










深度学习之图像分类(四)VGGNet网络结构及感受野计算
本节学习VGGNet网络结构以及感受野计算,学习视频源于 Bilibili,部分描述参考 知乎专栏,感谢霹雳吧啦Wz,建议大家去看视频学习哦。

1. 前言
VGGNet 是 2014 年牛津大学著名研究组 VGG(Visual Geometry Group) 提出,斩获该年 ImageNet 竞赛中 Localization Task 第一名和 Classification Task 第二名 (第一名为 GoogLeNet)。原始论文为 Very deep convolutional networks for large-scale image recognition。
该论文在当时最大的亮点是:通过堆叠 3 × 3 3 \times 3 3×3 的卷积核来代替大尺度卷积核,并减少参数量
- 大卷积核,例如 AlexNet 第一层的 11 × 11 11 \times 11 11×11,参数量大,且难学好
- 多个
3
×
3
3 \times 3
3×3 的卷积核感受野和一个大的卷积核感受野一致,但是更好学,且参数量更少
- 两个 3 × 3 3 \times 3 3×3 的卷积核替代一个 5 × 5 5 \times 5 5×5 的卷积核
- 三个 3 × 3 3 \times 3 3×3 的卷积核替代一个 7 × 7 7 \times 7 7×7 的卷积核
- 真实人的视网膜初级结构获取的底层特征并非 3 × 3 3 \times 3 3×3 领域,而是更大的例如 11 × 11 11 \times 11 11×11, 17 × 17 17 \times 17 17×17 等尺寸
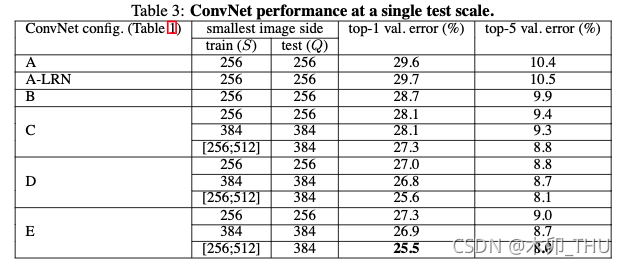
下图左边的表格截取于原论文,作者给出了六个不同的配置,包括比较 LRN(局部响应归一化)、不同卷积核尺寸等。一般而言常用的是 D 配置,即 VGG-16,16 表示 13 个卷积层以及 3 个全连接层。
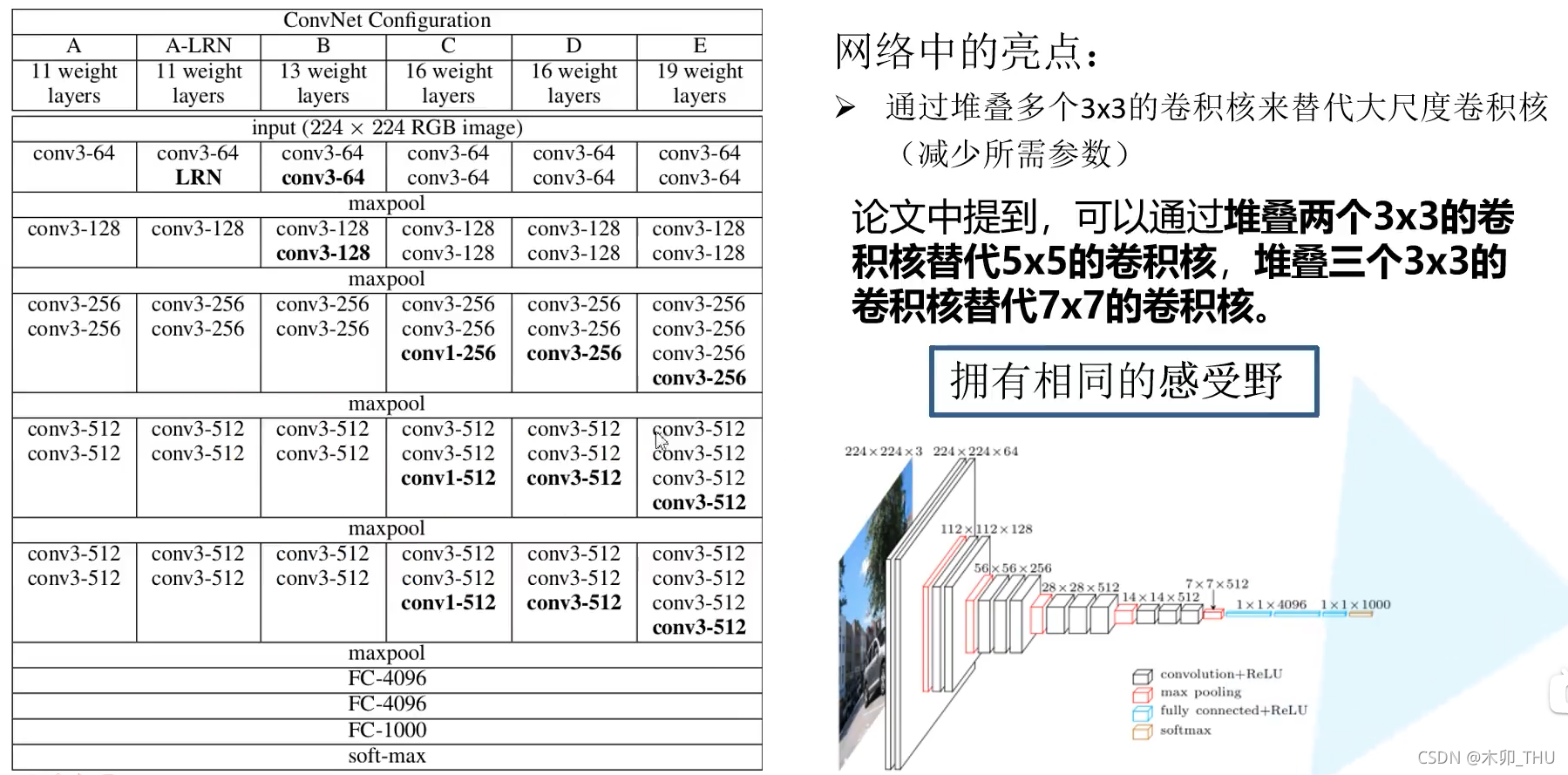
1)A和A-LRN对比:分析LRN在网络中的效果
2)A和B对比:分析在网络靠近输入部分增加卷积层数的效果
3)B和C对比:分析在网络靠近输出部分增加卷积层数的效果
4)C和D对比:分析1X1卷积核和3X3卷积核的对比效果
5)D和E对比:分析在网络靠近输出部分增加卷积层数的效果(这个和3)的作用有点像,只是网络进一步加深)
各个网络的对比结果如下:
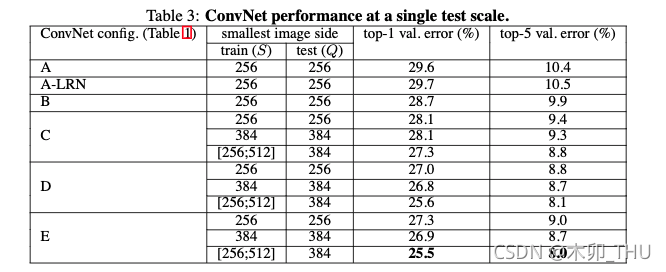
从这个表中,我们可以对上面5个对比思路下结论:
1)A和A-LRN对比:精度损失0.1%,可以认为精度变化不大,但是LRN操作会增大计算量,所以作者认为在网络中添加LRN意义不大
2)A和B对比:top-1提高0.9%,说明在靠近输入部分增加深度可以提高精度
3)B和C对比:top-1提高0.6%,说明在靠近输出部分增加深度也可以提高精度
4)C和D对比:top-1提高1.1%,说明3X3卷积核的效果要明显由于1X1卷积核的效果
5)D和E对比:top-1下降0.3%,这个我解释不了,不清楚是不是因为网络更深以后,更容易出现过拟合
2. CNN感受野
在卷积神经网络中,决定某一层输出结果中一个元素所对应的输入层的区域大小,被称作感受野(receptive field)。通俗而言,输出 feature map 上的一个单元对应输入层上的区域大小。
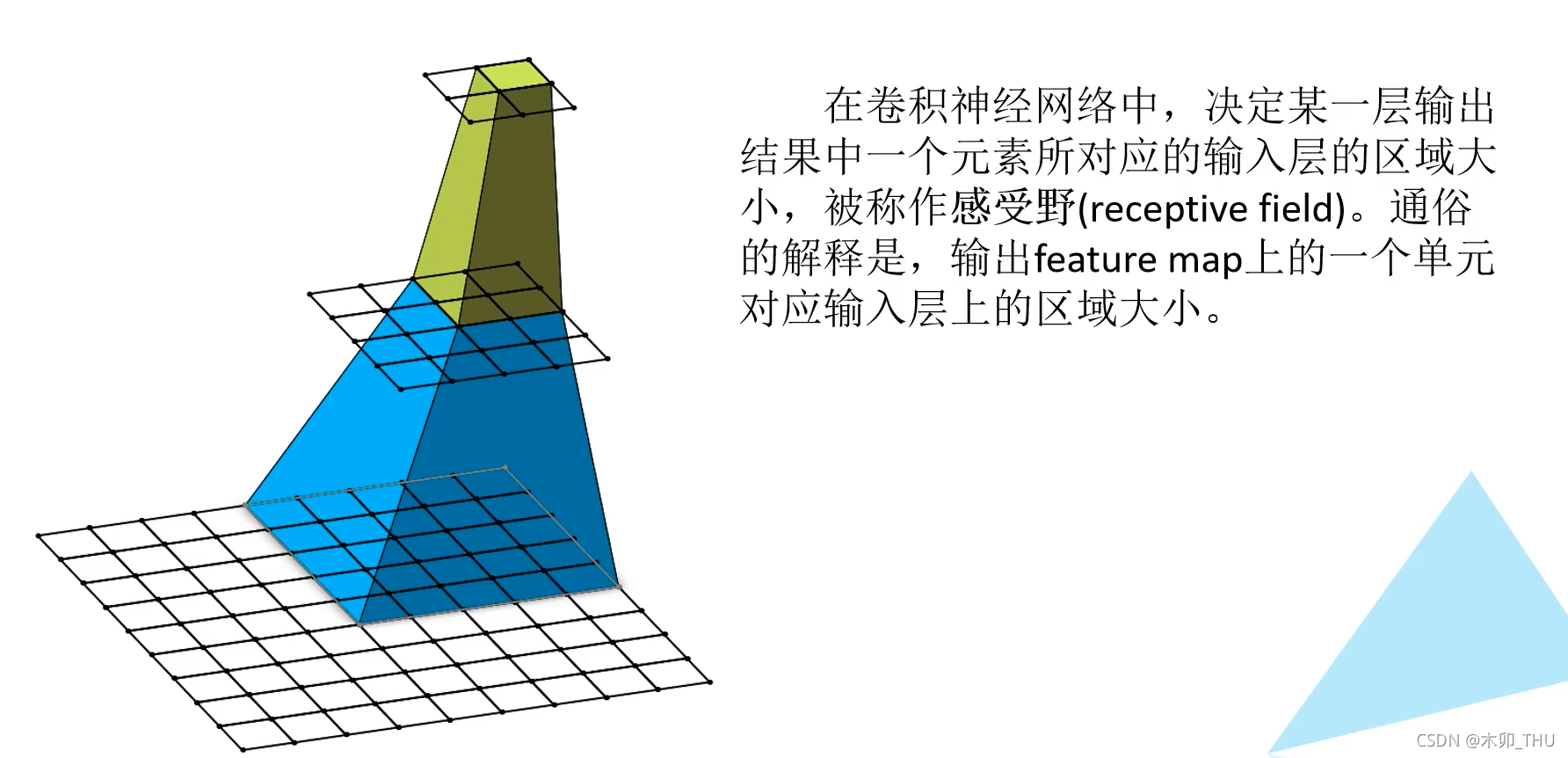
让我们来看一个例子,下图左边最下面是一个 9 × 9 × 1 9 \times 9 \times 1 9×9×1 的特征矩阵,经过第一个卷积层(卷积核大小为 3 × 3 3 \times 3 3×3 ,步距为 2)。然后再通过一个最大池化下采样操作,(卷积核大小为 2 × 2 2 \times 2 2×2 ,步距为 2),最后得到的特征图大小为 2 × 2 × 1 2 \times 2 \times 1 2×2×1 。从图中可以看出,感受野大小为 5 × 5 5 \times 5 5×5。
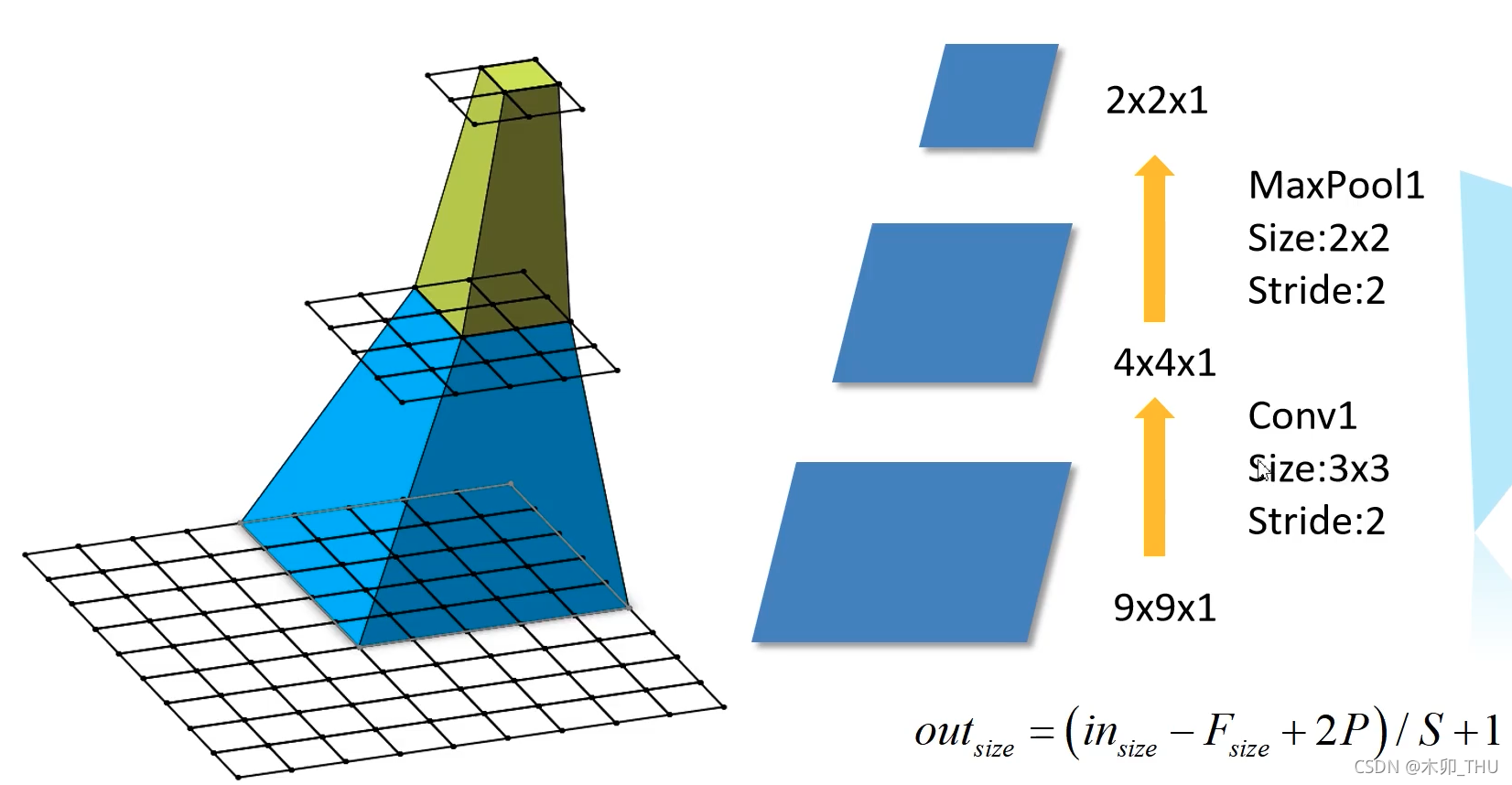
下图给出了感受野大小的计算公式:
F
(
i
)
=
(
F
(
i
+
1
)
−
1
)
×
S
t
r
i
d
e
+
K
s
i
z
e
F(i) = (F(i+1)-1) \times Stride + Ksize
F(i)=(F(i+1)−1)×Stride+Ksize
其中
F
(
i
)
F(i)
F(i) 为第
i
i
i 层的感受野,Stride 为第
i
i
i 层的步距,Ksize 为卷积核或者池化层尺寸。
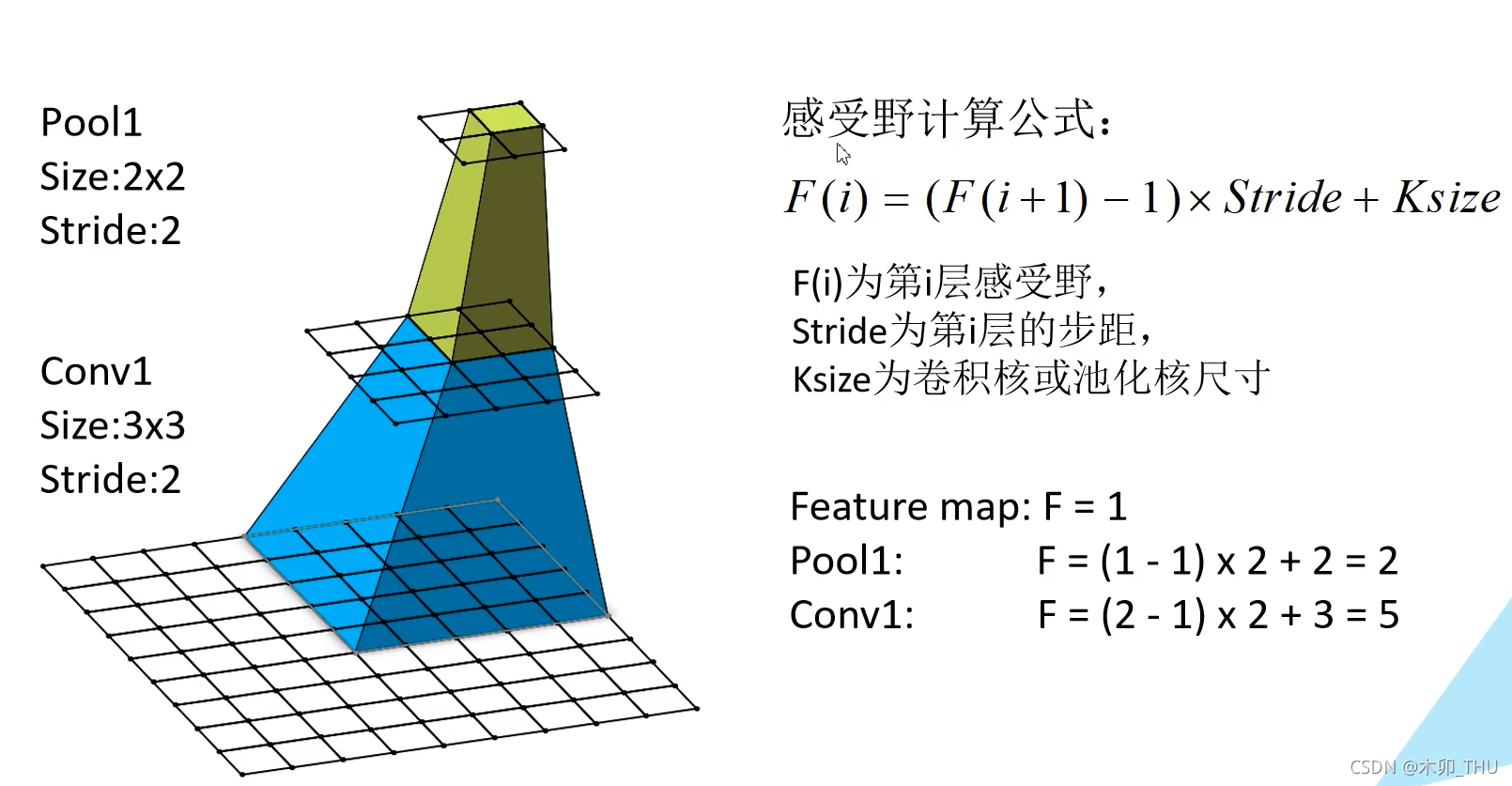
在 VGGNet 论文中作者说:三个 3 × 3 3 \times 3 3×3 的卷积核替代一个 7 × 7 7 \times 7 7×7 的卷积核,卷积核步距为 1。我们进行简单的计算:
Feature map: F = 1
