




转载自:https://blog.youkuaiyun.com/qq_36556893/article/details/86505934
目录
*四、将Dataset数据和标签放在GPU上(代码执行顺序出错则会有bug)
一、概念
1.torch.utils.data.dataset这样的抽象类可以用来创建数据集。学过面向对象的应该清楚,抽象类不能实例化,因此我们需要构造这个抽象类的子类来创建数据集,并且我们还可以定义自己的继承和重写方法。
2.这其中最重要的就是__len__和__getitem__这两个函数,前者给出数据集的大小,后者是用于查找数据和标签。
3.torch.utils.data.DataLoader是一个迭代器,方便我们去多线程地读取数据,并且可以实现batch以及shuffle的读取等。
二、Dataset的创建和使用
1.首先我们需要引入dataset这个抽象类,当然我们还需要引入Numpy:
-
import torch.utils.data.dataset
as Dataset
-
import numpy
as np
2.我们创建Dataset的一个子类:
(1)初始化,定义数据内容和标签:
-
#初始化,定义数据内容和标签
-
def __init__(self, Data, Label):
-
self.Data = Data
-
self.Label = Label
(2)返回数据集大小:
-
#返回数据集大小
-
def __len__(self):
-
return len(self.Data)
(3)得到数据内容和标签:
-
#得到数据内容和标签
-
def __getitem__(self, index):
-
data = torch.Tensor(self.Data[index])
-
label = torch.Tensor(self.Label[index])
-
return data, label
(4)最终这个子类定义为:
-
import torch
-
import torch.utils.data.dataset
as Dataset
-
import numpy
as np
-
#创建子类
-
class subDataset(Dataset.Dataset):
-
#初始化,定义数据内容和标签
-
def __init__(self, Data, Label):
-
self.Data = Data
-
self.Label = Label
-
#返回数据集大小
-
def __len__(self):
-
return len(self.Data)
-
#得到数据内容和标签
-
def __getitem__(self, index):
-
data = torch.Tensor(self.Data[index])
-
label = torch.Tensor(self.Label[index])
-
return data, label
值得注意的地方是:
class subDataset(Dataset.Dataset):
如果只写了Dataset而不是Dataset.Dataset,则会报错:module.__init__() takes at most 2 arguments (3 given)
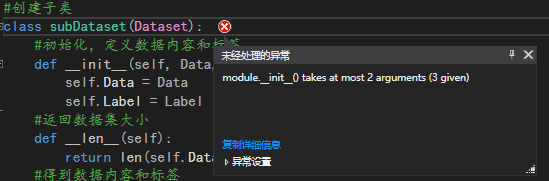
因为Dataset是module模块,不是class类,所以需要调用module里的class才行,因此是Dataset.Dataset!
3.在类外对Data和Label赋值:
-
Data = np.asarray([[
1,
2], [
3,
4],[
5,
6], [
7,
8]])
-
Label = np.asarray([[
0], [
1], [
0], [
2]])
4.声明主函数,主函数创建一个子类的对象,传入Data和Label参数:
-
if __name__ ==
'__main__':
-
dataset = subDataset(Data,
Label)
5.输出数据集大小和数据:
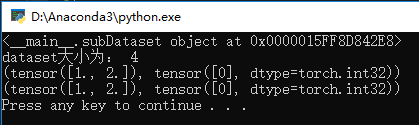
-
print(dataset)
-
print(
'dataset大小为:', dataset.__len__())
-
print(dataset.__getitem__(
0))
-
print(dataset[
0])
代码变为;
-
import torch
-
import torch.utils.data.dataset
as Dataset
-
import numpy
as np
-
-
Data = np.asarray([[
1,
2], [
3,
4],[
5,
6], [
7,
8]])
-
Label = np.asarray([[
0], [
1], [
0], [
2]])
-
#创建子类
-
class subDataset(Dataset.Dataset):
-
#初始化,定义数据内容和标签
-
def __init__(self, Data, Label):
-
self.Data = Data
-
self.Label = Label
-
#返回数据集大小
-
def __len__(self):
-
return len(self.Data)
-
#得到数据内容和标签
-
def __getitem__(self, index):
-
data = torch.Tensor(self.Data[index])
-
label = torch.IntTensor(self.Label[index])
