






 本文介绍了如何通过Python爬取扇贝单词的接口数据,包括登录、抓包、解密接口的过程,最终成功获取到单词的音频、释义等信息。
本文介绍了如何通过Python爬取扇贝单词的接口数据,包括登录、抓包、解密接口的过程,最终成功获取到单词的音频、释义等信息。
不写一段代码来获取扇贝单词的接口数据
最近想做一个背单词相关的app,要是自己一个个去网站搜然后再复制到数据库中太慢了,所以就考虑能不能通过接口或者python自动将数据爬下来。
第一步,登录并寻找可以爬取的数据(想直接看结论可以到第四步)
首先要先登录去寻找扇贝单词中有显示单词的地方,在我找了一圈,发现在单词学习的词表中(这要先自己提前添加一本词书),只要自己单词还没有开始背,可以在未学单词中来获取本词书的单词数据。

到这未学单词页面,首先就是先查看扇贝单词是通过服务器渲染还是客户端渲染,要是服务器渲染,在源码中就可以直接看到单词的数据,那样就可以直接通过python来进行爬取,要是客户端渲染,那就得考虑通过调用接口来拿取单词数据了。
这里我到源码中去搜索matter这个单词。

结果发现,源码中并没有这个单词的数据,就说明得通过接口的方式来获得数据了。
第二步,对症下药
那此时就是得通过F12的网络检查来进行抓包了。(注意:这里要在Fetch/XHR中才会更清晰的展示)
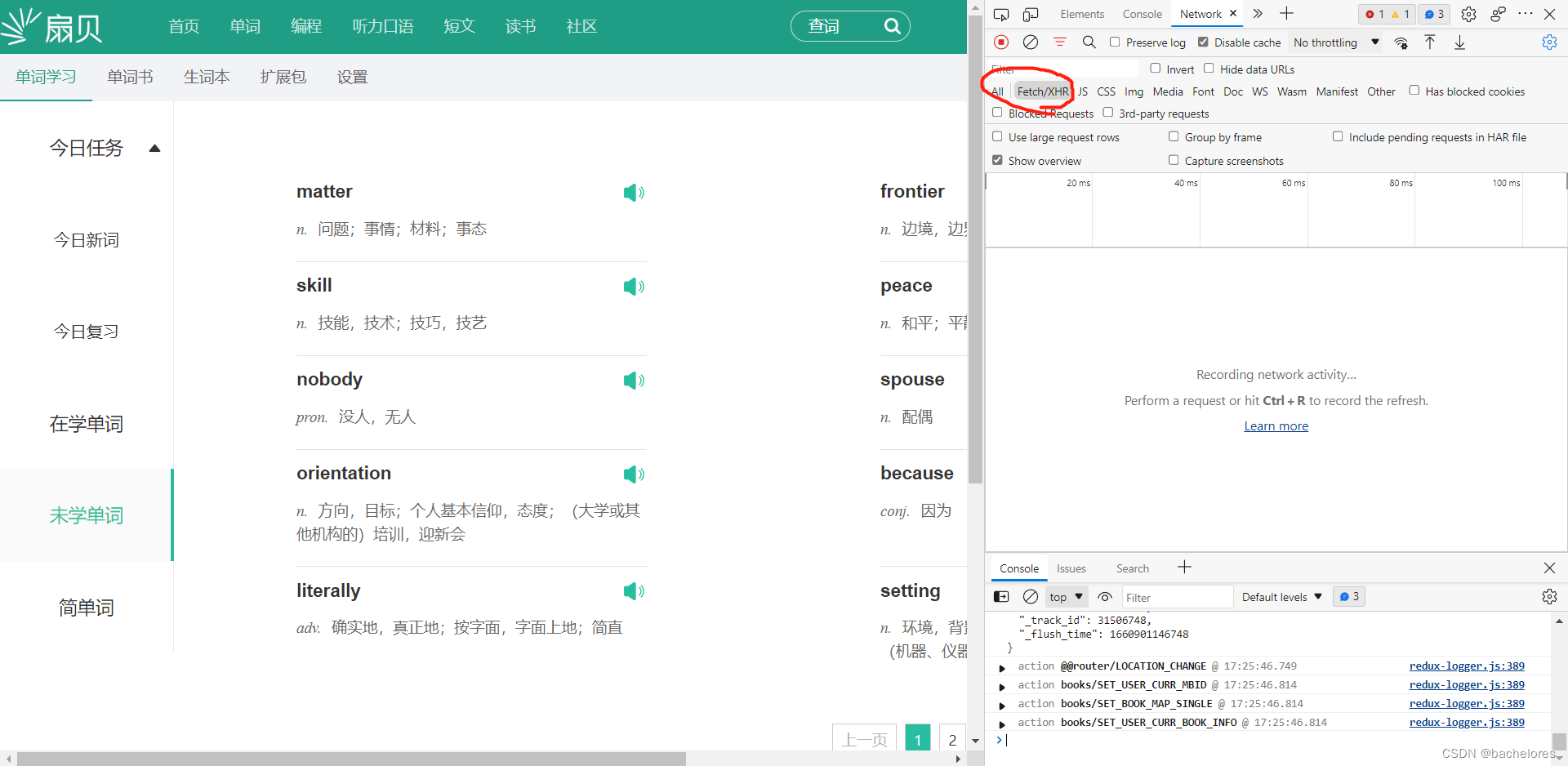
通过下方的按钮,我们转换到第二页,看看发送的网络请求是什么样的。
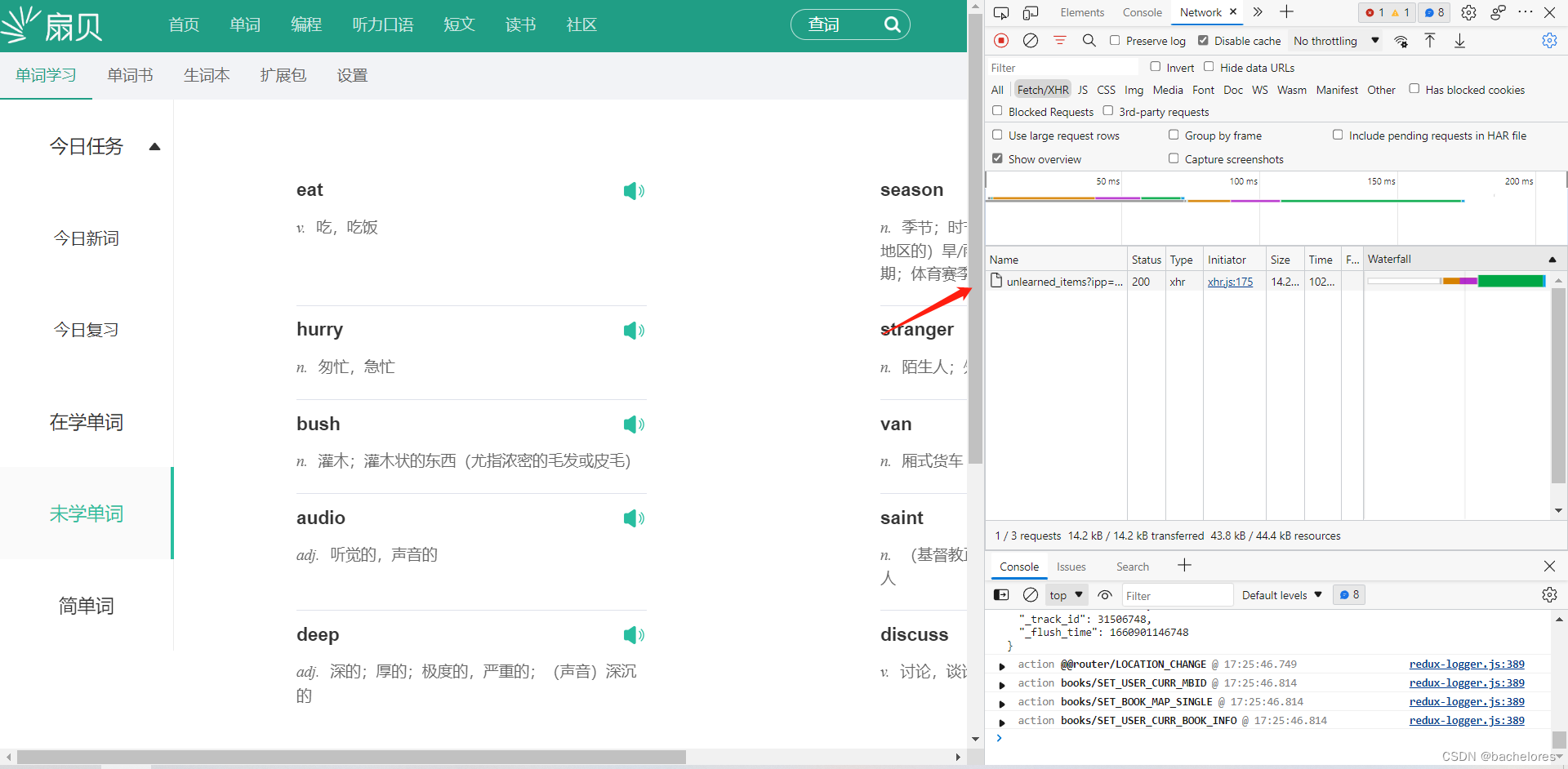
