




在java中,volatile有如下作用,一个是禁止指令重排序(编译时指令重排序 和 CPU乱序执行)。另一个是保证多线程共享变量的内存可见性。为了讲解volatile时如何禁止指令重排序,防止CPU乱序执行,以及保证变量内存可见性。首先我们需要了解这些概念,即什么是编译时指令重排序?为什么要指令重排序?为什么CPU会乱序执行?什么是内存可见性?之后,最后来看volatile到底是如何实现的,以及它是如何实现这些功能的。
1 编译时指令重排序
在编译阶段,编译器能够对很 大一个范围的代码进行分析,能够从更大的范围内分辨出可以并发的指令,并将其尽量靠近排列让处理器更容易预取和并发执行,充分利用处理器的乱序并发功能。 所以现代的高性能编译器在目标码优化上都具备对指令进行乱序优化的能力。并且可以对访存的指令进行进一步的乱序,减少逻辑上不必要的访存,以及尽量提高 Cache命中率和CPU的LSU(load/store unit)的工作效率。所以在打开编译器优化以后,看到生成的汇编码并不严格按照代码的逻辑顺序是正常的。和处理器一样,如果想要告诉编译器不要去对某些 指令乱序优化,也要通过一些方式来告诉编译器。通常可以通过volatile关键字来告诉编译器对哪些变量的访问操作不能进行重排序优化。
2 CPU乱序执行
即使在编译阶段,编译生成的指令是顺序的。在CPU执行指令的时候,也会存在乱序执行的问题,其中造成乱序执行的一个原因,得从CPU的指令流水技术说起。关于指令流水,详细的可以去看 CPU的结构和功能——指令流水及中断系统,下面简单介绍一下指令流水:
一条指令在执行的时候,会分为很多个周期,如:取指周期,间址周期,执行周期,中断周期等等。首先我们假设指令的执行分为取指周期和执行周期两个阶段,如果指令串行执行:

上图的执行过程是完全的串行操作,一条指令解释过程执行结果以后,再开始下一条指令的开始过程,那么实际上,如果我们再控制器实现过程中把取指部件和执行部件完全的独立开进行设计的话,那么在取指阶段只会用到取指令部件,那么执行指令阶段我们只会用到执行指令部件,这样的话,当上图中第二条指令的取指令部件运行的时候,其执行指令部件是空闲的。如果我们采用这种结果这种方式去解释一条指令的话,总有一个部件是空闲的,控制器的利用率非常低。
为了加快指令执行速度,充分利用CPU,就就会采用流水线的方式去执行指令:
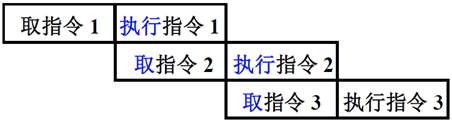
上图为指令二级流水, 取指和执行在时间上是重叠的,使得取指部件和执行部件都都得到了充分的利用。整个指令周期就会减半,理想情况下速度会提升一倍,但只是理想情况,下面看看影响指令流水效率加倍的因素。这只是一个指令二级流水,如果是指令六级流水,效率提升的就更大:
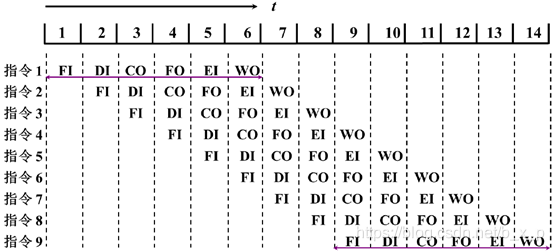
上图是一个六级流水线,横轴表示时间,纵轴表示指令,这个流水线被分成了六级,这六级的功能分别是:取指令,指令译码,形成操作数地址,取操作数,执行,结果的写回,所谓结果的写回是指把运算结果写回到指令的寄存器中,或者是写回到给定的内存单元中。
上图中一共给出了9条指令,假设六级流水线每段时间都是相同的,这样的话,我们采用串行方式完成一条指令,一条指令就需要6个时间单位,9条指令就需要54个时间单位。如果采用流水线方式只是用了14个时间单位,当然是假设9条指令不冲突并且没有条件转移指令的情况下。
在流水线的基础上,对指令的解释速度进一步提高的方法。前面讲解的是用一条流水线如何提高指令的解释速度,利用这个思路,尽心进一步的扩展,如果我们使用多条流水线,有几条指令同时进入到不同的流水线中进行解释,这样的话速度会被进一步的提高。这种方法就是超标量技术。
超标量技术就是每个时钟周期内,多条独立指令进入到不同的流水线中执行。需要配置多条流水线,多个功能部件。
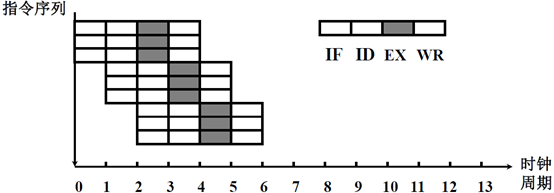
如上图中,有三条流水线,在每个时钟周期,可以有三条独立的指令分别进入每一个流水线执行,这样,指令的解释速度和用一条流水线相比,最高加速比可以达到三倍。利用这种方法,通常情况下可以在执行当中不去调整指令的执行顺序,指令的执行顺序在编译过程中采用优化技术,把多条可以并行执行的,独立的指令挑选出来,搭配起来,让他们同时进入到三条流水线执行,这种方法就是超标量的方法。
有了超标量技术,在一个指令周期内能并发执行多条指令,处理器从Cache预取了一批指令后,就会分析找出那些互相没有关联可以并发执行的指令,然后送到几个独立的执行单元进行并发执行。就有可能将多条无关联指令分别送到两个算术单元去同时执行。
通常来说访存指令(由LSU单元执行)所需要的指令周期可能很多(可能要几十甚至上百个周期),而一般的算术指令通常在一个指令周期就搞定。所以有的可能代码中的访存指令耗费了多个周期完成执行后,其他几个执行单元可能已经把后面有多条逻辑上无关的算术指令都执行完了,这就产生了乱序。
另外访存指令之间也存在乱序的问题。高级的CPU可以根据自己Cache的组织特性,将访存指令重新排序执行。访问一些连续地址的可能会先执行,因为这时候Cache命中率高。有的还允许访存的Non-blocking,即如果前面一条访存指令因为Cache不命中,造成长延时的存储访问时,后面的 访存指令可以先执行以便从Cache取数。这也就造成了指令乱序执行的问题。