-
return data, label
-
-
if __name__ ==
'__main__':
-
dataset = subDataset(Data, Label)
-
print(dataset)
-
print(
'dataset大小为:', dataset.__len__())
-
print(dataset.__getitem__(
0))
-
print(dataset[
0])
结果为:
三、DataLoader的创建和使用
1.引入DataLoader:
import torch.utils.data.dataloader as DataLoader
2. 创建DataLoader,batch_size设置为2,shuffle=False不打乱数据顺序,num_workers= 4使用4个子进程:
-
#创建DataLoader迭代器
-
dataloader = DataLoader.DataLoader(dataset,batch_size=
2, shuffle =
False, num_workers=
4)
3.使用enumerate访问可遍历的数组对象:
-
for i, item
in enumerate(dataloader):
-
print(
'i:', i)
-
data, label = item
-
print(
'data:', data)
-
print(
'label:', label)
4.最终代码如下:
-
import torch
-
import torch.utils.data.dataset
as Dataset
-
import torch.utils.data.dataloader
as DataLoader
-
import numpy
as np
-
-
Data = np.asarray([[
1,
2], [
3,
4],[
5,
6], [
7,
8]])
-
Label = np.asarray([[
0], [
1], [
0], [
2]])
-
#创建子类
-
class subDataset(Dataset.Dataset):
-
#初始化,定义数据内容和标签
-
def __init__(self, Data, Label):
-
self.Data = Data
-
self.Label = Label
-
#返回数据集大小
-
def __len__(self):
-
return len(self.Data)
-
#得到数据内容和标签
-
def __getitem__(self, index):
-
data = torch.Tensor(self.Data[index])
-
label = torch.IntTensor(self.Label[index])
-
return data, label
-
-
if __name__ ==
'__main__':
-
dataset = subDataset(Data, Label)
-
print(dataset)
-
print(
'dataset大小为:', dataset.__len__())
-
print(dataset.__getitem__(
0))
-
print(dataset[
0])
-
-
#创建DataLoader迭代器
-
dataloader = DataLoader.DataLoader(dataset,batch_size=
2, shuffle =
False, num_workers=
4)
-
for i, item
in enumerate(dataloader):
-
print(
'i:', i)
-
data, label = item
-
print(
'data:', data)
-
print(
'label:', label)
结果为:
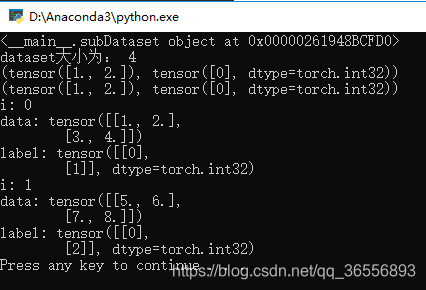
可以看到两个对象,因为对象数*batch_size就是数据集的大小__len__
*四、将Dataset数据和标签放在GPU上(代码执行顺序出错则会有bug)
1.改写__getitem__函数:
-
if torch.cuda.is_available():
-
data = data.cuda()
-
label = label.cuda()
代码变为:
-
#得到数据内容和标签
-
def __getitem__(self, index):
-
data = torch.Tensor(self.Data[index])
-
label = torch.IntTensor(self.Label[index])
-
if torch.cuda.is_available():
-
data = data.cuda()
-
label = label.cuda()
-
return data, label
2.报错啦:
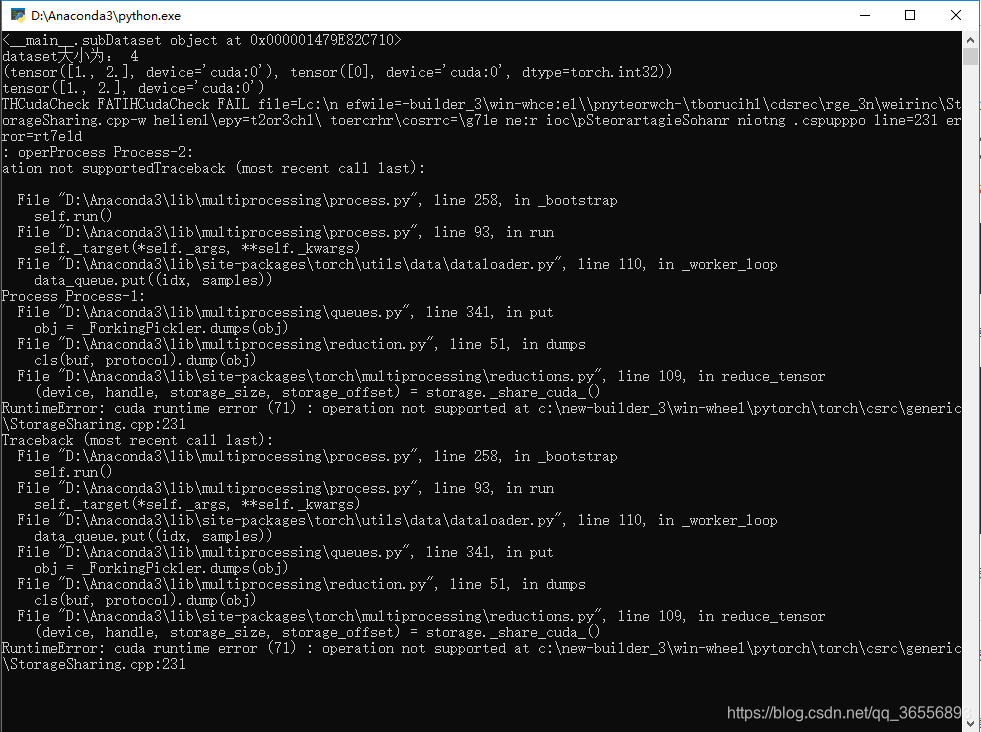
文字描述为:
-
THCudaCheck FATIHCudaCheck FAIL file=Lc:\n efwile=-builder_3\win-whce:el\\pnyteorwch-\tborucihl\cdsrec\rge_3n\weirinc\StorageSharing.cpp-w helienl\epy=t2or3ch1\ toercrhr\cosrrc=\g71e ne:r ioc\pSteorartagieSohanr niotng .cspupppo line=