这里我们可以点击后在preview中查看,发现数据是有返回的,但却做了加密。
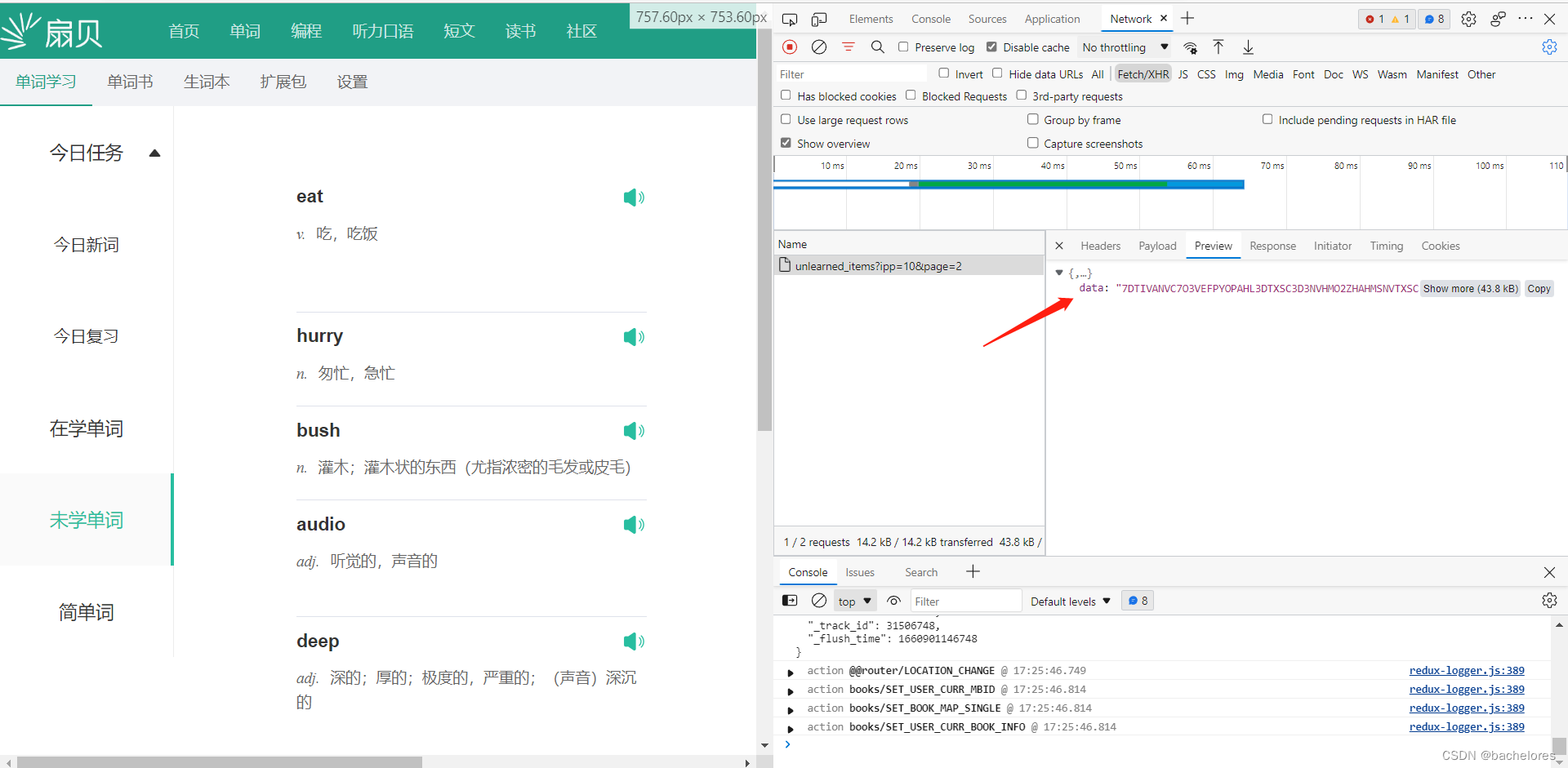
到这一步,接下来的问题也就明确了很多,就是需要来解密他这个数据了。
第三步,解密接口
接下来点击initiator,来查看接口发请求的时候所调用的栈是怎么样的
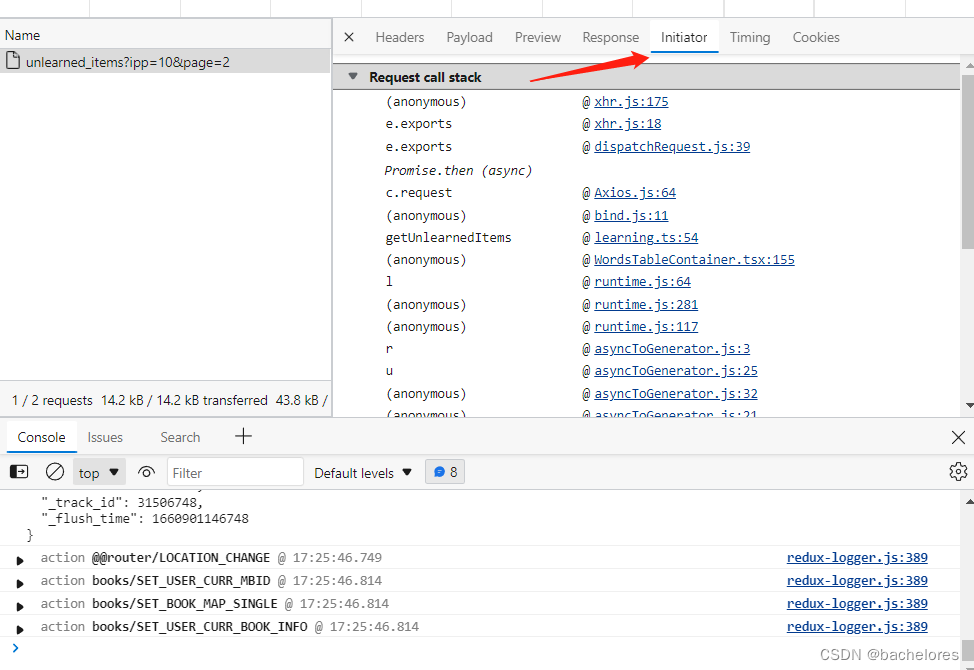
上方图片中蓝色标记的就是调用的文件名,因为我先前已经研究过扇贝的源码了,这里就直接到他接口解密的位置。(即在learning.ts文件)