当然,不是所有的指令,CPU都能对其进行乱序优化,对于前后存在依赖关系的指令,CPU是不能改变其执行次序的。
3 内存可见性
内存可见性,简单说就是,当有多个CPU(多线程)共享内存的时候,当一个线程对内存中的变了做了修改,而另一个线程中不能够立即知道这种修改。为什么会出现这种情况,就需要从硬件层面开始说起。
3.1 CPU高速缓存
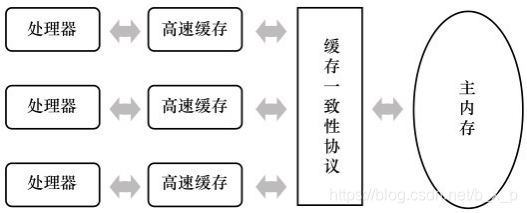
我们都知道,CPU在执行指令的时候,需要访存操作,需要与内存交互,如读取运算数据、存储运算结果等,这个I/O操作是很难消除的(无法仅靠寄存器来完成所有运算任务)。由于计算机的存储设备与处理器的运算速度有几个数量级的差距,所以现代计算机系统都不得不加入一层读写速度尽可能接近处理器运算速度的高速缓存(Cache)来作为内存与处理器之间的缓冲:将运算需要使用到的数据复制到缓存中,让运算能快速进行,当运算结束后再从缓存同步回内存之中,这样处理器就无须等待缓慢的内存读写了。
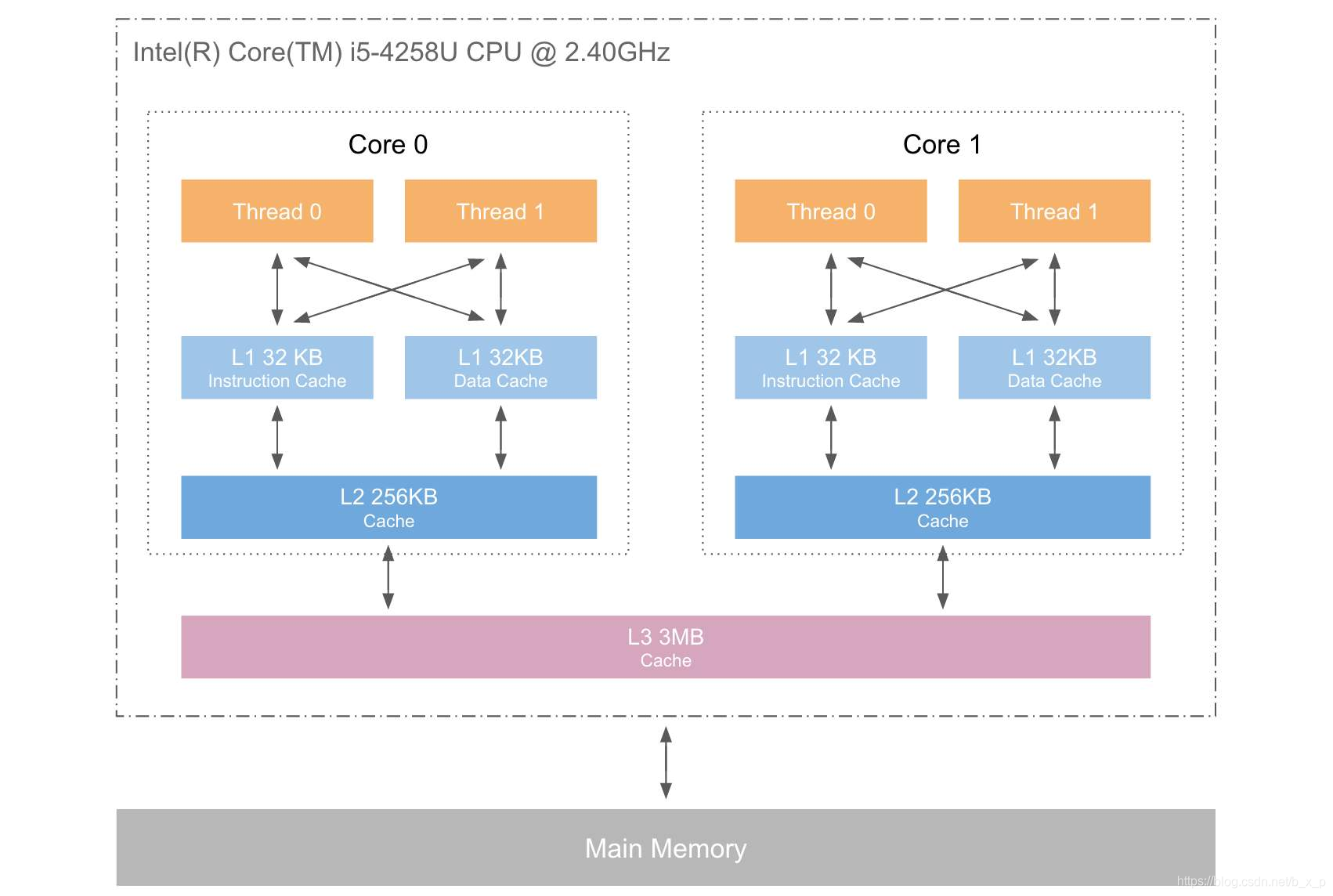
3.2 缓存一致性问题
基于高速缓存的存储交互很好地解决了处理器与内存的速度矛盾,但是也为计算机系统带来更高的复杂度,因为它引入了一个新的问题:缓存一致性(Cache Coherence)。在多处理器系统中,每个处理器都有自己的高速缓存,而它们又共享同一主内存(Main Memory),如上图所示。当多个处理器的运算任务都涉及同一块主内存区域时,将可能导致各自的缓存数据不一致,如果真的发生这种情况,那同步回到主内存时以谁的缓存数据为准呢?这就是缓存不一致的问题。
3.3 总线锁
为了解决多CPU共享内存时,保证多个CPU的缓存数据的一致性,最初,操作系统采用总线锁的机制。CPU和内存之间的通过总线连接通信,所谓总线锁,就是当一个CPU通过总线访问内存的时候,其在总线上发出一个LOCK#信号,标志其独占总线,即独占内存,其他处理器就不能通过总线读写内存,也就是阻塞了其他CPU的访存操作,使该处理器可以独享此共享内存。
3.4 缓存一致性协议
总线锁确实能解决缓存不一致的问题,但是缺点也很明显,总线锁定把CPU和内存的通信给锁住了,使得在锁定期间,其他处理器不能操作其他内存地址的数据,严重的降低了CPU和内存的利用率,所以后来的CPU都提供了缓存一致性机制,如MESI协议。
MESI代表了缓存行的四种状态,CPU中每个缓存行(caceh line)使用额外的两位(bit)表示当前缓存行处于哪种状态。
M: 被修改(Modified)
