



大规模RAG系统延迟优化需跳出局部思维,采用系统级解决方案。文章提出多层次优化策略:检索阶段采用多级召回与混合检索;上下文管理通过重排序与压缩技术;生成阶段使用高效推理框架;系统级实现多级缓存、智能路由和并行处理。只有将这些技术有机结合,才能构建真正低延迟、高吞吐、能稳定支撑生产环境的RAG系统,这不仅是技术挑战,更是工程智慧的体现。

面对大规模RAG系统在生产环境下的延迟挑战,很多工程师下意识地会去优化向量检索的速度,或者去抠大模型推理的每毫秒。这当然没错,但仅仅聚焦于局部优化,往往会陷入“头痛医头脚痛医脚”的窘境。真正的瓶颈,远不止于此。
一个高并发、低延迟的大规模RAG系统,其性能优化是一个系统性工程。它牵扯到从数据摄取、索引构建、检索策略、上下文管理、大模型推理,到整个请求生命周期的编排与资源调度。如果你只盯着其中一环,那么你获得的可能只是局部最优,而全局延迟依然居高不下。
为什么局部优化是“陷阱”
我们来看几个常见的误区:
-
- 盲目追求向量检索速度:HNSW、Faiss等库已经非常快了,但如果你的检索召回结果过多(例如召回500条),即使向量检索本身快,后续的Reranking和上下文拼接依然会拖慢整个链路。
-
- 过度依赖大模型推理优化:vLLM、TGI等框架固然能显著提升单次推理吞吐,但如果你的上下文窗口塞满了大量低质量或冗余信息,大模型不仅推理慢,回答质量也会下降。更何况,每次都调用一次全量的RAG流程,成本也是天文数字。
-
- 忽视前置处理与缓存:很多请求的查询意图是相似的,或者某些文档是高频被召回的。如果每次都从头到尾跑一遍,那就是巨大的资源浪费。
这些局部优化,就像在赛车的某个零件上打磨了几微米,但整车的发动机、传动系统、空气动力学设计都还停留在原始状态。要真正提速,必须是系统级的改造。
大规模RAG系统延迟的「系统级」解法
要从根本上解决大规模RAG系统的延迟问题,我们需要一个多层次、多维度的优化策略。
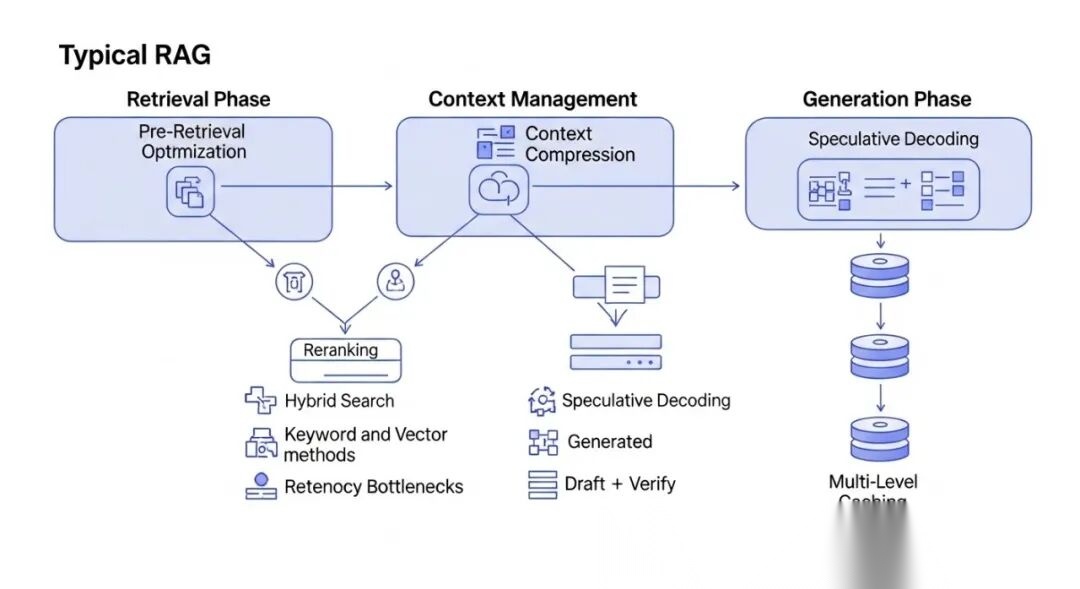
A diagram showing a typical RAG pipeline with highlighted latency bottlenecks and potential optimization points across retrieval, context management, and generation phases, including pre-retrieval, hybrid search, reranking, context compression, speculative decoding, and multi-level caching.
1. 检索阶段优化:从“广撒网”到“精准狙击”
检索是RAG的第一道关卡,其效率和质量直接决定了后续流程的负担。
-
• 多级召回与混合检索(Multi-stage & Hybrid Retrieval)
-
• 预过滤(Pre-filtering): 在向量检索之前,结合元数据(metadata)进行精确过滤。例如,如果查询明确指定了时间范围、部门或产品类别,先用Elasticsearch或关系型数据库过滤掉不相关的文档,大幅缩小向量检索空间。
-
• 混合检索(Hybrid Search): 将关键词检索(如BM25/Elasticsearch)和向量检索结合。对于强关键词或高频短语,关键词检索更快更准;对于语义关联性强的查询,向量检索更优。通常的做法是并行检索,然后融合结果,或者用关键词结果作为向量检索的辅助过滤。
-