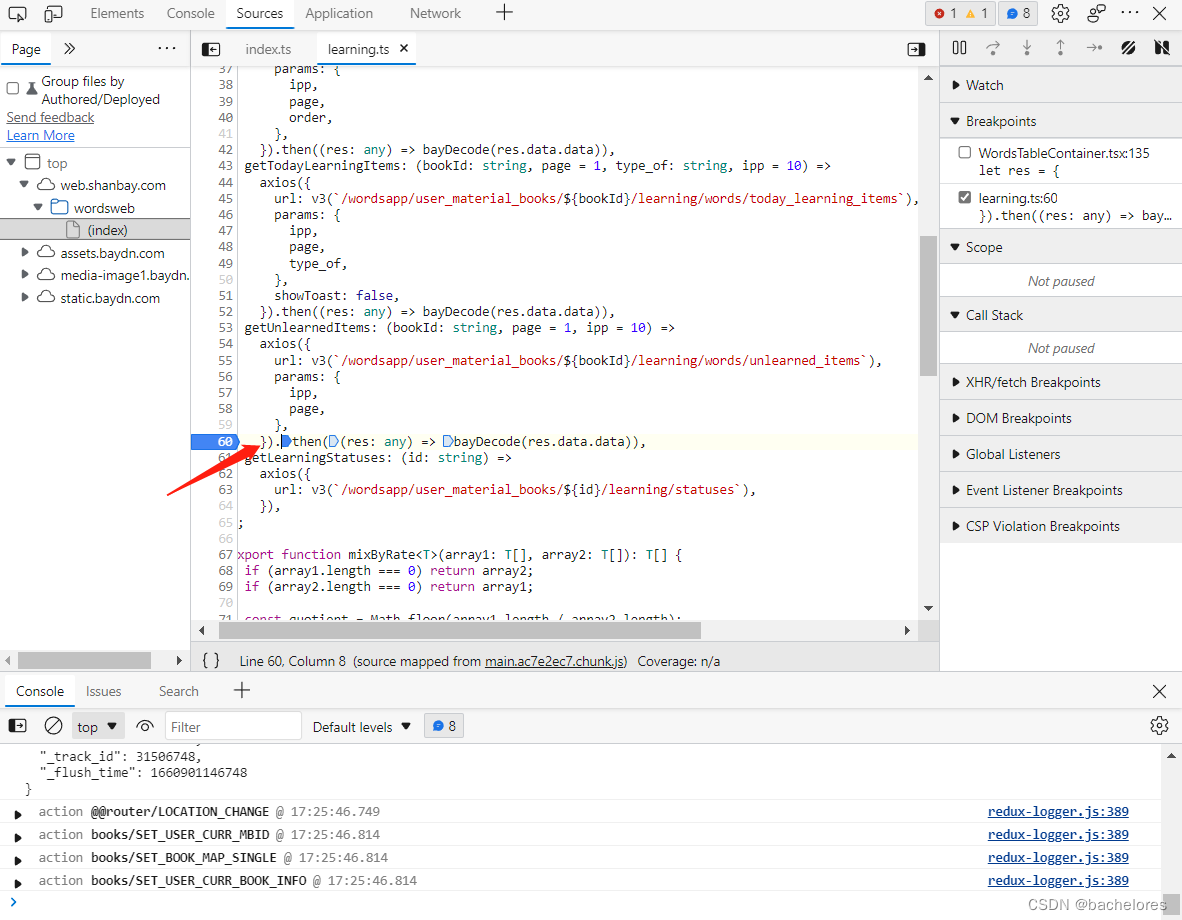
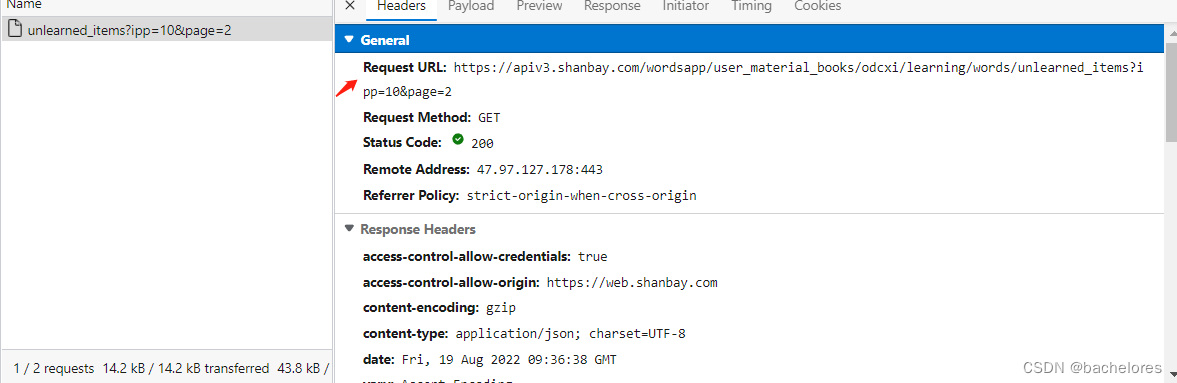
看着代码可以发现,代码发请求的url就是获取单词的url,所以可以断定就是通过了bayDecode来进行了解密(对比url图片在下面)
接下来就需要先去寻找下解密的具体代码到底是什么,这里通过Ctrl+F调出搜索来搜索bayDecode在哪里出现过。