Conv3x3(3) : F = (1 - 1) x 1 + 3 = 3
Conv3x3(2) : F = (3 - 1) x 1 + 3 = 5
Conv3x3(1) : F = (5 - 1) x 1 + 3 = 7
让我们来比较一下使用 7 × 7 7 \times 7 7×7 的卷积核所需要的参数以及使用三个 3 × 3 3 \times 3 3×3 的卷积核所需要的参数,假设输入输出通道都为 C C C:
-
7 × 7 × C × C = 49 C 2 7 \times 7 \times C \times C = 49C^2 7×7×C×C=49C2
-
3 × ( 3 × 3 × C × C ) = 27 C 2 3 \times (3 \times 3 \times C \times C) = 27C^2 3×(3×3×C×C)=27C2
-
27 / 49 = 0.551 27 / 49 = 0.551 27/49=0.551
注意,这里没有考虑 bias 参数。可见在感受野相等的情况下, 使用三个 3 × 3 3 \times 3 3×3 的卷积核替代一个 7 × 7 7 \times 7 7×7 的卷积核仅有一半的参数量。
3. VGG网络结构
以 VGG16 为例进行讲解,对应配置为 D。表中卷积 conv 默认的步距 stride = 1,padding = 1;最大池化 maxpool 的 kernel size = 2,步距 stride = 2。左下角图对应的就是 VGG16 的网络结构图。

最终网络参数量如图所示:

INPUT: [224x224x3] memory: 224*224*3=150K weights: 0
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*3)*64 = 1,728
CONV3-64: [224x224x64] memory: 224*224*64=3.2M weights: (3*3*64)*64 = 36,864
POOL2: [112x112x64] memory: 112*112*64=800K weights: 0
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*64)*128 = 73,728
CONV3-128: [112x112x128] memory: 112*112*128=1.6M weights: (3*3*128)*128 = 147,456