• 动态召回策略(Dynamic Retrieval Strategy): 根据查询的复杂性、用户画像或历史行为,动态选择不同的召回策略。例如,对于简单、明确的查询,可以只使用少量文档的向量检索;对于复杂、开放性问题,则启动多阶段召回和Reranking。
-
-
• 智能索引与分块(Intelligent Indexing & Chunking)
-
• 分层索引(Hierarchical Indexing): 不仅仅是单一粒度的文档块。可以构建不同粒度的索引:例如,一个包含文档标题、摘要的粗粒度索引用于快速定位大致范围;一个包含详细段落的细粒度索引用于精确匹配。
-
• 语义分块(Semantic Chunking): 避免固定长度分块导致的语义割裂。利用LLM或规则将文档切分成语义完整的单元。甚至可以考虑图结构索引,保留文档内部的关联性。
-
2. 上下文管理与压缩:去伪存真,精炼入魂
即使检索到了相关文档,如何高效地将其转化为LLM可用的上下文,是另一个巨大的挑战。
-
• 重排序(Reranking): 初步召回的文档,往往鱼龙混杂。使用一个更小、更快的“精排”模型(如Sentence-BERT、BGE-Reranker)对初步召回的几十到几百个文档进行二次排序,确保最相关的文档排在前面。这比直接把所有召回结果喂给大模型效率高得多,因为LLM对上下文的位置敏感。
-
• 上下文压缩(Context Compression):
-
• 抽取式压缩(Extractive Compression): 使用小模型或关键词提取技术,从召回文档中抽取最关键的句子或短语,而不是全文。例如,使用
LLM as a filter,让一个轻量级模型对每个召回块提炼关键信息。 -
• 抽象式压缩(Abstractive Compression): 使用LLM对召回文档进行总结和提炼,生成更简洁、精炼的摘要作为输入。这会增加LLM的调用次数,但能显著减少最终LLM的输入Token数,降低推理成本和延迟。
-
-
• Prompt工程优化: 精心设计的Prompt能引导LLM更高效地利用上下文。例如,明确指示LLM“只回答与上下文相关的问题”、“如果上下文中找不到答案,则明确说明”。
3. 生成阶段优化:高速公路上的超跑
大模型的推理速度依然是瓶颈,但通过技术栈优化和服务层面的策略,可以大幅提升。
-
• 高效推理框架(Efficient Inference Frameworks):
-
• vLLM/Text Generation Inference (TGI): 这些框架通过PagedAttention、连续批处理(Continuous Batching)等技术,显著提升了GPU利用率和吞吐量。在生产环境中,这几乎是标配。
-
• 量化(Quantization): 将模型权重从FP16/BF16量化到INT8甚至INT4,可以在保持一定精度的前提下,减少显存占用和计算量,从而加速推理。
-
-
• 推测解码(Speculative Decoding): 利用一个小型、快速的草稿模型(draft model)预生成一批Token,然后由大型目标模型进行验证和纠正。如果草稿模型预测准确,可以跳过大量计算,显著加速推理。
-
• 流式输出(Streaming Output): 不等待整个回答生成完毕,而是每生成一个Token就立即返回。这大大改善了用户体验,降低了感知延迟。
4. 系统级编排与缓存:RAG的“大脑”与“记忆”
整个RAG系统的编排与不同层级的缓存策略,是实现低延迟和高吞吐的关键。
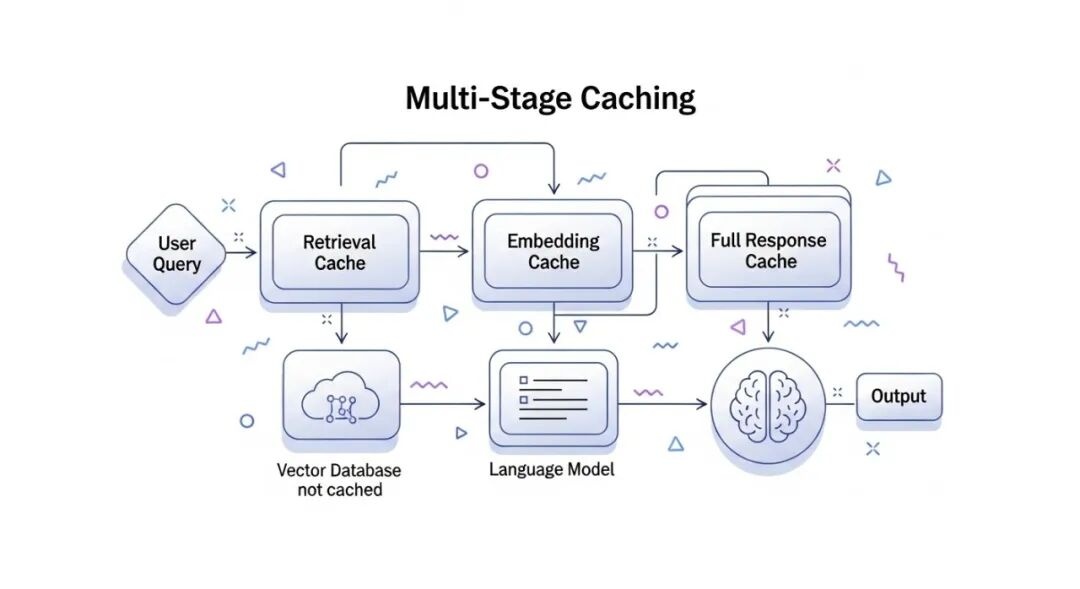