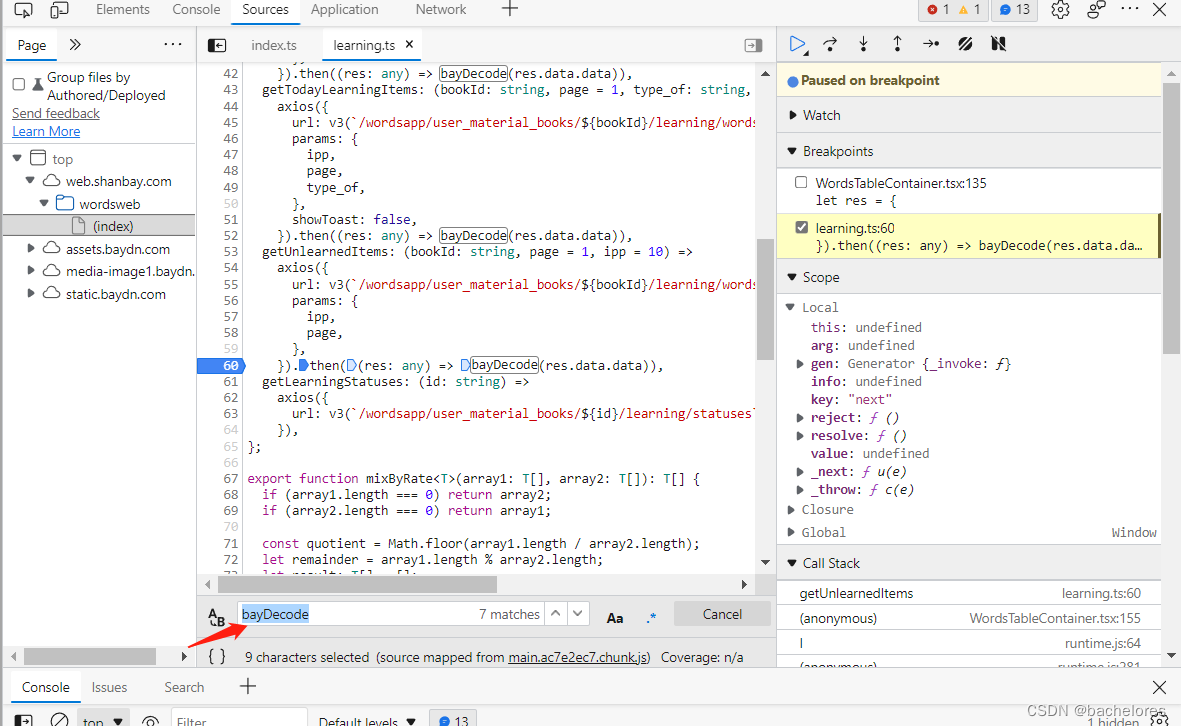
发现bayDecode是从helpers中解构出的一个函数,那接下来就是去寻找helpers文件所在位置了
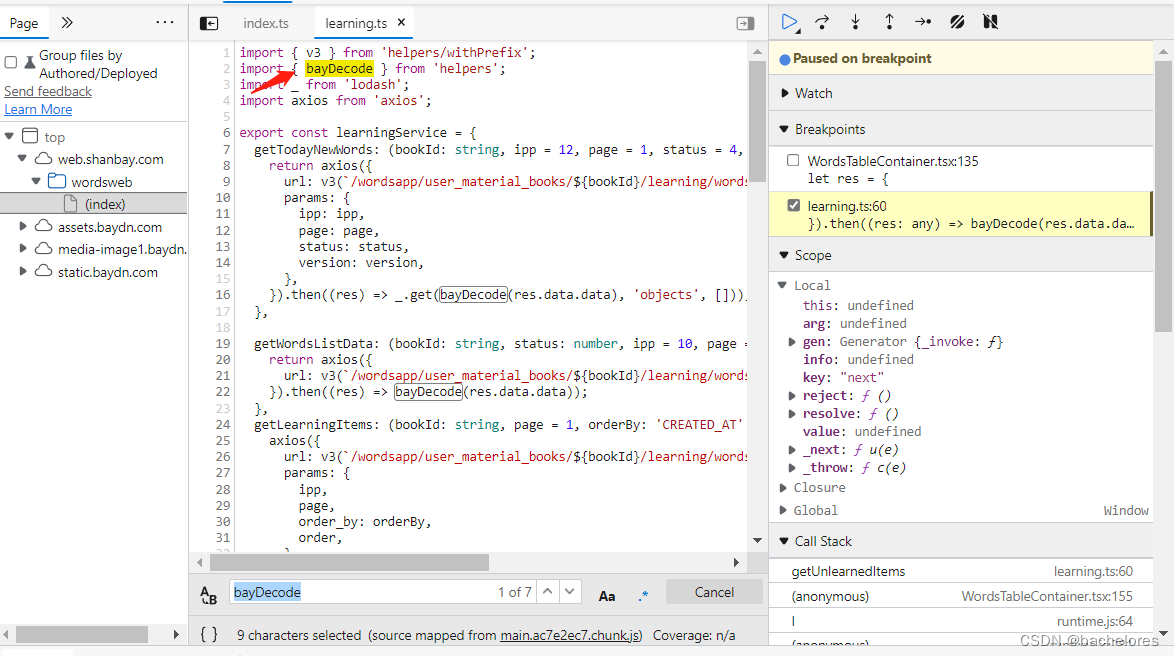
这里我就直接找出来给大家看代码所在位置
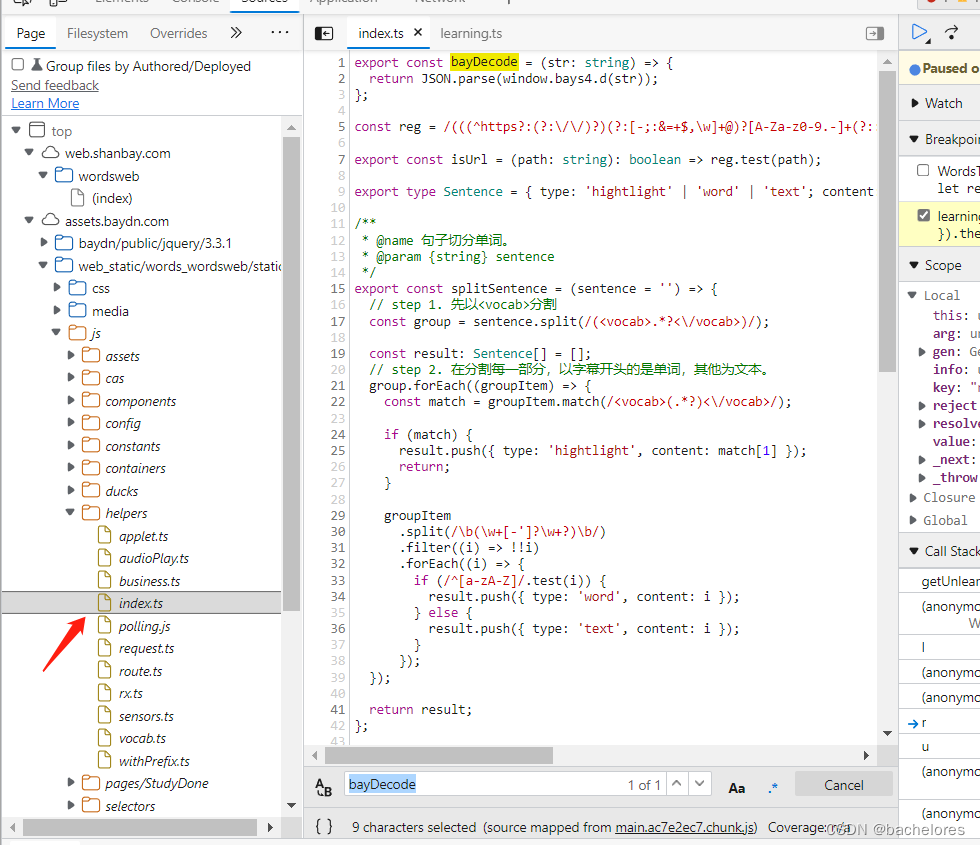
上图可以发现,原来是调用了bays4.d()方法,并且还挂载在了window,那解密我们就可以直接通过别人写好