POOL2: [56x56x128] memory: 56*56*128=400K weights: 0
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*128)*256 = 294,912
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
CONV3-256: [56x56x256] memory: 56*56*256=800K weights: (3*3*256)*256 = 589,824
POOL2: [28x28x256] memory: 28*28*256=200K weights: 0
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*256)*512 = 1,179,648
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [28x28x512] memory: 28*28*512=400K weights: (3*3*512)*512 = 2,359,296
POOL2: [14x14x512] memory: 14*14*512=100K weights: 0
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
CONV3-512: [14x14x512] memory: 14*14*512=100K weights: (3*3*512)*512 = 2,359,296
POOL2: [7x7x512] memory: 7*7*512=25K weights: 0
FC: [1x1x4096] memory: 4096 weights: 7*7*512*4096 = 102,760,448
FC: [1x1x4096] memory: 4096 weights: 4096*4096 = 16,777,216
FC: [1x1x1000] memory: 1000 weights: 4096*1000 = 4,096,000
TOTAL memory: 24M * 4 bytes ~= 93MB / image (only forward! ~*2 for bwd)
TOTAL params: 138M parameters
VGGNet 使用了 Multi-Scale 的方法进行数据增强,将原始图像缩放到不同尺寸 S S S,然后再随机裁切 224 × 224 224 \times 224 224×224 的图片,这样能增加很多数据量,对于防止模型过拟合有很不错的效果。实践中,作者令 S S S 在 [256,512] 这个区间内取值,使用 Multi-Scale 获得多个版本的数据,并将多个版本的数据合在一起进行训练。
4. 代码
import torch.nn as nn
import torch
import torch.utils.model_zoo as model_zoo
# official pretrain weights
model_urls = {
'vgg11': 'https://download.pytorch.org/models/vgg11-bbd30ac9.pth',
'vgg13': 'https://download.pytorch.org/models/vgg13-c768596a.pth',
'vgg16': 'https://download.pytorch.org/models/vgg16-397923af.pth',
'vgg19': 'https://download.pytorch.org/models/vgg19-dcbb9e9d.pth'
}
class VGG(nn.Module):
def __init__(self, features, num_classes=1000, init_weights=False):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Linear(512*7*7, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(p=0.5),
nn.Linear(4096, num_classes)
)
if init_weights:
self._initialize_weights()
def forward(self, x):
# N x 3 x 224 x 224
x = self.features(x)
# N x 512 x 7 x 7
x = torch.flatten(x, start_dim=1)
# N x 512*7*7
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
# nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
nn.init.xavier_uniform_(m.weight)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
# nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def make_features(cfg: list):
layers = []
in_channels = 3
for v in cfg:
if v == "M":
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
layers += [conv2d, nn.ReLU(True)]
in_channels = v
return nn.Sequential(*layers)
cfgs = {
'vgg11': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg13': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'vgg16': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'vgg19': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def vgg(model_name="vgg16", **kwargs):
assert model_name in cfgs, "Warning: model number {} not in cfgs dict!".format(model_name)
cfg = cfgs[model_name]
model = VGG(make_features(cfg), **kwargs)
# load ImageNet params
state_dic = model_zoo.load_url(model_urls[model_name])
del_key = []
for key, _ in state_dic.items():
if "classifier" in key:
del_key.append(key)
for key in del_key:
del state_dic[key]
missing_keys, unexpected_keys = model.load_state_dict(state_dic, strict=False)
return model


















 859
859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