该缓存行只被缓存在该CPU的缓存中,并且是被修改过的(dirty),即与主存中的数据不一致,该缓存行中的内容需要在未来的某个时间点(允许其它CPU读取主存中相应内存之前)写回(write back)主存。当被写回主存之后,该缓存行的状态会变成独享(exclusive)状态。
E: 独享的(Exclusive)
该缓存行只被缓存在该CPU的缓存中,它是未被修改过的(clean),与主存中数据一致。该状态可以在任何时刻当有其它CPU读取该内存时变成共享状态(shared)。同样地,当CPU修改该缓存行中内容时,该状态可以变成Modified状态。
S: 共享的(Shared)
该状态意味着该缓存行可能被多个CPU缓存,并且各个缓存中的数据与主存数据一致(clean),当有一个CPU修改该缓存行中,其它CPU中该缓存行可以被作废(变成无效状态(Invalid))。
I: 无效的(Invalid)
该缓存是无效的(可能有其它CPU修改了该缓存行)。
至于MESI状态转换:
在MESI协议中,每个Cache的Cache控制器不仅知道自己的读写操作,而且也监听(snoop)其它Cache的读写操作。每个Cache line所处的状态根据本核和其它核的读写操作在4个状态间进行迁移。
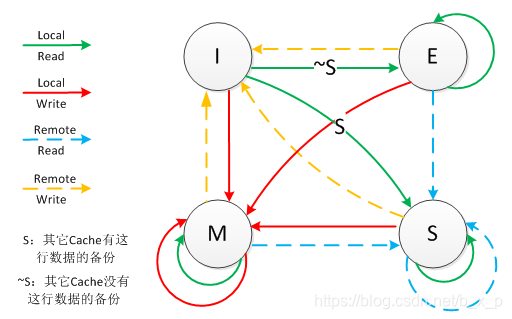
Local Read:表示本内核读本Cache中的值
Local Write:表示本内核写本Cache中的值
Remote Read:表示其它内核读其Cache中的值
Remote Write:表示其它内核写其Cache中的值
箭头表示本Cache line状态的迁移,环形箭头表示状态不变。
当内核需要访问的数据不在本Cache中,而其它Cache有这份数据的备份时,本Cache既可以从内存中导入数据,也可以从其它Cache中导入数据,不同的处理器会有不同的选择。MESI协议为了使自己更加通用,没有定义这些细节,只定义了状态之间的迁移,下面的描述假设本Cache从内存中导入数据。
| 当前状态 | 事件 | 行为 | 下一个状态 |
|---|---|---|---|
| I(Invalid) | Local Read | 如果其它Cache没有这份数据,本Cache从内存中取数据,Cache line状态变成E; 如果其它Cache有这份数据,且状态为M,则将数据更新到内存,本Cache再从内存中取数据,2个Cache 的Cache line状态都变成S; 如果其它Cache有这份数据,且状态为S或者E,本Cache从内存中取数据,这些Cache 的Cache line状态都变成S |
E/S |
| Local Write | 从内存中取数据,在Cache中修改,状态变成M; 如果其它Cache有这份数据,且状态为M,则要先将数据更新到内存,然后本地写之前需要先从内存中取最新数据; 如果其它Cache有这份数据,本地写成功后,需要将其它Cache的Cache line状态变成I |
