







创建线程有哪几种方式?
继承Thread类
继承Thread类,并重写run方法,该run方法的方法体就代表了线程要完成的任务。因此把run()方法称为执行体。创建Thread子类的实例,即创建了线程对象。调用线程对象的start()方法来启动该线程。
实现Runnable接口
定义Runnable接口的实现类,并重写该接口的run()方法,该run()方法的方法体同样是该线程的线程执行体。创建 Runnable实现类的实例,并依此实例作为Thread的target来创建Thread对象,该Thread对象才是真正的线程对象。调用线程对象的start()方法来启动该线程。
通过Callable和Future创建线程
实现Callable接口,并实现call()方法,该call()方法将作为线程执行体,并且有返回值。创建Callable实现类的实例,使用FutureTask类来包装Callable对象,该FutureTask对象封装了该Callable对象的call()方法的返回值。使用FutureTask对象作为Thread对象的target创建并启动新线程。调用FutureTask对象的get()方法来获得子线程执行结束后的返回值。
说一下 Runnable 和 Callable 有什么区别?
(Runnable接口中的run()方法的返回值是void,它做的事情只是纯粹地去执行run()方法中的代码而已;
Callable接口中的call()方法是有返回值的,是一个泛型,和Future、FutureTask配合可以用来获取异步执行的结果。
线程的状态
线程通常都有五种状态,创建、就绪、运行、阻塞和死亡。
创建状态。生成了线程对象,并没有调用该对象的start方法,这是线程处于创建状态。
就绪状态。当调用了线程对象的start方法之后,该线程就进入了就绪状态,但是此时线程调度程序还没有把该线程设置为当前线程,此时处于就绪状态。在线程运行之后,从等待或者睡眠中回来之后,也会处于就绪状态。
运行状态。线程调度程序将处于就绪状态的线程设置为当前线程,此时线程就进入了运行状态,开始运行run函数当中的代码。
阻塞状态。线程正在运行的时候,被暂停,通常是为了等待某个事件的发生(比如说某项资源就绪)之后再继续运行。sleep,suspend,wait等方法都可以导致线程阻塞。
死亡状态。如果一个线程的run方法执行结束或者调用stop方法后,该线程就会死亡。对于已经死亡的线程,无法再使用start方法令其进入就绪.
sleep() 和 wait() 有什么区别
sleep():方法是线程类(Thread)的静态方法,让调用线程进入睡眠状态,让出执行机会给其他线程,等到休眠时间结束后,线程进入就绪状态和其他线程一起竞争cpu的执行时间。因为sleep() 是static静态的方法,他不能改变对象的锁,当一个synchronized块中调用了sleep() 方法,线程虽然进入休眠,但是对象的锁并没有被释放,其他线程依然无法访问这个对象。
wait():是Object类的方法,当一个线程执行到wait方法时,它就进入到一个和该对象相关的等待池,同时释放对象的锁,使得其他线程能够访问,可以通过notify,notifyAll方法来唤醒等待的线程
notify()和 notifyAll()有什么区别?
如果线程调用了对象的 wait()方法,那么线程便会处于该对象的等待池中,等待池中的线程不会去竞争该对象的锁。
当有线程调用了对象的 notifyAll()方法(唤醒所有 wait 线程)或 notify()方法(只随机唤醒一个 wait 线程),被唤醒的的线程便会进入该对象的锁池中,锁池中的线程会去竞争该对象锁。也就是说,调用了notify后只要一个线程会由等待池进入锁池,而notifyAll会将该对象等待池内的所有线程移动到锁池中,等待锁竞争。
优先级高的线程竞争到对象锁的概率大,假若某线程没有竞争到该对象锁,它还会留在锁池中,唯有线程再次调用 wait()方法,它才会重新回到等待池中。而竞争到对象锁的线程则继续往下执行,直到执行完了 synchronized 代码块,它会释放掉该对象锁,这时锁池中的线程会继续竞争该对象锁。
线程的 run()和 start()有什么区别?
调用 start() 方法是用来启动线程的,轮到该线程执行时,会自动调用 run();直接调用 run() 方法,无法达到启动多线程的目的,相当于主线程线性执行 Thread 对象的 run() 方法。
一个线程对象的 start() 方法只能调用一次,多次调用会抛出 java.lang.IllegalThreadStateException 异常;run() 方法没有限制。
每个线程都是通过某个特定Thread对象所对应的方法run()来完成其操作的,方法run()称为线程体。通过调用Thread类的start()方法来启动一个线程。
start()方法来启动一个线程,真正实现了多线程运行。这时无需等待run方法体代码执行完毕,可以直接继续执行下面的代码; 这时此线程是处于就绪状态, 并没有运行。 然后通过此Thread类调用方法run()来完成其运行状态, 这里方法run()称为线程体,它包含了要执行的这个线程的内容, Run方法运行结束, 此线程终止。然后CPU再调度其它线程。
run()方法是在本线程里的,只是线程里的一个函数,而不是多线程的。 如果直接调用run(),其实就相当于是调用了一个普通函数而已,直接待用run()方法必须等待run()方法执行完毕才能执行下面的代码,所以执行路径还是只有一条,根本就没有线程的特征,所以在多线程执行时要使用start()方法而不是run()方法。
创建线程池有哪几种方式
①. newFixedThreadPool(int nThreads)
创建一个固定长度的线程池,每当提交一个任务就创建一个线程,直到达到线程池的最大数量,这时线程规模将不再变化,当线程发生未预期的错误而结束时,线程池会补充一个新的线程。
②. newCachedThreadPool()
创建一个可缓存的线程池,如果线程池的规模超过了处理需求,将自动回收空闲线程,而当需求增加时,则可以自动添加新线程,线程池的规模不存在任何限制。
③. newSingleThreadExecutor()
这是一个单线程的Executor,它创建单个工作线程来执行任务,如果这个线程异常结束,会创建一个新的来替代它;它的特点是能确保依照任务在队列中的顺序来串行执行。
