







 本文探讨了XGBoost的原生接口与sklearn接口的区别,详细介绍了原生接口的参数设置,包括params、dtrain、num_boost_round、evals等,并提到了自定义目标函数、评估函数和早期停止策略。通过实例展示了两种接口的使用方式,强调了原生接口在灵活性和控制训练过程上的优势。
本文探讨了XGBoost的原生接口与sklearn接口的区别,详细介绍了原生接口的参数设置,包括params、dtrain、num_boost_round、evals等,并提到了自定义目标函数、评估函数和早期停止策略。通过实例展示了两种接口的使用方式,强调了原生接口在灵活性和控制训练过程上的优势。
1、区别如图:
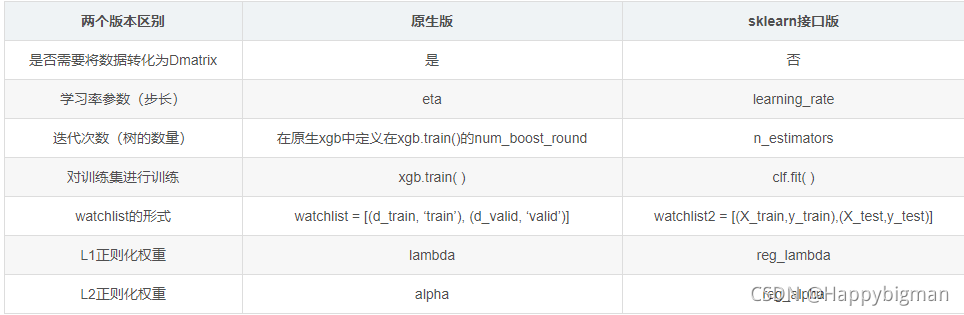
2、xgboost原生接口和sklearn代码如下:
(1)原生形式使用Xgboost(import xgboost as xgb)
from sklearn import datasets
from sklearn.model_selection import train_test_split
import xgboost as xgb
import numpy as np
from sklearn.metrics import precision_score, recall_score
# 加载数据
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=42)
print("Train data length:", len(X_train))
print("Test data length:", len(X_test))
# 转换为DMatrix数据格式
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
# 设置 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2293
2293

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









