合。
print(name)
print(age)
print(args)
print(kwargs)
test5('alex',sex='m',hobby='tesla')
test5('alex',sex='m',hobby='tesla',age=3) #位置参数一定不能写在关键字参数后面
打印结果:
alex
18
()
{‘sex’: ‘m’, ‘hobby’: ‘tesla’}
alex
3
()
{‘sex’: ‘m’, ‘hobby’: ‘tesla’}
局部变量与全局变量
在子程序中定义的变量称为局部变量,在程序的一开始定义的变量称为全局变量。
全局变量作用域是整个程序,局部变量作用域是定义该变量的子程序。
当全局变量与局部变量同名时:
在定义局部变量的子程序中,局部变量起作用,在其他地方全局变量起作用。
'''全局变量就是在整个程序中都生效的变量'''
school = '01dboy edu.' # 全局变量
def change_name(name):
print('before change',name,school) # 全局变量可以在函数内被调用
print('before change',name)
'''局部变量只在函数里生效,这个函数就是这个变量的作用域'''
name = 'Alex Li' # 该局部变量在函数外不生效
print('After change',name)
name = 'alex'
change_name(name) # 先调用函数change_name
print(name) # 此处打印出来的,是小写的alex,而不是大写的Alex Li,原因是alex是全局变量,而Alex Li是局部变量,局部变量只在局部生效
打印结果:
before change alex 01dboy edu.
before change alex
After change Alex Li
alex
school = '01dboy edu.'
def change_name(name):
global school # 此处通过global的声明,将此处的school变成全局变量,生效的前提是调用函数change_name
school = 'MaGe'
print('before change',name,school) # 全局变量可以在函数内被调用
print('before change',name)
'''局部变量只在函数里生效,也即这个函数就是这个变量的作用域'''
name = 'Alex Li' # 该局部变量在函数外不生效
print('After change',name)
name = 'alex'
change_name(name) # 先调用函数change_name
print(name) # 此处打印出来的,是小写的alex,而不是大写的Alex Li,原因是alex是全局变量,而Alex Li是局部变量,局部变量只在局部生效
print('school:',school) # 通过global的声明,又因为调用了函数change_name,所以此处显示的是局部变量里的school值
打印结果:
before change alex MaGe
before change alex
After change Alex Li
alex
school: MaGe
总结:
前面没定义全局变量,但在函数中,通过global声明一个局部变量变为全局可调用,
在已调用函数的情况下,此局部变量可被全局使用。
但此例只是便于理解,工作中不要这样用(不要在函数中定义全局变量,应在全局定义)。
因为函数可能被程序很多地方调用,一旦出现问题,就很难知道是哪个地方调用后造成的错误。
例1:
def change_name():
global name
name = 'alex'
change_name() # 调用change_name这个函数
print(name)
打印结果:
alex
例2:
school = '01dboy edu.'
names = ['Alex','Jack','Rain']
def change_name():
names[0] = '金角大王' # 除字符串、整数外,稍微复杂一些的列表、字典、集合、类等,是可以直接在局部里面改全局的
print('inside func',names)
change_name()
print(names)
打印结果:
inside func [‘金角大王’, ‘Jack’, ‘Rain’]
[‘金角大王’, ‘Jack’, ‘Rain’]
递归
贪吃蛇=>自己咬自己
递归=>自己调自己
在函数内部,可以调其他函数。如果一个函数在内部调用自身本身,这个函数就是递归函数。
递归特性:
1、必须有一个明确的结束条件
2、每次进入更深一层递归时,问题规模相比上次递归都应有所减少。
3、递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,
每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧,由于栈的大小不是无限的,
所以,递归调用的次数过多,会导致栈溢出)
例1:
'''必须有一个明确的结束条件'''
def calc(n):
print(n)
return calc(n+1) # 返回的时候调自己再传进去 ,按理是无限循环,所以说必须有一个明确的结束条件
calc(0)
打印结果:
从0到997打印,后面会报:RecursionError: maximum recursion depth exceeded while calling a Python object。
意为:递归错误:调用Python对象时超过了最大递归深度。这是程序对递归深度的一个限制,避免死循环使程序崩溃。
例2:
def calc(n):
print(n)
if int(n/2) >0: # 给一个明确的结束条件
return calc(int(n/2))
print('->',n)
calc(10)
打印结果:
10
5
2
1
-> 1
本节小结:
1.类、函数、过程、方法的理解
2.java中,函数就是方法
3.return后面可以返回什么样的值?
4.为什么要有返回值?
5.参数?(理解:调用函数时,想要传给函数的东西)
形参、实参、位置参数、关键字参数(指定)、默认参数、参数组
6.参数组:接收位置参数? 接收字典(关键字参数)?
7.全局变量?局部变量?
8.递归函数?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