的,直接在控制台中调用bays4.d()来进行解密(这里要是有兴趣也可以使用debug来看扇贝是怎么实现加密的)
第四步,使用现成的方法获取数据
回到发请求的地方,将返回的加密数据Ctrl+C复制
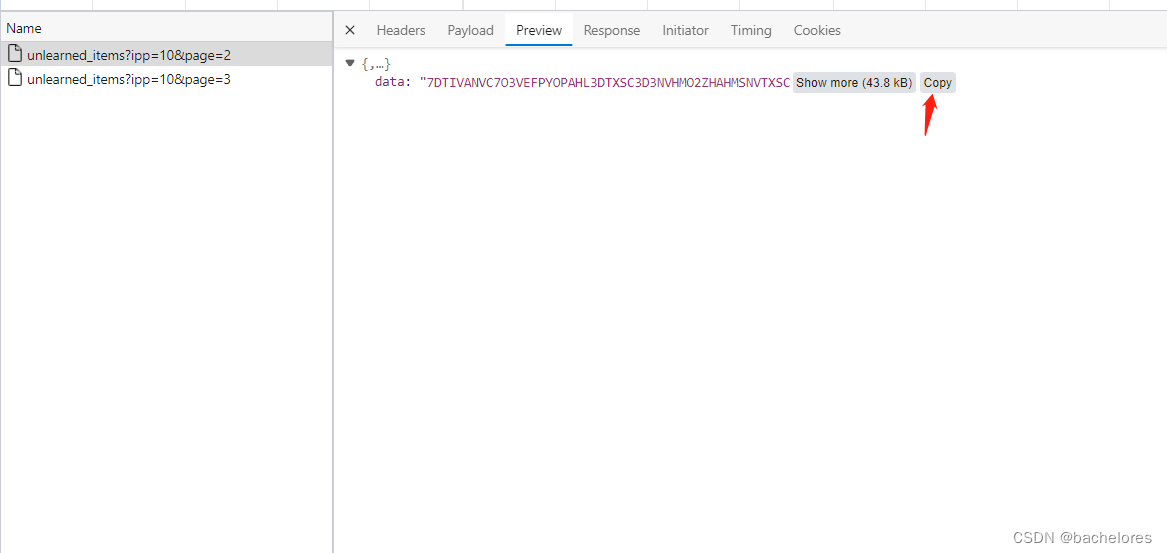
然后到控制台中,直接在控制台调用bays4.d()方法。
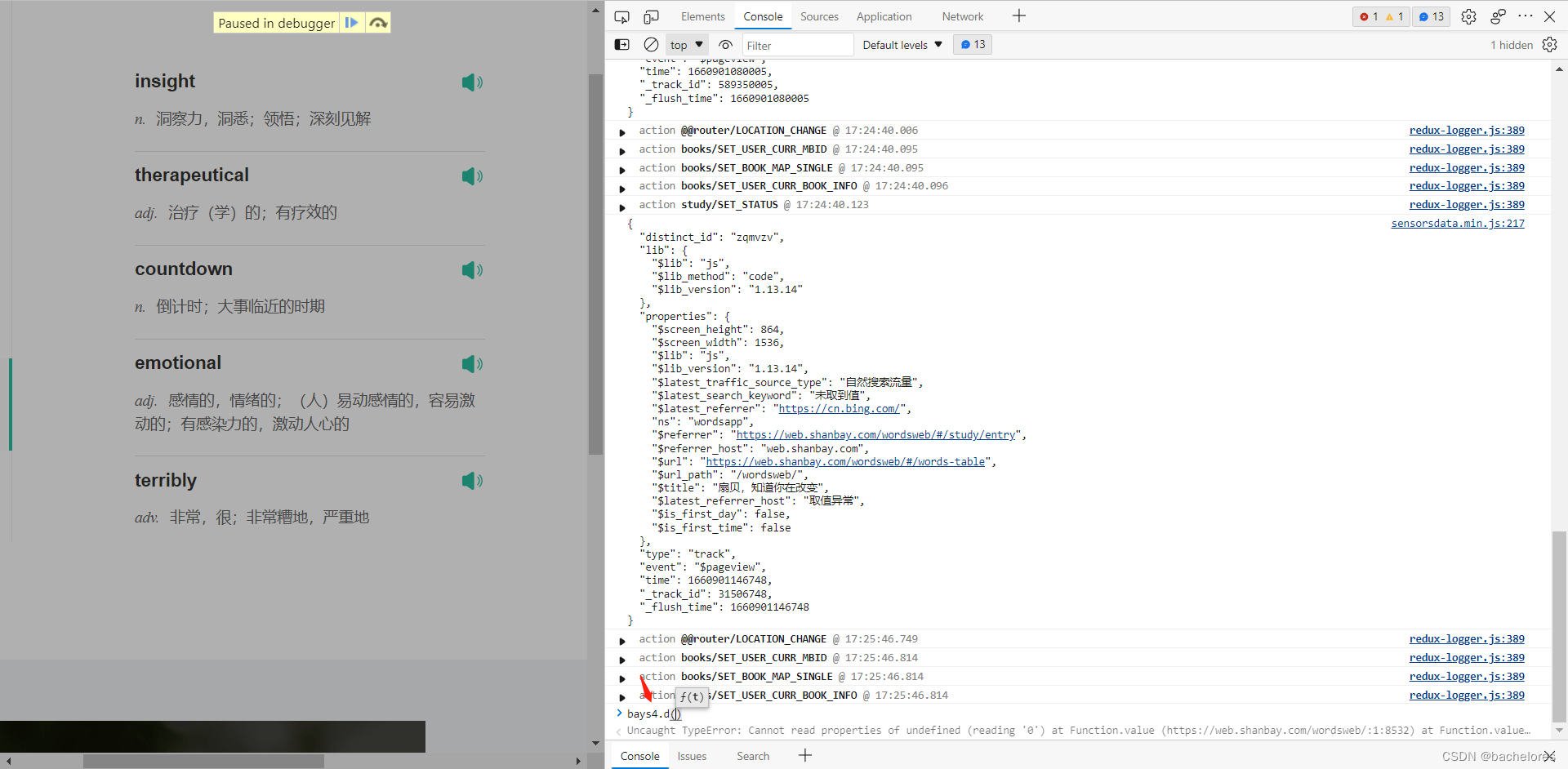
然后将加密的数据直接Ctrl+V粘贴进去,回车一按!