A flowchart illustrating the concept of multi-stage caching within a large-scale RAG system, showing different cache layers like query cache, retrieval cache, embedding cache, and full response cache, and how requests flow through them.
-
• 多级缓存(Multi-level Caching):
-
• 查询-答案缓存(Query-to-Answer Cache): 存储用户完整查询和LLM最终答案的映射。如果完全相同的查询再次出现,直接返回缓存结果。这是最高效的缓存。
-
• 检索结果缓存(Retrieval Cache): 存储查询和召回文档列表的映射。相似的查询可以直接命中缓存,跳过向量检索和Reranking。这可以通过语义哈希或Embedding相似度来判断命中。
-
• Embedding缓存(Embedding Cache): 存储文本块和其Embedding向量的映射。避免重复计算Embedding,尤其是在文档更新不频繁时非常有效。
-
• LLM中间结果缓存: 缓存LLM对特定文档块的总结或关键信息提取结果。
-
-
• 请求路由与负载均衡(Request Routing & Load Balancing):
-
• 智能路由: 根据请求的类型、复杂度或资源需求,将请求路由到不同的RAG服务实例或模型端点。例如,简单查询可以路由到轻量级模型,复杂查询路由到更强大的模型。
-
• 动态负载均衡: 结合RAG服务组件的实时负载和健康状况,动态调整请求分发策略,避免单点过载。
-
-
• 异步与并行处理(Asynchronous & Parallel Processing):
-
• RAG流程中的多个步骤(如关键词检索、向量检索、不同源的数据召回、上下文压缩)可以并行执行,最大化吞吐量。
-
• 使用异步I/O和非阻塞调用,避免等待外部服务(如数据库、模型API)响应。
-
-
• 容错与重试机制(Fault Tolerance & Retries): 在分布式系统中,部分组件的瞬时故障是常态。健全的重试策略和熔断机制能提高系统的健壮性,减少因临时故障导致的延迟。
总结
大规模RAG系统的延迟优化,从来不是一个单一维度的技术问题。它需要我们跳出局部,从整个系统架构的视角去审视和改造。从前置的预处理与智能检索,到中间的上下文精炼与多级缓存,再到后端的模型推理加速与系统级编排,每一个环节都蕴藏着巨大的优化潜力。只有将这些技术有机地结合起来,才能构建出真正低延迟、高吞吐、能稳定支撑生产环境的RAG系统。这不仅是技术挑战,更是工程智慧的体现。
如何学习AI大模型 ?
“最先掌握AI的人,将会比较晚掌握AI的人有竞争优势”。
这句话,放在计算机、互联网、移动互联网的开局时期,都是一样的道理。
我在一线互联网企业工作十余年里,指导过不少同行后辈。帮助很多人得到了学习和成长。
我意识到有很多经验和知识值得分享给大家,故此将并将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。【保证100%免费】🆓
优快云粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传优快云,朋友们如果需要可以扫描下方二维码&点击下方优快云官方认证链接免费领取 【保证100%免费】