M | |
| Remote Read | 既然是Invalid,别的核的操作与它无关 | I | |
| Remote Write | 既然是Invalid,别的核的操作与它无关 | I | |
| E(Exclusive) | Local Read | 从Cache中取数据,状态不变 | E |
| Local Write | 修改Cache中的数据,状态变成M | M | |
| Remote Read | 数据和其它核共用,状态变成了S | S | |
| Remote Write | 数据被修改,本Cache line不能再使用,状态变成I | I | |
| S(Shared) | Local Read | 从Cache中取数据,状态不变 | S |
| Local Write | 修改Cache中的数据,状态变成M; 其它核共享的Cache line状态变成I |
M | |
| Remote Read | 状态不变 | S | |
| Remote Write | 数据被修改,本Cache line不能再使用,状态变成I | I | |
| M(Modified) | Local Read | 从Cache中取数据,状态不变 | M |
| Local Write | 修改Cache中的数据,状态不变 | M | |
| Remote Read | 这行数据被写到内存中,使其它核能使用到最新的数据,状态变成S | S | |
| Remote Write | 这行数据被写到内存中,使其它核能使用到最新的数据,由于其它核会修改这行数据,状态变成I | I |
3.5 store buffer
说了缓存一致性协议,好像就能够解决问题了,但是,在这里你会发现,又有新的问题出现了。MESI协议中:当cpu0写数据到本地cache的时候,如果不是M或者E状态,需要发送一个invalidate消息给cpu1,只有收到cpu1的ack之后cpu0才能继续执行,在这个过程中cpu0需要等待,这大大影响了性能。于是CPU设计者引入了store buffer,这个buffer处于CPU与cache之间。
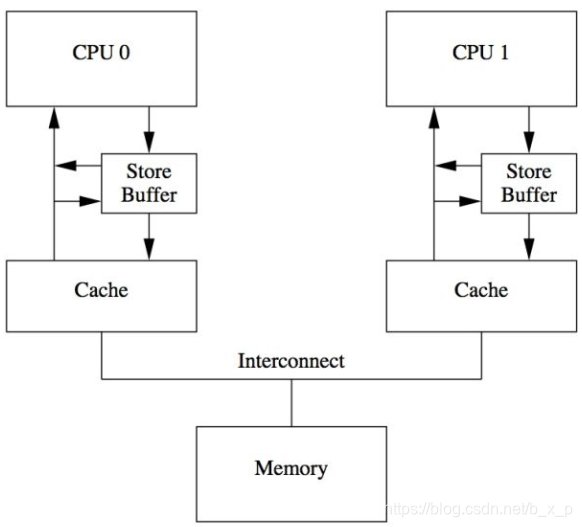
在cpu和cac
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 170万+
170万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