发现接口的数据我们就获取到了,最后再将数据保存到json格式中,使用vscode或其他编译器来查看
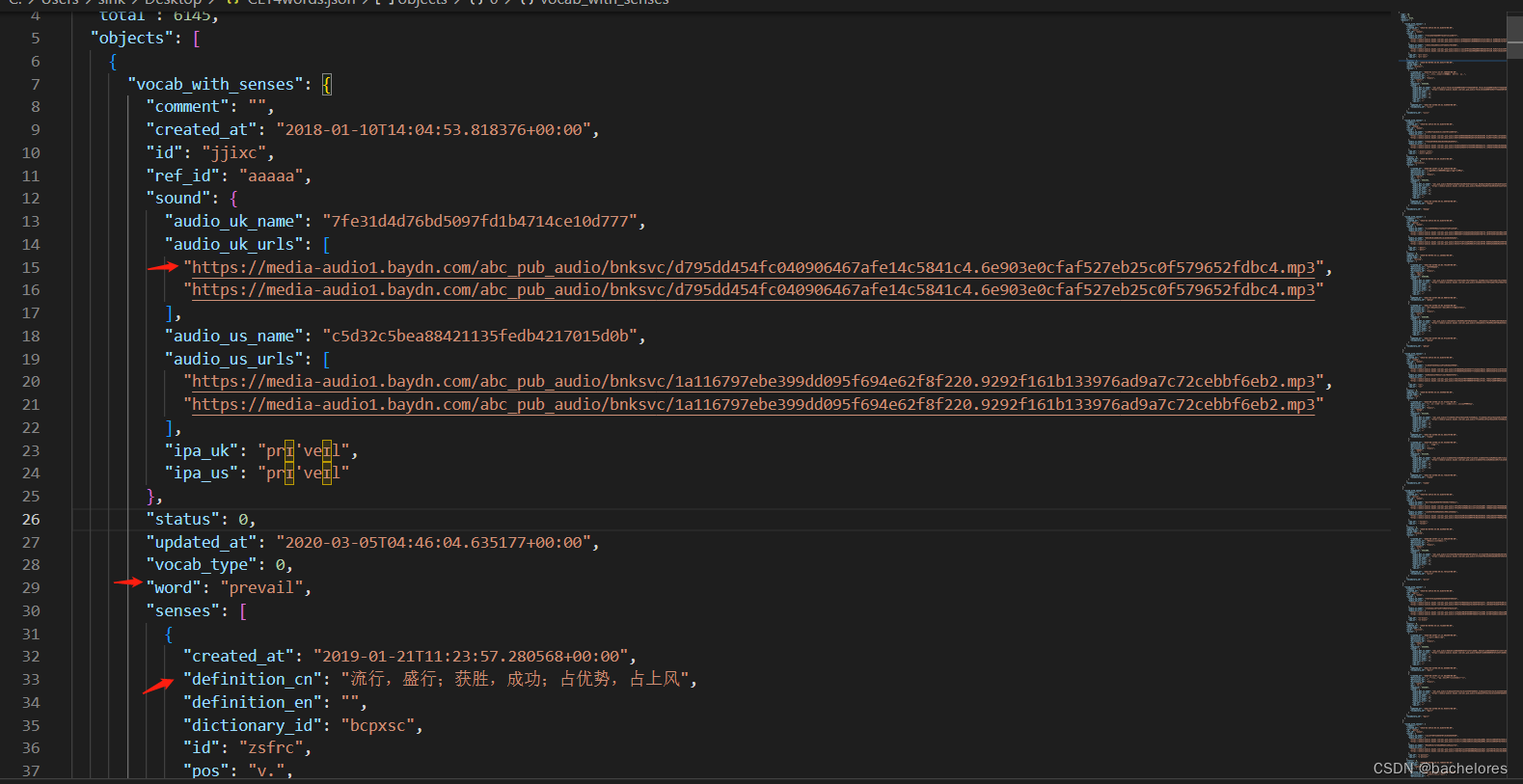
音频,单词,中文释义,轻轻松松获取到。
要是有更好的方法可以留言或者到我的个人博客来与我交流!!!

















 1003
1003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