读者福利: 👉👉优快云大礼包:《最新AI大模型学习资源包》免费分享 👈👈
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
👉1.大模型入门学习思维导图👈
要学习一门新的技术,作为新手一定要先学习成长路线图,方向不对,努力白费。
对于从来没有接触过AI大模型的同学,我们帮你准备了详细的学习成长路线图&学习规划。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。(全套教程文末领取哈)

👉2.AGI大模型配套视频👈
很多朋友都不喜欢晦涩的文字,我也为大家准备了视频教程,每个章节都是当前板块的精华浓缩。


👉3.大模型实际应用报告合集👈
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(全套教程文末领取哈)

👉4.大模型实战项目&项目源码👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战项目来学习。(全套教程文末领取哈)

👉5.大模型经典学习电子书👈
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。(全套教程文末领取哈)

👉6.大模型面试题&答案👈
截至目前大模型已经超过200个,在大模型纵横的时代,不仅大模型技术越来越卷,就连大模型相关的岗位和面试也开始越来越卷了。为了让大家更容易上车大模型算法赛道,我总结了大模型常考的面试题。(全套教程文末领取哈)

为什么分享这些资料?
只要你是真心想学AI大模型,我这份资料就可以无偿分享给你学习,我国在这方面的相关人才比较紧缺,大模型行业确实也需要更多的有志之士加入进来,我也真心希望帮助大家学好这门技术,如果日后有什么学习上的问题,欢迎找我交流,有技术上面的问题,我是很愿意去帮助大家的!
这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


优快云粉丝独家福利
这份完整版的 AI 大模型学习资料已经上传优快云,朋友们如果需要可以扫描下方二维码&点击下方优快云官方认证链接免费领取 【保证100%免费】
读者福利: 👉👉优快云大礼包:《最新AI大模型学习资源包》免费分享 👈👈

















 5811
5811

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