231 error=rt7e1d
-
: operProcess Process
-2:
-
ation
not supportedTraceback (most recent call last):
-
-
File
"D:\Anaconda3\lib\multiprocessing\process.py", line
258,
in _bootstrap
-
self.run()
-
File
"D:\Anaconda3\lib\multiprocessing\process.py", line
93,
in run
-
self._target(*self._args, **self._kwargs)
-
File
"D:\Anaconda3\lib\site-packages\torch\utils\data\dataloader.py", line
110,
in _worker_loop
-
data_queue.put((idx, samples))
-
Process Process
-1:
-
File
"D:\Anaconda3\lib\multiprocessing\queues.py", line
341,
in put
-
obj = _ForkingPickler.dumps(obj)
-
File
"D:\Anaconda3\lib\multiprocessing\reduction.py", line
51,
in dumps
-
cls(buf, protocol).dump(obj)
-
File
"D:\Anaconda3\lib\site-packages\torch\multiprocessing\reductions.py", line
109,
in reduce_tensor
-
(device, handle, storage_size, storage_offset) = storage._share_cuda_()
-
RuntimeError: cuda runtime error (
71) : operation
not supported at c:\new-builder_3\win-wheel\pytorch\torch\csrc\generic\StorageSharing.cpp:
231
-
Traceback (most recent call last):
-
File
"D:\Anaconda3\lib\multiprocessing\process.py", line
258,
in _bootstrap
-
self.run()
-
File
"D:\Anaconda3\lib\multiprocessing\process.py", line
93,
in run
-
self._target(*self._args, **self._kwargs)
-
File
"D:\Anaconda3\lib\site-packages\torch\utils\data\dataloader.py", line
110,
in _worker_loop
-
data_queue.put((idx, samples))
-
File
"D:\Anaconda3\lib\multiprocessing\queues.py", line
341,
in put
-
obj = _ForkingPickler.dumps(obj)
-
File
"D:\Anaconda3\lib\multiprocessing\reduction.py", line
51,
in dumps
-
cls(buf, protocol).dump(obj)
-
File
"D:\Anaconda3\lib\site-packages\torch\multiprocessing\reductions.py", line
109,
in reduce_tensor
-
(device, handle, storage_size, storage_offset) = storage._share_cuda_()
-
RuntimeError: cuda runtime error (
71) : operation
not supported at c:\new-builder_3\win-wheel\pytorch\torch\csrc\generic\StorageSharing.cpp:
231
3.那怎么办呢?有两种方法:
(1)只需要将num_workers改成0即可:
dataloader = DataLoader.DataLoader(dataset,batch_size= 2, shuffle = False, num_workers= 0)
代码变为:
-
import torch
-
import torch.utils.data.dataset
as Dataset
-
import torch.utils.data.dataloader
as DataLoader
-
import numpy
as np
-
-
Data = np.asarray([[
1,
2], [
3,
4],[
5,
6], [
7,
8]])
-
Label = np.asarray([[
0], [
1], [
0], [
2]])
-
#创建子类
-
class subDataset(Dataset.Dataset):
-
#初始化,定义数据内容和标签
-
def __init__(self, Data, Label):
-
self.Data = Data
-
self.Label = Label
-