④. newScheduledThreadPool(int corePoolSize)
创建了一个固定长度的线程池,而且以延迟或定时的方式来执行任务,类似于Timer。
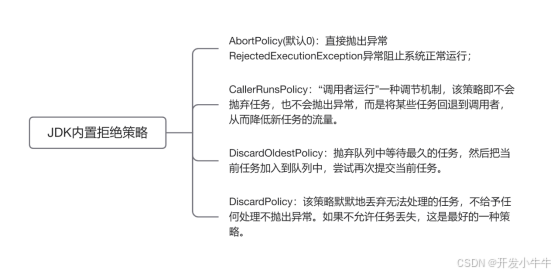
线程的拒绝策略
当线程池已经关闭或达到饱和(最大线程和队列都已满)状态时,新提交的任务将会被拒绝。
ThreadPoolExecutor 定义了四种拒绝策略:
AbortPolicy
默认策略,在需要拒绝任务时抛出RejectedExecutionException
CallerRunsPolicy
直接在 execute 方法的调用线程中运行被拒绝的任务,如果线程池已经关闭,任务将被丢弃。
DiscardPolicy
直接丢弃任务。
DiscardOldestPolicy
丢弃队列中等待时间最长的任务,并执行当前提交的任务,如果线程池已经关闭,任务将被丢弃。
自定义拒绝策略
我们也可以自定义拒绝策略,只需要实现 RejectedExecutionHandler; 需要注意的是,拒绝策略的运行需要指定线程池和队列的容量。
ThreadPoolExecutor创建线程方式
通过下面的demo来了解ThreadPoolExecutor创建线程的过程。
package com.bruce.demo7;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.TimeUnit;
public class ThreadPoolSerialTest {
public static void main(String[] args) {
//核心线程数
int corePoolSize = 3;
//最大线程数
int maximumPoolSize = 6;
//超过 corePoolSize 线程数量的线程最大空闲时间
long keepAliveTime = 2;
//以秒为时间单位
TimeUnit unit = TimeUnit.SECONDS;
//创建工作队列,用于存放提交的等待执行得任务
BlockingQueue<Runnable> workQueue = new ArrayBlockingQueue<Runnable>(2);
ThreadPoolExecutor threadPoolExecutor = null;
try {
//创建线程池
threadPoolExecutor = new ThreadPoolExecutor(corePoolSize,
maximumPoolSize,
keepAliveTime,
unit,
workQueue,
new ThreadPoolExecutor.AbortPolicy());
//循环提交任务
for (int i = 0; i < 8; i++) {
//提交任务的索引
int index = (i + 1);
threadPoolExecutor.submit(() -> {
//线程打印输出
System.out.println("大家好,我是线程:" + index);
try {
//模拟线程执行时间,10s
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
//每个任务提交后休眠500ms再提交下一个任务,用于保证提交顺序
Thread.sleep(500);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
}
}
}
大家好,我是线程:1
大家好,我是线程:2
大家好,我是线程:3
大家好,我是线程:6
大家好,我是线程:7
大家好,我是线程:8
大家好,我是线程:4
大家好,我是线程:5
执行流程:
首先通过 ThreadPoolExecutor 构造函数创建线程池;
执行 for 循环,提交 8 个任务(恰好等于maximumPoolSize[最大线程数] + capacity[队列大小]);
通过 threadPoolExecutor.submit 提交 Runnable 接口实现的执行任务;
提交第1个任务时,由于当前线程池中正在执行的任务为 0 ,小于 3(corePoolSize 指定),所以会创建一个线程用来执行提交的任务1;
提交第 2, 3 个任务的时候,由于当前线程池中正在执行的任务数量小于等于 3 (corePoolSize 指定),所以会为每一个提交的任务创建一个线程来执行任务;
当提交第4个任务的时候,由于当前正在执行的任务数量为 3 (因为每个线程任务执行时间为10s,所以提交第4个任务的时候,前面3个线程都还在执行中),此时会将第4个任务存放到 workQueue 队列中等待执行;
由于 workQueue 队列的大小为 2 ,所以该队列中也就只能保存 2 个等待执行的任务,所以第5个任务也会保存到任务队列中;
当提交第6个任务的时候,因为当前线程池正在执行的任务数量为3,workQueue 队列中存储的任务数量也满了,这时会判断当前线程池中正在执行的任务的数量是否小于6(maximumPoolSize指定);
如果小于 6 ,那么就会新创建一个线程来执行提交的任务 6;
执行第7,8个任务的时候,也要判断当前线程池中正在执行的任务数是否小于6(maximumPoolSize指定),如果小于6,那么也会立即新建线程来执行这些提交的任务;
此时,6个任务都已经提交完毕,那 workQueue 队列中的等待 任务4 和 任务5 什么时候执行呢?
当任务1执行完毕后(10s后),执行任务1的线程并没有被销毁掉,而是获取 workQueue 中的任务4来执行;
当任务2执行完毕后,执行任务2的线程也没有被销毁,而是获取 workQueue 中的任务5来执行;
通过上面流程的分析,也就知道了之前案例的输出结果的原因。其实,线程池中会线程执行完毕后,并不会被立刻销毁,线程池中会保留 corePoolSize 数量的线程,当 workQueue 队列中存在任务或者有新提交任务时,那么会通过线程池中已有的线程来执行任务,避免了频繁的线程创建与销毁,而大于 corePoolSize 小于等于 maximumPoolSize 创建的线程,则会在空闲指定时间(keepAliveTime)后进行回收。


















 14万+
14万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