#返回数据集大小
-
def __len__(self):
-
return len(self.Data)
-
#得到数据内容和标签
-
def __getitem__(self, index):
-
data = torch.Tensor(self.Data[index])
-
label = torch.IntTensor(self.Label[index])
-
if torch.cuda.is_available():
-
data = data.cuda()
-
label = label.cuda()
-
return data, label
-
-
if __name__ ==
'__main__':
-
dataset = subDataset(Data, Label)
-
print(dataset)
-
print(
'dataset大小为:', dataset.__len__())
-
print(dataset.__getitem__(
0))
-
print(dataset[
0][
0])
-
-
#创建DataLoader迭代器
-
dataloader = DataLoader.DataLoader(dataset,batch_size=
2, shuffle =
False, num_workers=
0)
-
for i, item
in enumerate(dataloader):
-
print(
'i:', i)
-
data, label = item
-
print(
'data:', data)
-
print(
'label:', label)
结果为:
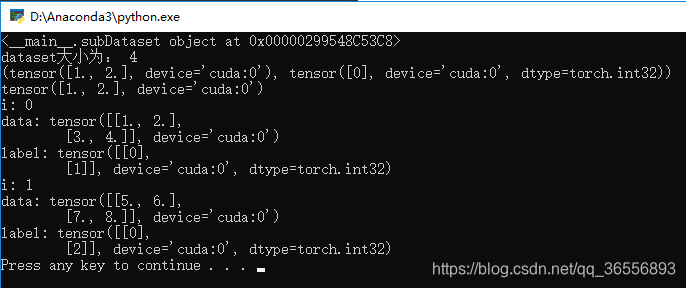
可以看到多了一个device='cuda:0'
(2)把Tensor放到GPU上的操作放在DataLoader之后,即删除__getitem__函数里的下面内容
-
if torch.cuda.is_available():
-
data = data.cuda()
-
label = label.cuda()
并在主函数的for循环里添加删除的语句,代码变为
-
import torch
-
import torch.utils.data.dataset
as Dataset
-
import torch.utils.data.dataloader
as DataLoader
-
import numpy
as np
-
-
Data = np.asarray([[
1,
2], [
3,
4],[
5,
6], [
7,
8]])
-
Label = np.asarray([[
0], [
1], [
0], [
2]])
-
#创建子类
-
class subDataset(Dataset.Dataset):
-
#初始化,定义数据内容和标签
-
def __init__(self, Data, Label):
-
self.Data = Data
-
self.Label = Label
-
#返回数据集大小
-
def __len__(self):
-
return len(self.Data)
-
#得到数据内容和标签
-
def __getitem__(self, index):
-
data = torch.Tensor(self.Data[index])
-
label = torch.IntTensor(self.Label[index])
-
return data, label
-
-
if __name__ ==
'__main__':
-
dataset = subDataset(Data, Label)
-
print(dataset)
-
print(
'dataset大小为:', dataset.__len__())
-
print(dataset.__getitem__(
0))
-
print(dataset[
0][
0])
-
-
#创建DataLoader迭代器
-
dataloader = DataLoader.DataLoader(dataset,batch_size=
2, shuffle =
False, num_workers=
8)
-
for i, item
in enumerate(dataloader):
-
print(
'i:', i)
-
data, label = item
-
if torch.cuda.is_available():
-
data = data.cuda()
-
label = label.cuda()
-
print(
'data:', data)
-
print(
'label:', label)
结果为
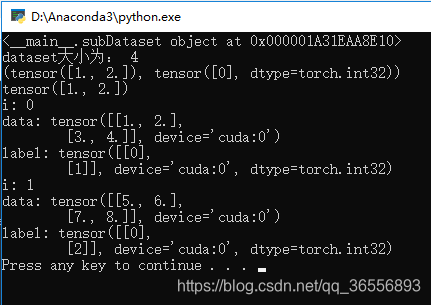
五、Dataset和DataLoader总结
1.Dataset是一个抽象类,需要派生一个子类构造数据集,需要改写的方法有__init__,__getitem__等。
2.DataLoader是一个迭代器,方便我们访问Dataset里的对象,值得注意的num_workers的参数设置:如果放在cpu上跑,可以不管,但是放在GPU上则需要设置为0;或者在DataLoader操作之后将Tensor放在GPU上。
3.数据和标签是tuple元组的形式,使用Dataloader然后使用enumerate函数访问它们。

















 4014
4014

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









